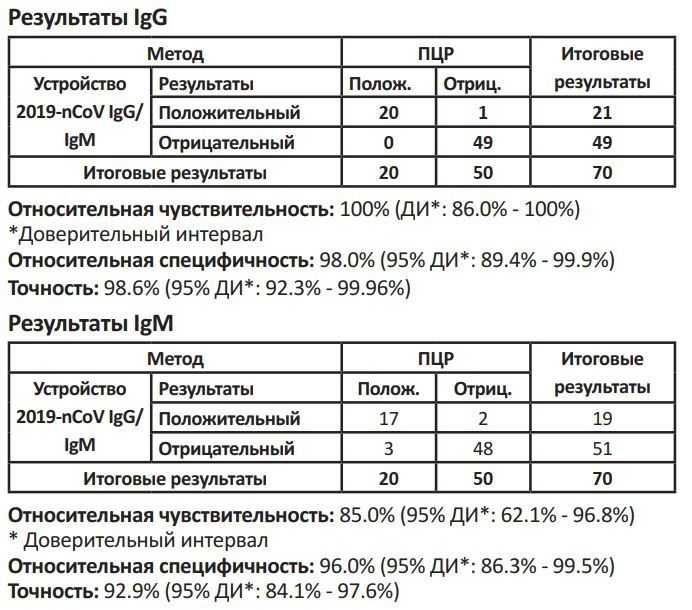
нижний индекс выходит за пределы
Одна распространенная ошибка, с которой вы можете столкнуться в R:
Error in x[, 4] : subscript out of bounds
Эта ошибка возникает при попытке доступа к столбцу или строке несуществующей матрицы.
В этом руководстве представлены точные шаги, которые вы можете использовать для устранения этой ошибки, используя следующую матрицу в качестве примера:
#make this example reproducible set. seed (0) #create matrix with 10 rows and 3 columns x = matrix(data = sample. int (100, 30), nrow = 10, ncol = 3) #print matrix print(x) [,1] [,2] [,3] [1,] 14 51 96 [2,] 68 85 44 [3,] 39 21 33 [4,] 1 54 35 [5,] 34 74 70 [6,] 87 7 86 [7,] 43 73 42 [8,] 100 79 38 [9,] 82 37 20 [10,] 59 92 28Пример №1: нижний индекс выходит за пределы (со строками)
Следующий код пытается получить доступ к 11-й строке матрицы, которой не существует:
#attempt to display 11th row of matrix x[11, ] Error in x[11, ] : subscript out of bounds
Поскольку 11-й строки матрицы не существует, мы получаем 
Если мы не знаем, сколько строк в матрице, мы можем использовать функцию nrow() , чтобы узнать:
#display number of rows in matrix nrow(x) [1] 10
Мы видим, что в матрице всего 10 строк. Таким образом, мы можем использовать только числа меньше или равные 10 при доступе к строкам.
Например, мы можем использовать следующий синтаксис для отображения 10-й строки матрицы:
#display 10th row of matrix x[10, ] [1] 59 92 28Пример №2: нижний индекс выходит за пределы (со столбцами)
Следующий код пытается получить доступ к 4-му столбцу несуществующей матрицы:
#attempt to display 4th column of matrix x[, 4] Error in x[, 4] : subscript out of bounds
Поскольку 4-й столбец матрицы не существует, мы получаем индекс ошибки выхода за границы .
Если мы не знаем, сколько столбцов в матрице, мы можем использовать функцию ncol() , чтобы узнать:
#display number of columns in matrix ncol(x) [1] 3
Мы видим, что в матрице всего 3 столбца. Таким образом, мы можем использовать только числа меньше или равные 3 при доступе к столбцам.
Таким образом, мы можем использовать только числа меньше или равные 3 при доступе к столбцам.
Например, мы можем использовать следующий синтаксис для отображения третьего столбца матрицы:
#display 3rd column of matrix x[, 3] [1] 96 44 33 35 70 86 42 38 20 28Пример № 3: нижний индекс выходит за пределы (строки и столбцы)
Следующий код пытается получить доступ к несуществующему значению в 11-й строке и 4-м столбце матрицы:
#attempt to display value in 11th row and 4th column x[11, 4] Error in x[11, 4] : subscript out of bounds
Поскольку ни 11-й строки, ни 4-го столбца матрицы не существует, мы получаем нижний индекс ошибки выхода за границы .
Если мы не знаем, сколько строк и столбцов в матрице, мы можем использовать функцию dim() , чтобы узнать:
#display number of rows and columns in matrix dim(x) [1] 10 3
Мы видим, что в матрице всего 10 строк и 3 столбца. Таким образом, мы можем использовать только числа, меньшие или равные этим значениям, при доступе к строкам и столбцам.
Например, мы можем использовать следующий синтаксис для отображения значения в 10-й строке и 3-м столбце матрицы:
#display value in 10th row and 3rd column of matrix x[10, 3] [1] 28Дополнительные ресурсы
В следующих руководствах объясняется, как устранять другие распространенные ошибки в R:
Как исправить в R: имена не совпадают с предыдущими именами
Как исправить в R: более длинная длина объекта не кратна более короткой длине объекта
Как исправить в R: контрасты могут применяться только к факторам с 2 или более уровнями
Почтовый индекс ул. Р.Дрегиса, с. Вольно-Надеждинское, Надеждинский р-н, Приморский край
Почтовые индексы ул. Р.Дрегиса 692481
Почтовые индексы ул. Р.Дрегиса по номерам домов
Во всех домах по ул. Р.Дрегиса индекс 692481
| № дома | Индекс |
|---|---|
| 1 | 692481 |
| 1 к.2 | 692481 |
| 1а | 692481 |
| 1б | 692481 |
| 1в | 692481 |
| 1г | 692481 |
| 2б | 692481 |
| 3а | 692481 |
| 4 | 692481 |
| 4а | 692481 |
| 5 | 692481 |
| 6 | 692481 |
| 6/1 | 692481 |
| 6/1 | 692481 |
| 6/2 | 692481 |
| 7 | 692481 |
| 8 | 692481 |
| 8/1 | 692481 |
| 9 | 692481 |
| 9а | 692481 |
| 9б | 692481 |
| 10 | 692481 |
| 11 | 692481 |
| 11а | 692481 |
| № дома | Индекс |
|---|---|
| 11б | 692481 |
| 12 | 692481 |
| 12а | 692481 |
| 14 | 692481 |
| 15 | 692481 |
| 15а | 692481 |
| 17 | 692481 |
| 19 | 692481 |
| 21 | 692481 |
| 21/2 | 692481 |
| 22 | 692481 |
| 23 | 692481 |
| 24 | 692481 |
| 25 | 692481 |
| 25а | 692481 |
| 26 | 692481 |
| 27 | 692481 |
| 29 | 692481 |
| 31 | 692481 |
| 32 | 692481 |
32 к. 2 2 | 692481 |
| 32 к.3 | 692481 |
| 32 к.4 | 692481 |
| 33 | 692481 |
| № дома | Индекс |
|---|---|
| 33а | 692481 |
| 34 | 692481 |
| 35 | 692481 |
| 36 | 692481 |
| 37 | 692481 |
| 38 | 692481 |
| 38/2 | 692481 |
| 42 | 692481 |
| 44 | 692481 |
| 44а | 692481 |
| 46 | 692481 |
| 48 | 692481 |
| 48а | 692481 |
| 50 | 692481 |
| 52 | 692481 |
| 54 | 692481 |
| 56 | 692481 |
| 58 | 692481 |
| 60 | 692481 |
| 60/1 | 692481 |
| 62 | 692481 |
| 64 | 692481 |
| № дома | Индекс |
|---|---|
| 1 | 692481 |
1 к. 2 2 | 692481 |
| 1а | 692481 |
| 1б | 692481 |
| 1в | 692481 |
| 1г | 692481 |
| 2б | 692481 |
| 3а | 692481 |
| 4 | 692481 |
| 4а | 692481 |
| 5 | 692481 |
| 6 | 692481 |
| 6/1 | 692481 |
| 6/1 | 692481 |
| 6/2 | 692481 |
| 7 | 692481 |
| 8 | 692481 |
| 8/1 | 692481 |
| 9 | 692481 |
| 9а | 692481 |
| 9б | 692481 |
| 10 | 692481 |
| 11 | 692481 |
| 11а | 692481 |
| 11б | 692481 |
| 12 | 692481 |
| 12а | 692481 |
| 14 | 692481 |
| 15 | 692481 |
| 15а | 692481 |
| 17 | 692481 |
| 19 | 692481 |
| 21 | 692481 |
| 21/2 | 692481 |
| 22 | 692481 |
| № дома | Индекс |
|---|---|
| 23 | 692481 |
| 24 | 692481 |
| 25 | 692481 |
| 25а | 692481 |
| 26 | 692481 |
| 27 | 692481 |
| 29 | 692481 |
| 31 | 692481 |
| 32 | 692481 |
32 к. 2 2 | 692481 |
| 32 к.3 | 692481 |
| 32 к.4 | 692481 |
| 33 | 692481 |
| 33а | 692481 |
| 34 | 692481 |
| 35 | 692481 |
| 36 | 692481 |
| 37 | 692481 |
| 38 | 692481 |
| 38/2 | 692481 |
| 42 | 692481 |
| 44 | 692481 |
| 44а | 692481 |
| 46 | 692481 |
| 48 | 692481 |
| 48а | 692481 |
| 50 | 692481 |
| 52 | 692481 |
| 54 | 692481 |
| 56 | 692481 |
| 58 | 692481 |
| 60 | 692481 |
| 60/1 | 692481 |
| 62 | 692481 |
| 64 | 692481 |
Номера домов по индексу
| Индекс | Номера домов |
|---|---|
| 692481 | 1, 1 к. 2, 1а, 1б, 1в, 1г, 2б, 3а, 4, 4а, 5, 6, 6/1, 6/1, 6/2, 7, 8, 8/1, 9, 9а, 9б, 10, 11, 11а, 11б, 12, 12а, 14, 15, 15а, 17, 19, 21, 21/2, 22, 23, 24, 25, 25а, 26, 27, 29, 31, 32, 32 к.2, 32 к.3, 32 к.4, 33, 33а, 34, 35, 36, 37, 38, 38/2, 42, 44, 44а, 46, 48, 48а, 50, 52, 54, 56, 58, 60, 60/1, 62, 64 2, 1а, 1б, 1в, 1г, 2б, 3а, 4, 4а, 5, 6, 6/1, 6/1, 6/2, 7, 8, 8/1, 9, 9а, 9б, 10, 11, 11а, 11б, 12, 12а, 14, 15, 15а, 17, 19, 21, 21/2, 22, 23, 24, 25, 25а, 26, 27, 29, 31, 32, 32 к.2, 32 к.3, 32 к.4, 33, 33а, 34, 35, 36, 37, 38, 38/2, 42, 44, 44а, 46, 48, 48а, 50, 52, 54, 56, 58, 60, 60/1, 62, 64 |
Адрес почтового отделения обслуживающего ул. Р.Дрегиса
692481 — Р.Дрегиса ул, 1, с Вольно-Надеждинское, Приморский край
Информация об адресе
| Адрес: | ул. Р.Дрегиса, с. Вольно-Надеждинское, Надеждинский р-н, Приморский край |
| Почтовые индексы: | 692481 |
| Образец написания индекса: | |
| ОКАТО: | 05223000013 |
| ОКТМО: | 05623402101 |
| Код ИФНС (физические лица): | 2502 |
| Код ИФНС (юридические лица): | 2502 |
| Код адресного объекта одной строкой с признаком актуальности: | 25011000001002000 |
| Код адресного объекта одной строкой без признака актуальности: | 250110000010020 |
| Реестровый номер адресного объекта: | 056234021010000002001 |
| Источник данных: | ФИАС в формате ГАР |
| Данные обновлены: | 2022-01-17 15:45:52 |
ул.
 Р.Дрегиса на карте
Р.Дрегиса на картеПочтовые индексы с. Вольно-Надеждинское
Почтовые индексы Надеждинский р-н
Почтовые индексы Приморский край
Узнать почтовый индекс по адресу
Indexing — R Spatial
Существует несколько способов доступа или замены значений в векторах или других структуры данных. Наиболее распространенным подходом является использование «индексации». Это также называется «нарезкой».
Обратите внимание, что скобки [ ] используются для индексации, тогда как
вы уже видели, что скобки ( ) используются для вызова
функция. Позже вы также увидите использование { } . Это очень
важно не перепутать их.
Вектор
Вот несколько примеров, которые показывают, как можно получить элементы векторов путем индексации.
б <- 10:15 б ## [1] 10 11 12 13 14 15
Получить первый элемент вектора
b[1] ## [1] 10
Получить первый второй элемент вектора
b[2] ## [1] 11
Получить элементы 2 и 3
b[2:3] ## [1] 11 12 # это то же самое, что и б[с(2,3)] ## [1] 11 12 # или я <- 2:3 б[я] ## [1] 11 12
Теперь более сложный пример, вернуть все элементы, кроме второго
b[c(1,3:6)] ## [1] 10 12 13 14 15 # или намного проще: Би 2] ## [1] 10 12 13 14 15
Вы также можете использовать индекс для изменения значений
b[1] <- 11 б ## [1] 11 11 12 13 14 15 б[3:6] <- -99 б ## [1] 11 11 -99 -99 -99 -99
Важной характеристикой системы векторизации R является то, что
более короткие векторы «перерабатываются».
Здесь вы видите переработку в действии. Сначала мы присваиваем один номер
первые три элемента b , поэтому число используется три раза. Затем
мы присваиваем два числа последовательности от 3 до 6, так что оба числа
используются дважды.
б[1:3] <- 2 б ## [1] 2 2 2 -99 -99 -99 б[3:6] <- с(10,20) б ## [1] 2 2 10 20 10 20
Матрица
Рассмотрим матрицу m .
м <- матрица(1:9, nrow=3, ncol=3, byrow=ИСТИНА)
colnames(m) <- c('a', 'b', 'c')
м
## а б в
## [1,] 1 2 3
## [2,] 4 5 6
## [3,] 7 8 9
Как и векторы, значения матриц могут быть доступны посредством индексации. Там
есть разные способы сделать это, но, как правило, проще всего использовать два
числа в двойном индексе, первый для номера строки и
второй для номера столбца (ов).
# одно значение м[2,2] ## б ## 5 # Еще один м[1,3] ## с ## 3
Вы также можете получить несколько значений одновременно.
# 2 столбца и строки м[1:2,1:2] ## а б ## [1,] 1 2 ## [2,] 4 5 # весь ряд м[2, ] ## а б в ## 4 5 6 # весь столбец м[ ,2] ## [1] 2 5 8
Или используйте имена столбцов для поднастройки.
#один столбец
м[ 'б']
## [1] 2 5 8
# два столбца
м[ с('а', 'с')]
## а в
## [1,] 1 3
## [2,] 4 6
## [3,] 7 9
Вместо индексации двумя номерами вы также можете использовать один номер. Вы можете думать об этом как о «сотовом номере». Ячейки пронумерованы по столбцам (т. е. сначала строки в первом столбце, затем во втором столбце, и т. д.). Таким образом,
м[2,2] ## б ## 5 # эквивалентно м[5] ## [1] 5
Обратите внимание, что
м[ ,2] ## [1] 2 5 8
возвращает вектор. Это связано с тем, что матрица с одним столбцом может быть
упрощается до вектора. В этом случае матричная структура «сбрасывается».
Это не всегда желательно, и чтобы этого не происходило, можно
использовать
В этом случае матричная структура «сбрасывается».
Это не всегда желательно, и чтобы этого не происходило, можно
использовать drop=FALSE аргумент.
м[ , 2, падение=ЛОЖЬ] ## б ## [1,] 2 ## [2,] 5 ## [3,] 8
Установка значений матрицы аналогична тому, как вы делаете это для вектор, за исключением того, что теперь вам нужно иметь дело с двумя измерениями.
# одно значение м[1,1] <- 5 м ## а б в ## [1,] 5 2 3 ## [2,] 4 5 6 ## [3,] 7 8 9 # ряд м[3,] <- 10 м ## а б в ## [1,] 5 2 3 ## [2,] 4 5 6 ## [3,] 10 10 10 # две колонны, с рециркуляцией м[2:3] <- 3:1 м ## а б в ## [1,] 5 3 3 ## [2,] 4 2 2 ## [3,] 10 1 1
Есть функция для получения (или установки) значений по диагонали матрица.
диаг.(м) ## [1] 5 2 1 диаг.(м) <- 0 м ## а б в ## [1,] 0 3 3 ## [2,] 4 0 2 ## [3,] 10 1 0
Список
Списки индексации могут немного сбивать с толку, так как вы оба можете ссылаться на
элементы списка или элементы данных (возможно, матрицы) в
один из элементов списка. Ниже обратите внимание на разницу в том, что двойное
кронштейны сделать.
Ниже обратите внимание на разницу в том, что двойное
кронштейны сделать. e[3] возвращает список (длиной 1), но e[[3]] возвращает то, что находится внутри этого элемента списка (в данном случае матрицу)
m <- matrix(1:9, nrow=3, ncol=3, byrow=TRUE)
colnames(m) <- c('a', 'b', 'c')
e <- list(list(1:3), c('a', 'b', 'c', 'd'), m)
Мы можем получить доступ к данным внутри элемента списка, комбинируя двойные и одинарные кронштейны. При использовании двойных скобок структура списка отбрасывается.
е[2] ## [[1]] ## [1] "а" "б" "в" "г" е[[2]] ## [1] "а" "б" "в" "г"
Элементы списка могут иметь имена.
имен(e) <- c('zzz', 'xyz', 'abc')
И элементы могут быть извлечены по их имени, либо как индекс, либо
с помощью оператора $ (долларов).
e$xyz ## [1] "а" "б" "в" "г" е[['xyz']] ## [1] "а" "б" "в" "г"
$ также можно использовать с объектами data. frame (специальный список,
в конце концов), но не с матрицами.
frame (специальный список,
в конце концов), но не с матрицами.
Data.frame
Индексирование a data.frame вообще можно делать как для матриц так и для
списки.
Сначала создайте data.frame из матрицы m .
d <- data.frame(m) класс (г) ## [1] "data.frame"
Вы можете извлечь столбец по номеру столбца.
д[2] ## [1] 2 5 8
Альтернативный способ адресации номера столбца в data.frame .
д[2] ## б ## 1 2 ## 2 5 ## 3 8
Обратите внимание, что тогда как [2] будет вторым элементом в матрице ,
он относится ко второму столбцу в data.frame . Это потому, что data.frame — это особый вид списка, а не особый вид
матрица.
Вы также можете использовать имя столбца для получения значений. Этот подход также работает
для матрицы .
д[ 'б'] ## [1] 2 5 8
Но с data.frame вы также можете сделать
d$b ## [1] 2 5 8 # или это д[['б']] ## [1] 2 5 8
Все они возвращают вектор. То есть сложность data.frame структура была удалена . Этого не происходит, когда вы делаете
d['b'] ## б ## 1 2 ## 2 5 ## 3 8
или
d[ , 'b', drop=FALSE] ## б ## 1 2 ## 2 5 ## 3 8
Зачем вам это падение бизнес? Ну во многих случаях Функции R требуют определенного типа данных, например, матрицы или data.frame и сообщить об ошибке, если они получат что-то еще. Один
распространенная ситуация заключается в том, что вы думаете, что предоставляете данные правильного типа,
например, data.frame , но на самом деле вы предоставляете вектор , потому что структура отбросила , если вы подмножили данные
в один столбец.
Какие, %в% и совпадают
Иногда у вас нет нужных вам индексов, и поэтому вам нужно найти их. Например, каковы индексы элементов вектора, имеют значения выше 15?
х <- 10:20 я <- который (х > 15) Икс ## [1] 10 11 12 13 14 15 16 17 18 19 20 я ## [1] 7 8 9 10 11 х[я] ## [1] 16 17 18 19 20
Обратите внимание, однако, что вы также можете использовать логический вектор для индексации
(значения, для которых индекс равен ИСТИНА возвращаются).
х <- 10:20 б <- х > 15 Икс ## [1] 10 11 12 13 14 15 16 17 18 19 20 б ## [1] FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE х[б] ## [1] 16 17 18 19 20
Очень полезный оператор, который позволяет узнать, является ли набор значений
присутствует в векторе %в% .
х <- 10:20 j <- c(7,9,11,13) j %in% x ## [1] ЛОЖЬ ЛОЖЬ ИСТИНА ИСТИНА который(j%in%x) ## [1] 3 4
Другая удобная аналогичная функция — match :
match(j, x) ## [1] НП НП 2 4
Это говорит нам о том, что третье значение в j равно второму значению
в x и что четвертое значение в ‘j’ равно четвертому значению
в разрешении х.
соответствует асимметрично: соответствует (j,x) не совпадает с совпадение(x,j) .
совпадение(х, j) ## [1] NA 3 NA 4 NA NA NA NA NA NA NA
Это показывает, что второе значение в x равно третьему значению в
‘j’ и т. д.
Векторы и индексирование — наука о данных с R
R имеет специальную структуру данных, называемую вектором. Вектор — это одномерный набор объектов одного типа. Чаще всего вектор будет просто последовательностью чисел. Мы можем создать последовательность чисел, используя оператор : .
чисел <- 1:10 номера
## [1] 1 2 3 4 5 6 7 8 9числа
## [1] 2 4 8 16 32 64 128 256 512 1024
sin(числа)
## [1] 0.8414710 0.9092974 0.1411200 -0.72589189 -0.72589589 -0.72589589 -0.75689589 ## [7] 0.6569866 0.9893582 0.4121185 -0.5440211
Мы также можем создать вектор с помощью функции c() ( c означает объединение, если вам интересно).
concat <- c(4, 17, -1, 55, 2) concat
## [1] 4 17 -1 55 2
Индексация
Часто нам не нужно получать весь вектор. Возможно, нам нужен только один элемент или набор определенных элементов. Мы делаем это с помощью индексации (используются скобки [] ).
Чтобы получить первый элемент вектора, мы могли бы сделать следующее. В R индексы массивов начинаются с 1 — 1-й элемент имеет индекс 1. Это отличается от языков на основе 0, таких как C, Python или Java, где первый элемент имеет индекс 0.
concat[1]
# # [1] 4
Чтобы получить другие элементы, мы могли бы сделать следующее:
concat[2] # второй элемент
## [1] 17
concat[length(concat)] # последний элемент
## [1] 2
Обратите внимание, что для второго примера мы поместили функцию внутри квадратных скобок. В этом случае length() используется для получения длины вектора, а поскольку длина вектора будет равна индексу его последнего элемента, это отличный способ получить последний элемент вектора. .
.
В квадратных скобках можно поместить что угодно. Например, помещение другого вектора в скобки дает нам несколько значений.
concat[1:4]
## [1] 4 17 -1 55
concat[c(3, 5)]
## [1] -1 2
Мы можем использовать эту технику для переназначения определенные значения внутри вектора. Например, мы можем изменить 3-е и 5-е значения на 76 с помощью следующего кода:
concat[c(3, 5)] <- 76 concat
## [1] 4 17 76 55 76
Можно даже индексировать за пределами вектора. Обратите внимание, что R «заполняет пробелы» значениями NA . NA — это заполнитель R для «нет данных» (поскольку 0 часто появляется в реальных данных).
concat[10] <- 4.3 concat
## [1] 4.0 17.0 76.0 55.0 76.0 NA NA NA NA 4.3
НИКОГДА ЭТОГО НЕ ДЕЛАЙТЕ. Хотя на самом деле это допустимый код в R (индексирование за пределами размера вектора является ошибкой в большинстве других языков), это сказывается на производительности. Позже мы более подробно рассмотрим, почему.
Позже мы более подробно рассмотрим, почему.
Матрицы
Матрица представляет собой двумерный вектор. Давайте создадим матрицу с матрица() функция. Одно важное замечание: функции часто имеют необязательные, «дополнительные» аргументы, которые указываются в нотации имя=значение . В этом случае мы создаем матрицу с 2 строками и 5 столбцами.
мат <- матрица (1:10, nrow=2, ncol=5) мат
## [1] [2] [3] [4] [5] ## [1,] 1 3 5 7 9 ## [2,] 2 4 6 8 10
Все те же операции, которые работают с векторами, также работают и с матрицами.
мат + 20
## [1] [2] [3] [4] [5] ## [1,] 21 23 25 27 29 ## [2,] 22 24 26 28 30
dim(mat) # получить размеры матрицы
## [1] 2 5
length(mat) # количество элементов в матрице
## [ 1] 10
Однако индексация матрицы немного отличается от индексации вектора. Теперь у нас есть не одно, а два измерения на выбор. При индексировании с использованием объекта с несколькими измерениями мы используем , для их разделения. В R строки находятся слева от запятой, а столбцы — справа (третье измерение будет после второй запятой и так далее…). Обратите внимание, что R на самом деле пытается нам помочь. Когда мы напечатали нашу матрицу, в строках было
В R строки находятся слева от запятой, а столбцы — справа (третье измерение будет после второй запятой и так далее…). Обратите внимание, что R на самом деле пытается нам помочь. Когда мы напечатали нашу матрицу, в строках было [#,] рядом с ними, а столбцы имеют [#] . Это фактически показывает нам точный синтаксис, который нам нужен для получения каждого элемента.
Таким образом, используя выходные данные матрицы, mat[1,] должны дать нам первую строку, а mat[4] должны дать нам четвертый столбец. Давайте проверим это:
mat[1,]
## [1] 1 3 5 7 9
mat[4]
## [1] 7 8
Мы можем индексировать как строки, так и столбцы в в то же время, чтобы получить определенный элемент.
mat[1, 1] # взять первый ряд, первый столбец
## [1] 1
mat[2, 1:3] # элементы 1-3 второго ряда
## [1] 2 4 6
Упражнение. Захват несвязанных элементов
Попробуйте получить столбцы 1, 4 и 5 первой строки одной командой.
Упражнение. Чтение документации
Создайте матрицу 8x5, используя числа 1:40. Посмотрите, сможете ли вы заполнить его по строкам, а не по столбцам.
Подсказка: вы должны проверить документацию для матрица() .
Различные типы данных
В большинстве языков программирования текст называется строкой. Чтобы создать текст в R, мы просто заключаем его в двойные ( " ) или одинарные ( ' ) кавычки. Мы уже видели пример строки ( print('hello world!') ).
"это строка"
## [1] "это строка"
paste('мы можем комбинировать строки', 'с помощью функции paste()') ## [1] "мы может объединять строки с помощью функции paste()"
Что произойдет, если мы добавим строку к вектору чисел?
чисел <- c(1, 4, 9, 10) числа
## [1] 1 4 9 10
числа[3] <- "тестирование..." числа
## [1] "1" "4" "тестирование..." "10"
Весь наш вектор чисел превратился в строки! Это важное свойство векторов и матриц: они могут содержать только один тип данных! Если мы попытаемся поместить другой тип в вектор, R преобразует весь вектор в новый тип данных.
Опять же, это преобразование оказывает сильное влияние на производительность, особенно для больших векторов или матриц. R необходимо создать новый вектор с нуля, а затем скопировать и преобразовать каждый элемент.
Итак, давайте узнаем о различных типах данных R. Есть еще несколько типов, которые мы не рассматриваем здесь или рассмотрим позже (например, факторы). Это просто наиболее распространенные типы данных, с которыми мы столкнемся.
Числовые
Числовые переменные могут содержать любое десятичное число, положительное или отрицательное. В других языках они называются поплавками. Обратите внимание, что это тип числа по умолчанию в R.
Чтобы создать числовое значение, все, что нам нужно сделать, это ввести его как обычно.
1
## [1] 1
-3.5
## [1] -3.5
Мы можем преобразовать другую переменную в числовую с помощью функции as.numeric() . Это работает только со значениями, которые можно легко преобразовать.
as.numeric("456") # это работает ## [1] 456
as.numeric("seven") # это не работает 1] нет данных Целые числа
Целые числа представляют любое целое число, положительное или отрицательное. Они не могут хранить десятичные числа.
Чтобы создать число явно как целое число, добавьте после него L .
15L
## [1] 15
Мы можем преобразовать набор данных в целое число с помощью функции as.integer() .
as.integer(c("65.3", "4")) ## [1] 65 4
Символы (строки)
Как упоминалось ранее, строки представляют собой наборы текста. Мы можем превратить что-то в строку с помощью as.character() функция.
as.character(TRUE)
## [1] "TRUE"
Логические (логические) значения
Есть только два логических значения: TRUE и FALSE . Они используются в буквальном смысле для обозначения того, является ли утверждение истинным или ложным.
Как обычно, мы можем преобразовать что-либо в логическое/логическое значение с помощью функции as.logical() . Важно отметить, что это очень хорошо демонстрирует, что происходит, когда мы превращаем один тип данных в другой. Если один тип данных не может содержать дополнительную информацию из другого, эта информация теряется во время преобразования.
пятьдесят <- as.logical(50) пятьдесят
## [1] TRUE
as.numeric(fifty)
## [1] 1
Определение типов данных
тип данных с функцией class() :
class(14)
## [1] "numeric"
class(1L)
## [1] "integer"
class (ИСТИНА)
## [1] "логический"
class("текст") ## [1] "character"
class(NA)
## [1] "logical"
Обратите внимание, что NA могут быть любого типа и часто используются в качестве заполнителей для отсутствующих данных .