|
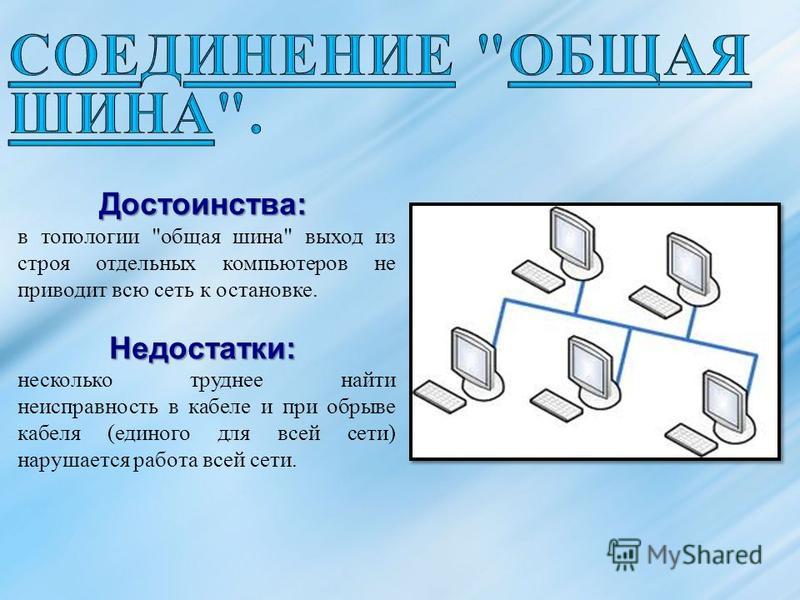
Топология «общая шина». Собираем компьютер своими руками
Читайте также
Шина SPD
Шина SPD
Итак, компьютеры серии AS/400е могут поддерживать шины SPD, PCI или обе одновременно. Шина PCI — промышленный стандарт и известна лучше, чем шина SPD, так что мы не будем тратить время на ее детальное описание. К тому же для большинства пользователей основным способом
Шина PCI — промышленный стандарт и известна лучше, чем шина SPD, так что мы не будем тратить время на ее детальное описание. К тому же для большинства пользователей основным способом
Топология беспроводной сети
Топология беспроводной сети Специфика использования радиоэфира в качестве среды передачи данных накладывает свои ограничения на топологию данной сети. Если сравнивать ее с топологией проводной сети, то наиболее близкими вариантами оказываются топология «звезда» и
3.4 Маршрутизаторы и топология сети
3.4 Маршрутизаторы и топология сети Набор протоколов TCP/IP может использоваться как в независимых локальных или региональных сетях, так и для их объединения в общие сети интернета. Любой хост с TCP/IP может взаимодействовать с другим хостом через локальную сеть, соединение
7.
 2.6.6. Общая память
2.6.6. Общая память
7.2.6.6. Общая память Тогда как два процесса, использующие для информационного обмена сокеты, могут выполняться на различных машинах (и в действительности могут быть разделены Internet-соединением, «огибающим» половину планеты), общая память (shared memory) требует, чтобы поставщики и
Общая настройка ПК
Общая настройка ПК Изменение разрешения экрана Для изменения разрешения экрана (например, на 800?600) следует внести следующие изменения в реестр: Ключ:[HKEY_LOCAL_MACHINEConfig001DisplaySettings]Значение ключа: «Resolution»=»800,
Общая реализация
Общая реализация
Теперь посмотрим, как можно обобщить класс CDelegateVoid для применения с различными сигнатурами. Используя шаблоны, мы можем параметризовать как тип возвращаемого значения, так и типы параметров функций, на которые ссылаются делегаты. В то же время, мы не
Используя шаблоны, мы можем параметризовать как тип возвращаемого значения, так и типы параметров функций, на которые ссылаются делегаты. В то же время, мы не
7.3.3. Шина PCI
7.3.3. Шина PCI В файле /proc/pci перечислены устройства, подключенные к шине (или шинам) PCI. Сюда входят реальные PCI-платы, а также устройства, встроенные в материнскую плату, плюс графические платы AGP. В каждой строке указан тип устройства, идентификатор устройства и его
Г.1. Общая информация
Г.1. Общая информация
? http://www.advancedlinuxprogramming.com. Это Web-узел данной книги. Здесь можно загрузить текст книги в электронном виде вместе с исходными текстами программ, найти ссылки на другие ресурсы и получить дополнительную информацию о программировании в Linux.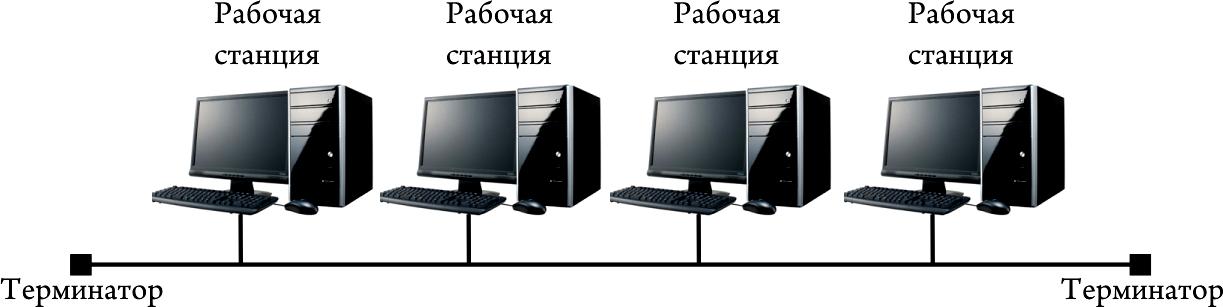 ? http://www.linuxdoc.org.
? http://www.linuxdoc.org.
Общая картина
Общая картина Важно проследить за последовательностью происходящих событий. Для рассмотренного выше экземпляра BOOK3 происходит следующее:[x]. (B1) Создан экземпляр QUOTATION. Пусть Q_OBJ — этот экземпляр и имеется сущность a, значение которой ссылка, присоединенная к Q_OBJ. [x]. (B2)
Топология сетей
Топология сетей Перед началом создания сети необходимо выяснить, где и как будут располагаться подключаемые компьютеры. Нужно также определить место для необходимого сетевого оборудования и то, как будут проходить связывающие компьютеры кабели. Одним словом,
12.1. Топология Ethernet-сетей
12. 1. Топология Ethernet-сетей
Существуют четыре топологии проводной сети – «общая шина», «звезда», «кольцо» и
1. Топология Ethernet-сетей
Существуют четыре топологии проводной сети – «общая шина», «звезда», «кольцо» и
Топология «звезда»
Топология «кольцо»
Топология «кольцо» Если кабель, к которому подключены компьютеры, замкнут, то топология называется «кольцо» (рис. 12.3). Рис. 12.3. Сеть, построенная по топологии «кольцо»При подобном подключении каждый компьютер должен передавать возникший сигнал по кругу, предварительно
Комбинированная топология
Комбинированная топология
Комбинированная топология появляется в том случае, когда одна из описанных выше топологий пересекается с другой (рис.
13.1. Топология беспроводной сети
13.1. Топология беспроводной сети Сегодня используются два варианта беспроводной архитектуры – независимая и инфраструктурная. Отличия между ними незначительны, но существенно влияют на такие показатели, как количество подключаемых компьютеров, радиус сети,
Физическая топология
Физическая топология Система PKI, помимо выполнения целого ряда функций — выпуска сертификатов, генерации ключей, управления безопасностью, аутентификации, восстановления данных, — должна обеспечивать интеграцию с внешними системами. PKI необходимо взаимодействовать с
Коаксиальный Ethernet кабель, сеть с топологией общая шина или зачем нужны хабы и сетевые концентраторы
Привет, посетитель сайта ZametkiNaPolyah. ru! Продолжаем изучать основы работы компьютерных сетей, напомню, что эти записи основаны на программе Cisco ICND1 и помогут вам подготовиться к экзаменам CCENT/CCNA. В данной теме мы разберемся с назначением хабов и сетевых концентраторов, а также обсудим особенности компьютерной сети с топологией общая шина и поговорим о правиле четырех хабов. Сразу же в самом начале стоит сказать, что сеть, построенная на хабах обладает практически всеми особенностями сети передачи данных с топологией общая шина.
ru! Продолжаем изучать основы работы компьютерных сетей, напомню, что эти записи основаны на программе Cisco ICND1 и помогут вам подготовиться к экзаменам CCENT/CCNA. В данной теме мы разберемся с назначением хабов и сетевых концентраторов, а также обсудим особенности компьютерной сети с топологией общая шина и поговорим о правиле четырех хабов. Сразу же в самом начале стоит сказать, что сеть, построенная на хабах обладает практически всеми особенностями сети передачи данных с топологией общая шина.
На данный момент с практической точки зрения данная запись не имеет большой актуальности, так как хабы и коаксиальный Ethernet кабель вы скорее всего уже не встретите, поэтому, чтобы не тратить время в пустую мы будем не просто рассматривать недостатки хабов и общей шины, но и смотреть на преимущества, которые нам дают коммутаторы.
Перед началом я хотел бы вам напомнить, что ознакомиться с опубликованными материалами первой части нашего курса можно по ссылке: «Основы взаимодействия в компьютерных сетях».
1.18.1 Введение
Содержание статьи:
В прошлой теме мы немного попрактиковались и разобрались с вопросом: как объединить три и более компьютера в сеть, делали мы это при помощи коммутаторов, сразу отмечу, что на данный момент для вышеописанной задачи стоит выбирать именно коммутаторы и не стоит прибегать к использованию хабов, повторителей и коаксиального Ethernet кабеля, который использовался ранее в схемах соединения с общей шиной
Вернее, все вышеописанные ухищрения по сути добавят вам одну единственную, но очень серьезную проблему, которую довольно неприятно решать, эта проблема называется коллизией. Коллизия – это наложение или столкновение двух пакетов, участок сети, на котором может возникнуть такая проблема называется доменом коллизий.
1.18.2 Зачем нужны хабы, повторители и сетевые концентраторы
Для начала давайте коротко поговорим о том, зачем же все-таки нужны или были нужны хабы, повторители и сетевые концентраторы. Ответ довольно прост: все эти устройства используются/использовались для объединения компьютеров в сеть. Но если хабы и сетевые концентраторы, скорее всего, на данный момент вы не встретите в Ethernet сетях, то повторители встретить можно, главным образом на междугородних оптических линиях.
Ответ довольно прост: все эти устройства используются/использовались для объединения компьютеров в сеть. Но если хабы и сетевые концентраторы, скорее всего, на данный момент вы не встретите в Ethernet сетях, то повторители встретить можно, главным образом на междугородних оптических линиях.
Итак, давайте для начала буквально на пальцах разберемся с вопросом: в чем разница между коммутатором и хабом, а затем поговорим немного о частностях, которые касаются хабов и концентраторов, не сильно вдаваясь в детали, так как это уже не мейнстрим. Для сравнения будем использовать Cisco Packet Tracer, в котором реализуем две простые схемы, но в одной схеме будет использован хаб, а в другой коммутатор, обе схемы показаны на Рисунке 1.18.1. Если вы самостоятельно будете собирать схему в Cisco Packet Tracer, то обратите внимание на то, что порты хаба сразу загораются зеленым, то есть через них сразу могут идти данные, а коммутатору нужно немного подумать, прежде чем разрешить начать передачу данных.
Рисунок 1.18.1 Слева показана схема с хабом, справа – с коммутатором
Давайте перейдем в режим симуляции и попробуем запусить пинг с ноутбука до компьютера 192.168.1.2, в обеих схемах это крайний левый ПК. Начало везде одинаковое: оба ноутбука сформировали IP-пакет с ICMP вложением и пытаются отправить этот пакет на устройство с адресом 192.168.1.1, это показано на Рисунке 1.18.2.
Рисунок 1.18.2 Оба ноутбука сформировали IP-пакет с ICMP вложением
Следующим шагом наш пакет приходит в первом случае на порт хаба, который смотрит в сторону отправителя, а во втором случае на порт коммутатора, который смотрит в сторону отправителя, это показано на рисунке 1.18.3.
Рисунок 1.18.3 В обоих случаях пакет приходит на входящий порт устройств
Пока у нас нет никакой разницы, хотя на самом деле разница уже есть, но она сокрыта внутри устройств, и мы ее не увидим, дело в том, что коммутатор – устройство второго или канального уровня модели OSI, оно уже обладает определенной программной логикой, у его портов есть входные и выходные буферы, в которых своей участи ожидают Ethernet кадры, а поскольку коммутатор умеет работать с кадрами, то в его логику заложен принцип инкапсуляции данных. А вот хаб – это глупое устройство, которое относится к первому уровню модели OSI, то есть к физическому уровню и Рисунок 1.18.4 это хорошо демонстрирует.
А вот хаб – это глупое устройство, которое относится к первому уровню модели OSI, то есть к физическому уровню и Рисунок 1.18.4 это хорошо демонстрирует.
Рисунок 1.18.4 Принципиальная разница между хабом и коммутатором
Сперва обратите внимание на схему с хабом: он получил от ноутбука Ethernet кадр, внутри которого находится IP-пакета, а вложением в этот пакет является ICMP запрос (вспоминаем о декомпозиции задачи сетевого взаимодействия, к сожалению, сетевой концентратор с таким понятием не знаком), а затем разослал этот кадр в три других активных порта. При этом компьютеры с IP-адресами 192.168.1.3 и 192.168.1.4, распаковав кадр и проанализировав IP-пакет поняли, что этот пакет им не предназначен (это показано красным крестиком) и просто проигнорируют его, а вот компьютер с адресом 192.168.1.2 понял, что данные предназначены для него, поэтому он ответит (дело в том, что заголовок IP-пакет содержит поле с IP-адресом получателя, именно это поле позволяет понять компьютеру: ему или кому-то другому предназначен тот или иной пакет, в нашем случае два компьютера, для которых пакет не предназначен, просто отбрасывают его).
А теперь обратите внимание на схему с коммутатором: здесь Ethernet кадр со всеми вложениями был отправлен конкретному устройству с IP-адресом 192.168.1.2, другие устройства этот кадр не получили. Все дело в том, что наши сетевые устройства помимо IP-адреса, имею MAC-адреса (протокол, который позволяет узнать по имеющемуся IP-адресу MAC-адрес, называется ARP), а коммутатор, помимо буферов на порт,у имеет специальную табличку, в которую записывает: за каким портом какой мак-адрес находится. Позже мы узнаем, как правильно называется эта таблица и каким образом коммутатор ее заполняет, сейчас лишь отметим, что у этой таблички ограниченный объем и есть несколько атак, которые позволяют забить эту таблицу до отказа, тем самым вызвав отказ в обслуживании. Обратите внимание на Рисунок 1.18.5.
Рисунок 1.18.5 Таблица мак-адресов коммутатора на схеме
Естественно, коммутатор ничего не знает ни о каких схемах и топологиях, ему невдомек что вы там у себя задумали, нарисовали и запланировали, коммутатор – это относительно простой компьютер, который решает определенные задачи, в нашем случае, это объединение четырех компьютеров в сеть. На Рисунке 1.18.5 показано как примерно он это делает, у коммутатора есть порты, к которым подключаются устройства, у этих устройств есть мак-адреса, коммутатор каким-то образом узнает эти мак-адреса и ведет учет в виде специальной таблицы: записывая, за каким портом какой мак-адрес находится, рисунок это демонстрирует. Отмечу, что в любой момент мак-адрес за портом может измениться по разным причинам, поэтому эта табличка периодически очищается и при необходимости заполняется вновь. Но вернемся к нашей схеме, мы помним, что, как в схеме с хабом, так и в схеме с коммутатором, компьютеры с адресом 192.168.1.2 должны ответить на ICMP запросы, посланные ноутбуком, я не буду показывать процесс передачи кадра от узла с адресом 192.168.1.2, а сразу покажу, что сделают хаб и коммутатор с ответом этого узла, посмотрите на Рисунок 1.18.6.
На Рисунке 1.18.5 показано как примерно он это делает, у коммутатора есть порты, к которым подключаются устройства, у этих устройств есть мак-адреса, коммутатор каким-то образом узнает эти мак-адреса и ведет учет в виде специальной таблицы: записывая, за каким портом какой мак-адрес находится, рисунок это демонстрирует. Отмечу, что в любой момент мак-адрес за портом может измениться по разным причинам, поэтому эта табличка периодически очищается и при необходимости заполняется вновь. Но вернемся к нашей схеме, мы помним, что, как в схеме с хабом, так и в схеме с коммутатором, компьютеры с адресом 192.168.1.2 должны ответить на ICMP запросы, посланные ноутбуком, я не буду показывать процесс передачи кадра от узла с адресом 192.168.1.2, а сразу покажу, что сделают хаб и коммутатор с ответом этого узла, посмотрите на Рисунок 1.18.6.
Рисунок 1.18.6 Хаб снова рассылает кадры во все порты, кроме того, откуда этот кадр пришел
Обратите внимание: коммутатор действует конкретно, он отсылает кадр с вложенным ICMP-ответом именно тому устройству, которое делало запрос, а вот хаб, можно сказать обычный повторитель, отправляет кадры во все порты, кроме того порта, в который этот кадр пришел, то есть компьютеры с адресами 192.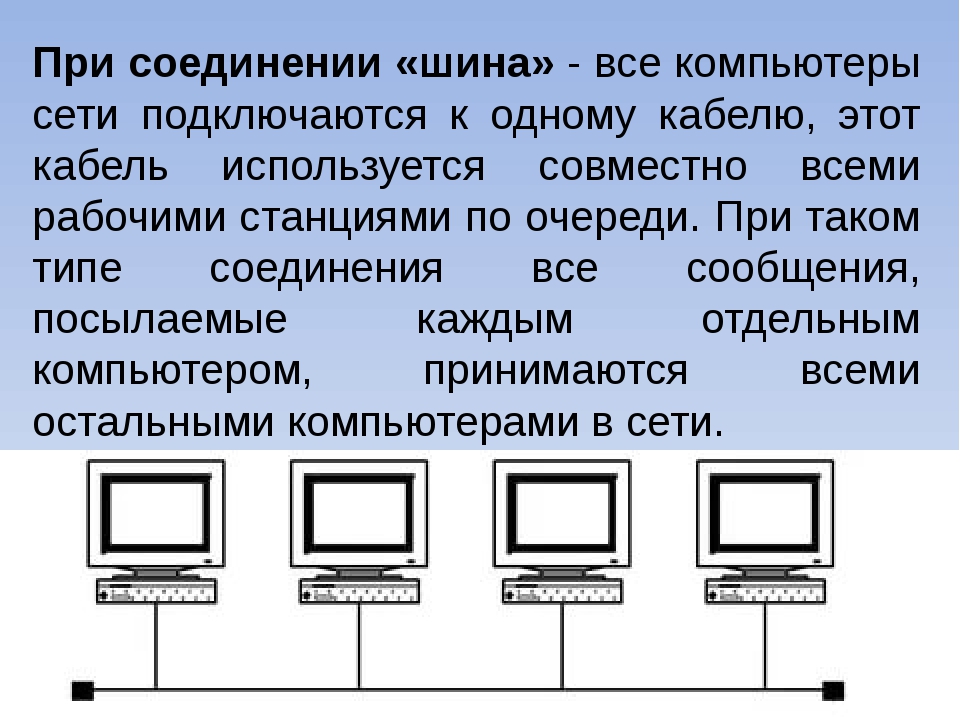 168.1.3 и 192.168.1.4 снова вынуждены работать вхолостую, а их канал опять загружен бесполезной информацией.
168.1.3 и 192.168.1.4 снова вынуждены работать вхолостую, а их канал опять загружен бесполезной информацией.
Таким образом мы имеем полное право называть сетевой концентратор обычным повторителем, он просто копирует приходящие на один порт данные и рассылает их во все порты, и тут у нас появляется два очевидных минуса:
- Первый минус заключается в том, что это не безопасно, приходящие на хаб данные получают все устройства, подключенные к нему, в том числе и те, кому эти данные не предназначены.
- Второй минус заключается в том, что хаб создает дополнительную загрузку каналов связи, наша простенькая сеть без трафика это продемонстрировала, но она не демонстрирует весь масштаб бедствия, нам даже не стоит говорить про служебный трафик, который используется в канальной среде для поддержания взаимодействия между устройствами, достаточно представить такую картину: одним портом хаб включен в роутер, который подключен к сети Интернет, а еще три порта хаба используются для подключения трех клиентов, каждый порт имеет пропускную способность 100 Мбит/c и тут один из клиентов решает включить торрент и загружает свой канал на максимум, а теперь вспомните как работает хаб.

А теперь не очевидный минус – коллизии, сразу отмечу, что нормальная компьютерная Ethernet сеть, можно сказать, лишена этого недостатка, а вот компьютерная сеть, в которой есть хабы слеш сетевые концентраторы, даже с учетом того, что Ethernet имеет механизм по разруливанию этих коллизий имеет этот недостаток, чуть ниже мы это обсудим.
Самая важная вещь, которую вам нужно усвоить – не используйте хабы, даже если вам будут угрожать, если вам предлагают обслуживать сеть, в которой есть хабы, то это повод задуматься: а стоит ли вообще связываться с таким работодателем, и это всё без капли иронии.
Давайте подведем итог тому, что может называться хабом, повторителем (мы сейчас не имеем в виду те повторители, которые используются для усиления сигнала) или сетевым концентратором (что касается его технической части). Это устройство работает на физическом уровне модели OSI 7, оно просто дублирует входную последовательность бит во все порты, кроме того, откуда эта последовательность пришла, поэтому хаб ничего не знает ни про какие мак-адреса и уж тем более не в курсе про IP.
Тут же нам стоит отметить, что продемонстрированная схема с коммутатором имеют топологию, которая называется звезда (здесь есть одно центральное устройство, в данном случае это коммутатор, и есть несколько других устройств, которые логически и физически завязаны на центральное устройство), а вот схема, в которой мы использовали концентратор имеет топологию общая шина, все дело в том, что вместо хаба мы могли бы использовать какой-нибудь провод, к которому подключили бы все устройства и с логической точки зрения ничего бы не изменилось.
Устройства, включенные через хаб или несколько хабов, между собой образуют домен коллизий, так как на любом участке такой сети может возникнуть коллизия, в случае же со схемой, в которой используется коммутатор, домен коллизии ограничивается портом коммутатора, коллизия может произойти только между коммутатором и конкретным устройством и то только в такой ситуации, которая привела к рассинхронизации режимы работы портов коммутатора и удаленного устройства, обычно это глюк порта коммутатора или же глюк клиентского устройства.
С точки зрения сетевого администратора у хаба есть три важных характеристики: количество портов, пропускная способность этих портов и физический тип подключения, здесь можно выделить витую пару, коаксиальный кабель и оптические линии. В общем, на этом мы можем закончить разговор о концентраторах и повторителях.
1.18.3 Коаксиальная сеть Ethernet и топология общая шина с ее недостатками
Сделаем еще один шаг назад в эволюции компьютерных сетей и рассмотрим коаксиальную Ethernet сеть с топологией общая шина, и тут нам стоит сразу отметить, что в такой сети есть все недостатки, которые присущи сетям с хабами, но помимо всего прочего добавляется еще один: при повреждении кабеля сеть становится неработоспособной, ну и процесс траблшутинга или поиска неисправностей заметно усложняется. Обратите внимание на Рисунок 1.18.7, на нем показана сеть, построенная по топологии общая шина.
Рисунок 1.18.7 Компьютерная сеть с топологией общая шина
Стоит немного пояснить данный рисунок:
- Толстая синяя линия в центре – это общая шина, но по факту это коаксиальный Ethernet кабель.

- Устройство в центре шины – это повторитель, он ставился в том случае, когда длина общей шины была слишком большой, в этом случае сеть разбивается на сегменты, в нашем случае их два (если говорить про стандарт Ethernet 10BASE-2, то длина общей шины на одном сегменте не должна превышать 185 метров).
- Тонкие линии от шины до конечных устройств – это отводы, это тоже коаксиальный Ethernet кабель.
- Одной важной особенностью топологии общая шина являлось то, что каждый провод в такой схеме должен быть обязательно окончен каким-либо устройством, поэтому на краях общей шины устанавливались специальные устройства, называемые терминаторами, которые поглощали сигнал, в противном случае сигнал доходил бы до края общей шины, отражался от него и возвращался в сеть, из-за чего могла возникнуть коллизия, собственно, поэтому компьютерные сети с топологией общая шина были так чувствительны к обрывы кабеля, даже если это кабель идет от шины к конечному устройству, так как важная особенность общей шины заключалась в том, что кадр, отправленный одним конкретным устройством другому, приходил на все устройства, подключенные к общей шине.

Из-за того, что кадры, отправляемые устройством на общую шину, придут на все машины сети, все устройства в такой топологии обязаны проверять: кому предназначен кадр и отбрасывать кадры, если они предназначены не им. Конечно, это не безопасно, и, конечно, это увеличивает нагрузку на сеть.
Для избегания коллизий на сети с общей шиной применяется два метода: первый заключается в том, что в сети определяется главная станция, которая раздает указания всем остальным устройствам сети о том, когда и сколько передавать, второй метод заключается в том, что устройства самостоятельно прослушивают канал и если канал занят, они ничего не делают, если канал свободен, то устройство, если хочет начать передачу данных, сперва отсылает служебный сигнал, в котором сообщает всем остальным участникам о том, что сейчас начнется передача и просит не занимать канал, конечно, тут могут возникнуть разные ситуации и они описаны в документах, связанных с технологией Ethernet, сейчас мы вдаваться в это не будем.
Также стоит заметить, что ранние компьютерные сети, построенные на технологии Ethernet работали в полудуплексном режиме (half duplex), это означает, что по одной линии устройство могло либо передавать, либо принимать информацию, но не было возможности одновременно и передавать, и принимать, для снижения вероятности возникновения коллизий в ранних Ethernet сетях (IEEE 802.3) использовался механизм CSMA/CD (Carrier Sense Multiple Access with Collision Detection или множественный доступ с прослушиванием несущей и обнаружением столкновений), эта как раз та ситуация, когда устройство само слушает канал и ищет свободные окна для передачи данных.
Пожалуй, единственным плюсом общей шины является то, что здесь используется минимальное количество соединительных линий, если сравнивать с другими топологиями компьютерных сетей. В общем-то, это, наверное, все, что следует знать про топологию сети Ethernet с общей шиной, хотя давайте еще посмотрим на физические устройства, которые образуют сеть с топологией общая шина.
На Рисунке 1.18.8 показан коаксиальный Ethernet кабель, который является основным компонентом сети с общей шиной.
Рисунок 1.18.8 Коаксиальный Ethernet кабель
Тут стоит обратить внимание на то, что коаксиальный Ethernet кабель отличается от того кабеля, который используется для предоставления услуг кабельного телевидения, и тут можно запутаться, так как в европейских и американских книгах и источниках можно найти информацию о том, что операторы кабельного телевидения предоставляют услуги доступа в Интернет по тем же коаксиальным линиям, что и телевидение, так вот, это совсем другая технология, отличная от Ethernet, ее мы рассматривать не будем.
Вернемся к нашему коаксиальному кабелю. У него есть медный сердечник, который защищен диэлектриком (белая трубка, в данном случае это полиэтилен) и медной луженной сеткой, которая называется оплетка, от всевозможных внешних помех и наводок, а черная трубка или внешняя оболочка защищает кабель от воздействия внешней среды (пыль, влага, температура, химия), в данном случае это поливинилхлорид. По-умному такой кабель называется RG-58, волновое сопротивление такого кабеля порядка 50 Ом, сейчас его используют в основном в системах видео наблюдения, российский аналог такого кабеля – РК-50.
Остальные пассивные элементы Ethernet сети с топологией общая шина показаны на Рисунке 1.18.9 (про условные обозначения стандартных физических компонентов компьютерной сети можно почитать здесь), каждый элемент снабжен подписью, но давайте дадим еще небольшие пояснения, чтобы закрыть все вопросы окончательно. Я называю элементы пассивными, потому что они не генерируют трафик и никак его не изменяют, они просто выполняют определенные физические задачи.
Рисунок 1.18.9 Пассивные элементы компьютерной сети с топологией общая шина
Итак, первое что стоит заметить – в любой локальной сети, построенной по топологии общая шина имеется ровно два терминатора на концах этой общей шины, один из терминаторов обязательно должен быть заземлен. Для подключения абонентских устройств используется специальный разъем или коннектор, который называется BNC. На Рисунке 1.18.10 показана сетевая карта с портом для подключения Ethernet кабеля.
Рисунок 1.18.10 Сетевая карта компьютера с BNC разъемом для коаксиального Ethernet кабеля
Обратите внимание на то, что к сетевой карте подключен T-коннектор (тройной переходник), таким образом можно последовательно включать несколько устройств друг за другом, если компьютерная сеть состоит ровно из двух участников, то один разъем Т-коннектора включает сетевую карту, в другой разъем включается кабель, а в третий разъем подключается терминатор, который представляет собой балластный резистор сопротивлением 50 Ом.
Если по каким-либо причинам вам не хватило длины кабеля, то для его наращивания используется l-коннектор. Обратите внимание: сейчас мы говорили про сеть Ethernet на тонком коаксиальном кабеле, который используется для объединения компьютеров в локальную сеть, есть еще и толстый Ethernet кабель, который использовался для объединения локальных сетей, об этом вы можете почитать, воспользовавшись Яндексом или Гуглом. На этом мы завершим разговор, который касался непосредственно коаксиального Ethernet кабеля и топологии сети с общей шиной.
1.18.4 Правило четырех хабов и домен коллизий
В этой теме нам осталось поговорить о правиле четырех хабов и разобраться с вопросом: что представляет собой домен коллизий. Начнем мы с правила четырех хабов, так будет проще понять, где образуется у нас домен коллизий и почему он образуется. Вернемся к алгоритму CSMA/CD, сейчас нам важно знать, что этот алгоритм основан на том, что все устройства сети с общей шиной слушают канал и, если он не занят, они отправляют специальную последовательность, которая сообщает всем участникам сети: сейчас начнется передача, не занимайте пожалуйста канал.
И тут нам не стоит забывать, что биты по проводу передаются не мгновенно, это означает, что кадр из точки А в точку Б будет передаваться за определенный промежуток времени и чем больше этот кадр, тем дольше он будет передаваться, собственно, правило четырех хабов гласит о том, что в одном широковещательном домене (в одной подсети), должно быть не более четырех хабов, иначе механизм CSMA/CD может не сработать и произойдет коллизия, например, у вас есть сеть, в которой шесть хабов, к каждому хабу подключено по два ПК, эта сеть показана на Рисунке 1.18.11.
Рисунок 1.18.11 Схема Ethernet сети с шестью хабами
И допустим, что компьютер 192.168.1.2 хочет начать обмениваться данными с компьютером 192.168.1.11 и отправляет в сеть специальную последовательность, а в это время компьютер 192.168.1.12 тоже начинает свою передачу данных, так как последовательность от компьютера 192.168.1.2 не успела дойти до 192.168.1.12, так как он был очень далеко, естественно происходит коллизия. Если машины начали передачу одновременно, то с наибольшей вероятностью коллизия происходит на участке между третьим и четвертым хабом, режим симуляции Cisco Packet Tracer это подтверждает, посмотрите на Рисунок 1.18.12.
Рисунок 1.18.12 Участок компьютерной сети, на котором происходит коллизия
Обратите внимание: хабы глупые устройства, они не умеют проверять целостность кадров, они их просто повторяют на все свои порты, кроме того порта, из которого кадр пришел. Хотя на самом деле хабы даже не знают о существование кадров, они транслируют последовательность бит, пришедшую на один порт, во все остальные порты, таким образом передача не прерывается, а искаженные кадры продолжают свое движение по сети до конечной точки и только конечное устройство сможет понять, что произошла коллизия и только тогда вступит в действие механизм CSMA/CD. Искаженный кадр отмечен огоньком на Рисунке 1.18.13.
Рисунок 1.18.13 Поврежденный в результате коллизии Ethernet кадр отмечен огоньком
Внутрь кадра можно заглянуть, нажав на него два раза левой кнопкой мышки, появится окно, в котором нужно выбрать вкладку OSI Model на этой вкладке можно посмотреть, что делает устройства с полученной информацией на разных уровнях модели OSI, в данном случае обработка идет только на физическом уровне модели OSI, так как информация проходит через хаб и хаб не видит, что произошла коллизия, об этом можно узнать по логу сообщений снизу, который на Рисунке 1.18.14 подсвечен синим, две других вкладки в этом окне позволяют увидеть структуру кадров и пакетов, нам это пока не нужно.
Рисунок 1.18.14 Хаб не смог определить, что Ethernet-кадр поврежден коллизией
Давайте посмотрим, что будет на этапе, когда отправленные кадры дойдут до получателей. Наша сеть будет выглядеть так, как показано на Рисунке 1.18.5.
Рисунок 1.18.15 Искаженный коллизией Ethernet-кадр дошел до конечного узла
А теперь посмотрим, что у нас внутри кадра и что как его обработал компьютер. Для этого нажмем на одном из кадров два раза левой кнопкой мыши, показано на Рисунке 1.18.16.
Рисунок 1.18.16 Искаженный коллизией кадр внутри конечного узла
Здесь мы видим, что конечный узел получил битовую последовательность, а при попытке собрать из битовой последовательности кадр, он обнаружил, что тот искажен коллизией и просто отбросил его, об этом нам говорит вторая запись, подсвеченная синим цветом. Далее компьютер запустит механизм CSMA/CD и тем самым узлы начнут договариваться о времени передачи данных. Мы сейчас не вдаемся в механизм CSMA/CD и не пытаемся понять, как узел определяет, что кадр битый, нам сейчас важно понять следующее: чем больше хабов в нашей компьютерной сети, тем больше вероятность возникновения коллизий, а раз так, то и больше время передачи данных, ведь узлам будет сложнее договориться о последовательности и времени передачи данных. Таким образом, пропускная способность компьютерной сети с хабами заметно снижается, как впрочем и другие важные характеристики компьютерной сети (пожалуй, за исключением стоимости).
Обратите внимание: правило четырех хабов не гарантирует, что коллизий в сети, в которой установлено не больше четырех хабов не будет, это правило гарантирует, что число коллизий в сети, в которой количество хабов больше четырех, сильно возрастет. Теперь перейдем к домену коллизий, сразу заметим, что в нашей схеме, с которой мы только что работали домен коллизий – это вся наша сеть, то есть вся наша сеть – это один большой домен коллизий, то есть участок, на котором может произойти наложение пакетов и кадров.
Если быть более формальным, то домен коллизий — это часть сети Ethernet, все узлы которой конкурируют за общую разделяемую среду передачи и, следовательно, каждый узел которой может создать коллизию с любым другим узлом этой части сети. Другими словами: домен коллизий – это участок сети, на котором в один момент времени может передавать только одно устройство, все остальные должны слушать и принимать, в противном случае произойдет наложение пакетов. Тут сразу можно сделать вывод: чем больше узлов на таком участке сети, тем выше вероятность возникновения коллизий, а еще в сетях half duplex невозможно реализовать сетевое взаимодействие типа h3H, так как оно подразумевает, что обе стороны могут одновременно и передавать и получать данные.
В современных компьютерных сетях с коммутаторами, порты которых работают в полнодуплексном режим (full duplex, этот режим означает, что устройства могут одновременно принимать и отправлять данные), доменов коллизий нет, за исключением ситуации, когда происходит рассинхронизация портов, например, порт коммутатора работает в режиме full duplex, а порт клиентского устройства по каким-то причинам перешел в режим half duplex, тогда домен коллизии ограничен портом коммутатора, также, если коммутатор и клиентское оборудование согласовали режим half duplex, домен коллизий ограничен портом коммутатора, но вероятность того, что коллизия возникнет очень мала, так как порт коммутатора имеет входные и выходные буферы, где кадры могут накапливаться и ждать своей очереди на отправку, впрочем, как и порт клиентского оборудования.
1.18.5 Выводы
Итак, мы осуществили небольшой исторический экскурс, во время которого мы обозначили некоторые темы, с которыми будем разбираться в части посвященной технологии Ethernet, но самое главное мы должны были сделать два вывода:
- В современных компьютерных сетях не стоит использовать хабы, повторители и сетевые концентраторы, так как благодаря этим устройствам физического уровня появляются домены коллизий, ошибки с которыми очень неприятно работать.
- В современных компьютерных сетях не стоит использовать коаксиальный Ethernet кабель, так как такие сети имеют все недостатки, которые есть у хабов, плюс добавляют несколько своих технических минусов.
Используя коммутаторы и витую пару вы можете забыть о доменах коллизий, правиле четырех хабов и всех тех неурядицах, которые были связаны с этими устройствами.
«Шина» — топология сети: достоинства, недостатки
Придя в различные компании, можно обратить внимание на то, что сеть там обустроена по-разному – где-то используется «звезда», где-то — «кольцо», а где-то — «шина». Топология сети достаточно сильно влияет на качество и скорость обмена данными между компьютерами, но при этом многие зачастую не знают основных преимуществ и недостатков каждого отдельного варианта.
Что это такое?
Несмотря на то что именно этот вариант сегодня является наиболее распространенным, термин «топология» не предусматривает только технологию «шина». Топология сети представляет собой просто объединение нескольких компьютеров в сети, поэтому ее можно назвать аналогичным вариантом таких понятий, как конфигурация, или структура сети. Помимо этого, в понятии «топология» заключено также большое количество правил, которыми определяются места размещения компьютеров, технологии прокладки кабеля и размещения связующего оборудования, а также еще масса других моментов.
Какой она может быть?
На сегодняшний день сформировалось три основных варианта такого объединения компьютеров – это «звезда», «кольцо» и «шина». Топология в каждом отдельном случае является отличной от остальных, а также имеет свои особенности и преимущества. Именно поэтому важно знать эти тонкости перед тем, как проводить сеть между компьютерами на том или ином объекте.
«Шина»
По технологии «шина» топология предусматривает использование единственного кабеля, при помощи которого объединяются между собой все использующиеся рабочие станции.
Таким образом, один-единственный кабель применяется каждой станцией по очереди, а все сообщения, которые отправляются этими станциями, могут быть приняты и прослушаны любым компьютером, который находится в данной сети. Из этого потока все рабочие станции отбирают только те сообщения, которые изначально были адресованы именно им.
В чем преимущества?
Достоинства топологии «шина» являются следующими:
- Настройка является предельно простой для любого продвинутого пользователя.
- Система достаточно просто устанавливается и при этом обуславливает минимум финансовых затрат, если все рабочие станции располагаются на небольшом расстоянии между собой.
- Если ломается или же начинает давать сбой какая-то конкретная станция в сети, все остальные продолжают работать в прежнем режиме без каких-либо проблем.
В чем недостатки?
Также есть и недостатки топологии «шина»:
- Если возникает неполадка в каком-нибудь месте, моментально выходит из строя полностью вся сеть.
- Достаточно сложно найти какие-либо неполадки в случае их возникновения.
- Довольно низкая производительность по сравнению с остальными технологиями. Это обуславливается тем, что топология сети «шина» предусматривает одновременную передачу данных только с одного компьютера, а если же количество рабочих станций увеличивается, параллельно снижается производительность используемой сети.
- Неважная масштабируемость. Чтобы добавить новые рабочие станции, нужно полностью заменить участки уже используемой «шины».
Именно данная технология использовалась для подключения компьютеров в локальную сеть при использовании коаксиального кабеля. В данном случае в роли «шины» использовались отрезки коаксиального кабеля, объединенные между сбой при помощи Т-коннекторов. «Шина» прокладывается полностью через все помещение, после чего подключается к каждому отдельному компьютеру, а боковой вывод коннектора вставляется в разъем, установленный на сетевой карте.
В связи с тем, что такое оборудование уже безнадежно устарело, а более широкое распространение получила топология сети «звезда», «шина» практически не используется, но ее по сегодняшний день можно встретить на различных предприятиях.
«Кольцо»
«Кольцо» представляет собой такую топологию локальной сети, в соответствии с которой различные все рабочие станции объединяются между собой последовательно, образуя полностью замкнутый круг. В такой сети данные транслируются от одной рабочей станции к другой в единственном направлении, при этом каждый отдельный компьютер работает как повторитель, осуществляя ретрансляцию сообщения к следующему, образуя таким образом своеобразную эстафету. Такая система уже имеет мало общего с тем, что представляет собой топология «общая шина», в связи с чем имеет массу своих особенностей и преимуществ.
В чем преимущества?
- Компьютеры достаточно просто объединяются в сеть.
- Практически нет никакой необходимости в том, чтобы использовать дополнительное оборудование.
- Можно добиться стабильной работы без какого-либо заметного падения скорости транслирования данных при серьезной загрузке сети.
- Любая рабочая станция должна активно использоваться в процедуре передачи данных, и если сломается хотя бы один компьютер, или же в определенном месте оборвется кабель, вся система полностью перестанет функционировать.
- Если будет подключаться новая рабочая станция, сеть нужно на определенное время выключить, так как требуется размыкание кольца в процессе установки нового оборудования.
- Система отличается достаточно сложной конфигурацией и настройками.
- При возникновении тех или иных неисправностей даже специалистам достаточно сложно найти, в чем именно заключается неполадка.
В чем недостатки?
В связи с этими минусами сегодня не так часто можно встретить использование кольцевой топологии, и наиболее часто она встречается в оптоволоконных сетях стандарта Token Ring.
«Звезда»
Если каждая рабочая станция подключена непосредственно к центральному устройству, которым может служить маршрутизатор или же коммутатор, то это топология «звезда». «Шина» была с течением времени заменена именно этой технологией, так как она отличается более высокой производительностью и эффективностью. Данная технология предусматривает управление всеми движениями пакетов в сети непосредственно центральным устройством, а каждый компьютер через собственную сетевую карту подключается к данному коммутатору полностью отдельным кабелем.
В случае необходимости можно объединить в одно целое одновременно несколько сетей, использующих описываемую топологию, вследствие чего в результате получится конфигурация сети, имеющая древовидную топологию. Древовидная топология распространяется в крупных организациях, однако она отличается целым рядом своих особенностей и тонкостей реализации.
Топология «звезда» на сегодняшний день используется в качестве основы при построении практически всех локальных сетей, и, в частности, это является результатом целого ряда преимуществ данной технологии объединения компьютеров.
В чем преимущества?
- Если ломается какая-либо конкретная станция (или же повреждается ее кабель), на работе в целом всей сети это никак не сказывается, то есть все остальное оборудование продолжает стабильно работать.
- Прекрасная масштабируемость. Для того чтобы подключить новую рабочую станцию, нужно просто проложить отдельный кабель от коммутатора.
- Достаточно просто можно найти, и после этого устранить неисправности или же какие-либо обрывы в сети.
- Предельно высокая производительность, особенно если сравнивать с аналогичными вариантами топологии.
- Идеальная простота настройки и администрирования всего оборудования.
- В сеть без труда можно встроить дополнительные устройства.
- Если ломается центральный коммутатор, вся сеть перестает работать.
- Чтобы использовать сетевое оборудование, нужно выделить также дополнительные затраты, так как требуется приобретение отдельного устройства, к которому будут подключаться все компьютеры, подключенные к сети.
- Количество рабочих станций ограничивается количеством портов в используемом центральном коммутаторе.
В чем недостатки?
На сегодняшний день «звезда» является наиболее распространенной технологией для современных проводных или же беспроводных сетей. В качестве примера звездообразной топологии можно представить сеть, использующую кабель типа «витая пара», а также коммутатор, который представляет собой центральное устройство. Именно такие сети часто сегодня можно встретить в преимущественном большинстве компаний.
Топология и ее многозначительность
Топология сети позволяет определить не только физическое расположение компьютеров, но, что еще более важно, обеспечивает характер связи между ними, а также различные особенности распространения сигналов через сеть. Именно характером связи можно определить то, насколько отказоустойчивой является сеть, а также узнать требуемую сложность сетевой аппаратуры и наиболее актуальный метод управления обменом и множество других параметров. Если в литературе рассматривается топология локальных сетей «шина» или же другие технологии, то может предусматриваться четыре абсолютно разных понятия, которые относятся к разным типам сетевой архитектуры:
- Физическая – схема расположения компьютеров, а также прокладки объединяющих их кабелей. В таком ключе пассивная «звезда» не имеет никаких отличий от активной, в связи с чем технология чаще всего называется просто «звезда».
- Логическая – структура связей, а также то, каким образом сигналы распространяются по сети. Данное определение топологии, наверное, можно назвать наиболее правильным.
- Управления обменом – принцип, а также последовательность передачи права на расторжение сетевой связи между определенными компьютерами.
- Информационная – направление информационных потоков, которые передаются через сеть.
К примеру, сеть, имеющая физическую и логическую топологию формата «шина», может в качестве управления использовать эстафетную технологию передачи права захвата сети, а также обеспечить одновременную передачу всех данных через определенный выделенный компьютер. И в таком содержании представлять собой технологию «звезда».
Топология «общая шина»
Рис.1 топология шина
Сеть с топологией шина использует один канал связи, объединяющий все компьютеры сети.
Самым распространенным методом доступа в сетях этой топологии является метод доступа с прослушиванием несущей частоты и обнаружением конфликта. При этом методе доступа, узел прежде чем послать данные по коммуникационному каналу, прослушивает его и только убедившись, что канал свободен, посылает пакет. Если канал занят, узел повторяет попытку передать пакет через случайный промежуток времени. Данные, переданные одним узлом сети, поступают во все узлы, но только узел, ля которого предназначены эти данные, распознает и принимает их. Несмотря на предварительное прослушивание канала, в сети могут возникать конфликты, заключающиеся в одновременной передачи пакетов двумя узлами. Конфликты связана с тем, что имеется временная задержка сигнала при прохождении его по каналу: сигнал послан, но не дошел до узла, прослушивающего канал, в следствие чего узел счел канал свободным и начал передачу.
Характерным примером сети с этим методом доступа является сеть Ethernet. В сети Ethernet обеспечивается скорость передачи данных для локальных сетей, равная 100 Мбит/сек.
Топология шина обеспечивает эффективное использование пропускной способности канала, устойчивость к неисправности отдельных узлов, простоту реконфигурации и наращивания сети.
Общая шина является очень распространенной (а до недавнего времени самой распространенной) топологией для локальных сетей. Передаваемая информация может распространяться в обе стороны. Применение общей шины снижает стоимость проводки, унифицирует подключение различных модулей, обеспечивает возможность почти мгновенного широковещательного обращения ко всем станциям сети. Таким образом, основными преимуществами такой схемы являются дешевизна и простота разводки кабеля по помещениям. Самый серьезный недостаток общей шины заключается в ее низкой надежности: любой дефект кабеля или какого-нибудь из многочисленных разъемов полностью парализует всю сеть. К сожалению, дефект коаксиального разъема редкостью не является. Другим недостатком общей шины является ее невысокая производительность, так как при таком способе подключения в каждый момент времени только один компьютер может передавать данные в сеть. Поэтому пропускная способность канала связи всегда делится здесь между всеми узлами сети.
Топология «звезда»
Рис.2 Топология звезда
Сеть звездообразной топологии имеет активный центр (АЦ) – компьютер (или иное сетевое устройство), объединяющий все компьютеры в сети. Активный центр полностью управляет компьютерами, подключенными к нему через концентратор, которой выполняет функции распределения и усиления сигналов. В функции концентратора входит направление передаваемой компьютером информации одному или всем остальным компьютерам сети. От надежности активного центра полностью зависит работоспособность сети.
В качестве примера метода доступа с АЦ можно привести Arcnet. Этот метод доступа также использует маркер для передачи данных. Маркер предается от узла к узлу (как бы по кольцу), обходя узлы в порядке возрастания их адресов. Как и в кольцевой топологии, каждый узел регенерирует маркер. Этот метод доступа обеспечивает скорость передачи данных 2 Мбит/сек.
Главное преимущество этой топологии перед общей шиной — существенно большая надежность. Любые неприятности с кабелем касаются лишь того компьютера, к которому этот кабель присоединен, и только неисправность концентратора может вывести из строя всю сеть. Кроме того, концентратор может играть роль интеллектуального фильтра информации, поступающей от узлов в сеть, и при необходимости блокировать запрещенные администратором передачи.
К недостаткам топологии типа звезда относится более высокая стоимость сетевого оборудования из-за необходимости приобретения концентратора. Кроме того, возможности по наращивания количества узлов сети ограничиваются количеством портов концентратора. Иногда имеет смысл строить сеть с использованием нескольких концентраторов, иерархически соединенных между собой связями типа звезда.
общая шина — это… Что такое общая шина?
общая шина — 1. Шина универсального применения, используемая в режиме разделения времени и соединяющая периферийные устройства с процессором и памятью. 2. Высокоскоростная магистраль, связывающая входные и выходные порты коммутатора. Во избежание блокировки… … Справочник технического переводчика
общая шина — bendroji magistralė statusas T sritis automatika atitikmenys: angl. common bus; unibus; unified bus vok. gemeinsamer Bus, m; Uni Bus, m; Uni Leitung, m rus. общая шина, f pranc. bus commun, m … Automatikos terminų žodynas
общая шина управления — Интерфейс сетевого управления Bay Networks в концентраторах System 5000 и Distributed 5000, который также поддерживает связь с модулями других типов. [http://www.lexikon.ru/dict/net/index.html] Тематики сети вычислительные EN common management… … Справочник технического переводчика
шина (в электротехнике) — шина Проводник с низким сопротивлением, к которому можно подсоединить несколько отдельных электрических цепей. Примечание — Термин «шина» не включает в себя геометрическую форму, габариты или размеры проводника. [ГОСТ Р 51321.1… … Справочник технического переводчика
шина (в электротехнике) — шина Проводник с низким сопротивлением, к которому можно подсоединить несколько отдельных электрических цепей. Примечание — Термин «шина» не включает в себя геометрическую форму, габариты или размеры проводника. [ГОСТ Р 51321.1… … Справочник технического переводчика
Шина (топология компьютерной сети) — У этого термина существуют и другие значения, см. Шина (значения). Топология типа общая шина, представляет собой общий кабель (называемый шина или магистраль), к которому подсоединены все рабочие станции. На концах кабеля находятся терминаторы,… … Википедия
Шина PCI Express — На фотографии 4 слота PCI Express: x4, x16, x1, опять x16, внизу стандартный 32 разрядный слот PCI, на материнской плате DFI LanParty nForce4 SLI DR PCI Express или PCIe или PCI E, (также известная как 3GIO for 3rd Generation I/O; не путать с PCI … Википедия
S-100 (шина данных) — S 100 Универсальная интерфейсная шина спроектированная компанией MITS в 1974 году специально для Altair 8800, считающимся на сегодняшний день первым персональным компьютером. Шина S 100 была первой интерфейсной шиной для микрокомпьютерной… … Википедия
полевая шина — [Интент] полевая магистраль по зарубежной терминологии Имеет много терминов синонимов и обозначает специализированные последовательные магистрали малых локальных сетей (МЛС), ориентированны на сопряжение с ЭВМ рассредоточенных цифровых датчиков и … Справочник технического переводчика
полевая шина — [Интент] полевая магистраль по зарубежной терминологии Имеет много терминов синонимов и обозначает специализированные последовательные магистрали малых локальных сетей (МЛС), ориентированны на сопряжение с ЭВМ рассредоточенных цифровых датчиков и … Справочник технического переводчика
полевая шина — [Интент] полевая магистраль по зарубежной терминологии Имеет много терминов синонимов и обозначает специализированные последовательные магистрали малых локальных сетей (МЛС), ориентированны на сопряжение с ЭВМ рассредоточенных цифровых датчиков и … Справочник технического переводчика
Общая шина предприятия | Открытые системы. СУБД
В стремительном процессе эволюции компьютерных технологий иногда совершенно неожиданно раскрываются новые возможности старых идей. Например, такой, как, казалось бы, давно забытая память на ферритовых сердечниках. При всех недостатках ее положительным качеством была способность запоминать и сохранять данные бесконечно долго без подпитки — в отличие от современных модулей RAM на полупроводниках. И вот буквально на наших глазах она возрождается в виде многообещающей технологии MRAM, в которой точно так же используется двухпозиционность петли магнитного гистерезиса. Следовательно, она будет сохранять свое состояние без питания. С возрождением магнитной памяти уйдет в прошлое такая привычная процедура загрузки компьютера.
Нечто подобное происходит и с магистралями обмена данными, построенными по принципу «общей шины». Сейчас трудно оценить революционность идеи общей шины, а ведь в свое время это был настоящий переворот. Общая шина Unibus, предложенная три десятка лет назад инженерами корпорации Digital Equipment в качестве архитектурной основы для миниЭВМ PDP-11, оказалась чрезвычайно эффективным (а главное, дешевым) средством интеграции разнотипных устройств. В последующем на шинном принципе было построено множество компьютеров, в том числе все современные ПК. Собственно, с общей шины и начал формироваться рынок периферийных устройств. Однако со временем шины, используемые в качестве центрального архитектурного элемента компьютера, стали уступать свое место более быстродействующим коммутаторам, оставаясь при этом одним из основных вариантов подключения периферийных устройств. Сегодня шина, которую называют Enterprise Service Bus (ESB), может сыграть примерно ту же роль, что и шина Unibus, со всеми достоинствами, но на более высоком уровне.
События и в самом деле развиваются стремительно. Всего лишь год назад один из ведущих аналитиков Gartner Group Ефим Натис высказал следующее предположение: «Один из основных подходов к созданию корпоративной инфраструктуры приложений строится с использованием слабосвязанных асинхронных процессов». А уже в октябре 2002 года в еженедельнике InfoWorld в статье Джона Уделла можно было прочитать: «Теперь, когда мы все согласны с тем, что Web-службы должны взаимодействовать в асинхронной манере, стало ясно, что программное обеспечение промежуточного слоя, ориентированное на обмен сообщениями (message-oriented middleware, MOM), приобретает решающее значение».
Как видим, всего за год предположение превратилось в утверждение. В том, что это произошло, заметную роль сыграла компания Sonic Software, образованная несколькими выходцами из BEA Systems и сегодня признаваемая в качестве одного из лидеров в разработке программного обеспечения промежуточного слоя. Очень интересные работы проделаны еще в нескольких небольших компаниях (например, Collaxa), однако Sonic одной из первых предложила свою реализацию слабосвязанных асинхронных процессов. При всей новизне, в своем программном продукте SonicXQ ESB компания, по сути, реализует старую, заимствованную у миниЭВМ идею общей шины, но при этом воплощает ее в новом обличии.
В данном случае ESB является общей в том смысле, что объединяет все приложения предприятия. ESB, реализованная с использованием архитектуры SOA (Service-Oriented Architecture), предназначена для интеграции корпоративных приложений на основе ориентированных на документы асинхронных Web-служб и J2EE Connector Architecture (JCA). Две этих технологии обеспечивают контентную маршрутизацию сообщений и позволяют так организовать взаимодействие между приложениями, и так интегрировать управление бизнес-процессами, что появляется возможность обойтись без дорогостоящих брокеров.
Оригинальность разработки SonicXQ привлекала к себе значительное внимание. Исторически первыми появились интеграционные брокеры (иногда их называют интеграционными серверами). Решения, построенные на основе интеграционных брокеров, можно представить в виде коммутаторов. С их помощью формируется некоторый гипотетический метакомпьютер, где все управление строится по централизованному принципу. В результате получается что-то вроде гипер-мэйнфрейма. Sonic совершила примерно то же самое, что DEC, предложившая три десятилетия назад шинные миниЭВМ в качестве недорогой альтернативы мэйнфремам; решение Sonic позволяет построить своего рода метакомпьютер для всего предприятия, но более дешевый. В итоге получается аналог мини-метакомпьютера: вместо дорогого коммутатора предлагается информационная магистраль предприятия Enterprise Service Bus.
Технология SonicXQ появилась не вдруг. У нее два достаточно хорошо известных источника. Первый — программное обеспечение промежуточного слоя на основе сообщений. Этот тип программного инструментария переживает настоящую реинкарнацию, особенно в связи с появлением Java Message Service от компании Sun Microsystems. О происходящем на этом фронте можно прочитать в [1], а более подробно о SonicMQ, непосредственном предшественнике SonicXQ, — в [2]. Обе эти публикации сохраняют актуальность, но за прошедший год пейзаж корпоративного программного обеспечения заметно изменился, особенно под воздействием Web-служб. Еще год назад, когда готовились указанные публикации, представление о том, что такое Web-службы и каково их значение, было достаточно расплывчатым. За прошедшее время ситуация заметно прояснилась, и Web-службы следует назвать в качестве второго источника SonicXQ.
Enterprise Service Bus
Среди событий прошедшего года следует отметить появление в профессиональной терминологии нечто нового и непривычного. Одни, приверженцы лагеря Micrososft/IBM, называют это «оркестровкой» (orchestration) Web-служб, другие, из лагеря Sun/BEA, — «хореографией» (choreography) [3]. Разгорается очередная битва в войне стандартов, за то, как лучше наладить согласованную работу корпоративных приложений с использованием Web-служб. Причина новой активности заключена в том, что всем, наконец, стало ясно: в сложившихся условиях исчерпаны возможности жестко связанных приложений, сложность систем стала слишком велика. Однако исходная схема распространения Web-служб с использованием построенных по стандарту UDDI репозиториев оказалась малоприменимой для корпоративных целей. В то же время, Web-службы и особенно их асинхронные ориентированные на документы версии предлагают реальный выход из «тупика сложности». С технической точки задача создания корпоративной инфраструктуры приложений с использованием слабосвязанных асинхронных процессов имеет несколько альтернативных решений.
Enterprise Service Bus, построенная на основе SonicXQ является одним из них. С помощью формируемой SonicXQ корпоративной магистрали реализуется распределенная архитектура, ориентированная на службы. ESB позволяет создавать контейнеры для размещения служб. Службы легко собрать и согласовать, поскольку упакованная в контейнер и являющаяся частью ESB служба представима другим частям ESB. При этом вся конструкция является виртуальной; реальная физическая сеть, в которой она «живет», может подвергаться изменениям без потери функциональности.
| Рис. 1. Enterprise Service Bus — информационная магистраль предприятия |
В процессе функционирования ESB одна или несколько связанных служб находятся в специальном контейнере (service container). Контейнеры являются средством для продвижения служб по распределенному процессу в соответствии с маршрутами сообщений (message itinerarу). Процедура прохождения сообщения выглядит следующим образом. Сообщение поступает на вход шины ESB. Здесь к нему добавляется маршрут, который позволяет организовать контентно-управляемое продвижение по распределенному процессу, этот процесс имеет децентрализованное управление. В рамках этого процесса сообщение проходит через ряд служб, достигая конечной точки, где извлекается из контейнера.
Для указания конечных точек могут быть использованы не физические, а логические имена. Установление соответствия между физическими и логическими именами (mapping) осуществляет специальный имеющийся в составе ESB механизм. Таким образом, в архитектуру изначально заложена способность к виртуализации; система может изменяться без модификации кода и разрушения действующих бизнес-процессов. Конфигурация допускает несколько уровней качества обслуживания (Quality of Service, QoS), гарантирующих надежное прохождение сообщений между приложениями. В общем случае, когда сообщение проходит весь свой маршрут, оно выходит за конечную точку получателя, а отправителю посылается подтверждающее получение сообщение. Достоинство распределенного процесса передачи сообщений на основе ESB заключается в том, что по своей логике он очень близок взаимодействию в реальном мире.
Основы: JCA и Web-службы
Предлагаемая в ESB интеграция приложений стала возможной благодаря появлению архитектуры соединений JCA от Sun Microsystems и SOAP, стандартного протокола для Web-служб. JCA, специально разработанная для преодоления сложностей, связанных с интеграцией приложений, предлагает стандартизированные методы для решения этой задачи. Корпоративная информационная система, построенная по принципам JCA, использует для доступа к приложениям интерфейс JDBC. Сегодня этот подход весьма популярен; большинство современных серверов приложений, в том числе, BEA WebLogic и IBM WebSphere поддерживают адаптеры JCA. Кроме того, многие поставщики пакетных решений намерены поддерживать JCA в будущих версиях своих продуктов.
Оригинальность использования Web-служб в SonicXQ заключается в том, как организован процесс «оркестровки» (или «хореографии»). В его основе лежит протокол SOAP, но наложенный на простой и масштабируемый формат сообщений. При этом SonicXQ Enterprise Service Bus обеспечивает совместимость и с асинхронной документальной моделью SOAP (document asynchronous model), так и с синхронной моделью SOAP, построенной по принципу вызова удаленных процедур (RPC). В SonicXQ службы описываются на языке WSDL, но WSDL непосредственно интегрирован Distributed Processing Framework. В результате служба может быть зарегистрирована во внешнем каталоге UDDI, а может и не быть, если в этом нет необходимости.
Технологию SonicXQ можно без всякого преувеличения назвать экстремальной: она собрала в себе целый ряд современных тенденций в корпоративных вычислениях. Но, пожалуй, самое интересное заключается в том, что она позволяет лучше понять, что такое Web-службы. Причем не на словах, а на деле.
Литература
1. Леонид Черняк. МОМ, второе рождение // Открытые системы, 2001, № 1
2. Валерий Коржов. Почтальон для приложений // Открытые системы, 2001, № 10
3. Stuart J. Johnston, Web Services Wars Take Artistic Turn. Choreography or orchestration? XML Magazine, 2002, № 10/11
Поделитесь материалом с коллегами и друзьями
Организация и архитектура компьютеров (система общей шины)
Базовый компьютер имеет восемь регистров , блок памяти и блок управления. Необходимо указать пути для передачи информации из один регистр в другой и между памятью и регистрами.
Количество количество проводов будет превышено , если между выходами каждого регистр и входы других регистров.
Более эффективная схема для передача информации в системе с множеством регистров — это использование общего автобус.
Подключение регистров и памяти Базовый компьютер, подключенный к общей системе шин, показан на рис. ниже. Выходы семи регистров и памяти подключены к общему автобус.
Конкретный выход , который выбирается для автобусных линий в любой момент времени, равен определяется из двоичного значения переменных выбора S 2 , S 1 и S 0 .
число на каждом выходе показывает десятичный эквивалент требуемого двоичного выбор.Например, число на выходе DR — 3.
16-битный выходы DR помещаются на линии шины, когда S 2 S 1 S 0 = 011, так как это двоичное значение десятичного числа 3.
Линии общей шины подключены к входы каждого регистра и входы данных памяти. Особый регистр, для которого включен вход LD (load), принимает данные с шины во время переход следующего тактового импульса.
Память принимает содержимое шины когда его вход записи активирован. Память помещает свой 16-битный вывод на шина, когда вход чтения активирован и S 2 S 1 S 0 = 111.
Четыре регистра , DR, AC, IR и TR имеют по 16 бит каждый. Два регистра, AR
и ПК, имеют 12 бит каждый, поскольку они содержат адрес памяти.Когда содержимое AR или PC подается на 16-битную общую шину, четыре самых значимые биты установлены в 0.
Когда AR или ПК получают информацию от шины, в регистр передаются только 12 младших битов. Входной регистр INPR и выходной регистр OUTR имеют по 8 бит каждый. и связываться с восемью младшими битами в шине.
INPR — это подключен для передачи информации на шину, но OUTR может только получать информацию из автобуса.
Это потому, что INPR получает символ из входа устройство, которое затем переводится в AC. OUTR получает символ от AC и доставляет его на устройство вывода. Нет передачи из OUTR ни в один из другие регистры.
16 линий общей шины получают информацию из шести регистров и блок памяти. Линии шины подключены ко входам шести регистров и память. Пять регистров имеют три управляющих входа: LD (нагрузка), INR (приращение), и CLR (чистый).
Этот тип регистра эквивалентен двоичному счетчику с параллельной нагрузкой и синхронной очисткой. Операция приращения достигается включением счетного входа счетчика. Два регистра имеют только вход LD.
Входные данные и выходные данные памяти подключены к общая шина, но адрес памяти подключен к AR. Следовательно, AR должен всегда использоваться для указания адреса памяти.
Используя единственный регистр для адреса, мы устраняем необходимость в адресной шине, которая была бы необходимо в противном случае.Для памяти можно указать содержимое любого регистра. ввод данных во время операции записи. Точно так же любой регистр может получать данные из памяти после операции чтения, кроме AC.
16 входов AC поступают от сумматора и логической схемы. Эта схема имеет три набора входов. Один набор 16-битных входов поступает с выходов переменного тока. Они используются для реализации микроопераций регистров, таких как дополнение AC и сдвиг переменного тока.
Другой набор 16-битных входов поступает из регистра данных DR.В входы от DR и AC используются для арифметических и логических операций, таких как как добавить DR к AC или AND DR к AC.
Результат сложения передается в AC, а окончание сложения переносится на триггер E (расширенный Бит переменного тока). Третий набор 8-битных входов поступает из входного регистра INPR.
Обратите внимание, что содержимое любого регистра может быть применено к шине и операция может выполняться в сумматоре и логической схеме в течение одних и тех же часов цикл.Тактовый переход в конце цикла передает содержимое шину в назначенный регистр назначения и выход сумматора и логическая схема в переменный ток.
Например, , две микрооперации
DR ← AC и AC ← DR
могут быть выполнены одновременно . Это можно сделать, разместив содержимое AC на шине (с S 2 S 1 S 0 = 100), включение входа LD (нагрузка) DR, передача содержимого DR через сумматор и логическую схему в AC, и включение входа LD (нагрузки) переменного тока, все в течение одного тактового цикла.
Два передачи происходят по прибытии перехода тактового импульса в конце такт.
Базовый компьютер имеет три формата кода команд, как показано на рисунке ниже. Каждый формат имеет 16 бит.
Код операции (opcode) часть инструкции содержит три бита, а значение остальных 13 бит зависит от обнаружен код операции.
Инструкция обращения к памяти использует 12 бит для укажите адрес и один бит, чтобы указать режим адресации I. I равен 0 для прямого адреса и до 1 для косвенного адреса.
Ссылка на регистр инструкции распознаются кодом операции 111 с 0 в крайний левый бит (бит 15) инструкции.
Инструкция со ссылкой на регистр указывает операция или проверка регистра переменного тока.Операнд из памяти не нужный; следовательно, остальные 12 битов используются для определения операции или теста для быть казненным.
Аналогично , инструкция ввода-вывода не требует ссылки в память и распознается кодом операции Ill с 1 в крайнем левом бит инструкции. Остальные 12 бит используются для указания типа выполняется операция ввода-вывода или тест.
Тип команды распознается компьютерным управлением из четырех биты в позициях с 12 по 15 инструкции.Если три бита кода операции в позиции с 12 по 14 не равны 111, инструкция является ссылкой на память type, а бит в позиции 15 принимается как режим адресации I.
Если 3-битный код операции равен 111, затем управление проверяет бит в позиции 15. Если этот бит равен 0,
Инструкция — это тип ссылки на регистр. Если бит равен 1, инструкция является тип ввода-вывода.Обратите внимание, что бит в позиции 15 кода инструкции равен обозначается символом I, но не используется как бит режима, когда операция код равен 111.
Только три бита инструкции используются для кода операции. Это может кажется, что компьютер ограничен максимум восемью различными операциями.
Однако , поскольку инструкции по ссылке на регистр и инструкции ввода-вывода используют оставшиеся 12 бит как часть кода операции, общее количество инструкций может превышает восемь.
Фактически , общее количество инструкций, выбранных для основного компьютер равен 25.
Инструкции для компьютера перечислены в таблице ниже. Символ Обозначение представляет собой трехбуквенное слово и представляет собой сокращение, предназначенное для программистов и пользователей. Шестнадцатеричный код равен эквивалентному шестнадцатеричному. номер двоичного кода, используемого для инструкции.
Используя шестнадцатеричный эквивалент мы сократили 16 бит кода инструкции до четырех цифр где каждая шестнадцатеричная цифра эквивалентна четырем битам.
Ссылка на память Инструкция имеет адресную часть из 12 бит. Адресная часть обозначается тремя x и обозначают три шестнадцатеричные цифры, соответствующие 12-битному адресу.
Последний бит инструкции обозначается символом I. Когда I = 0, последний четыре бита инструкции имеют шестнадцатеричный эквивалент от 0 до 6, поскольку последний бит равен 0.
Когда I = I , шестнадцатеричный эквивалент последних четырех бит команды находится в диапазоне от 8 до E, так как последний бит равен I.Команды обращения к регистрам используют 16 битов для определения операции. В крайние левые четыре бита всегда 0111, что эквивалентно шестнадцатеричному 7.
остальные три шестнадцатеричные цифры дают двоичный эквивалент оставшихся 12 биты. Инструкции ввода-вывода также используют все 16 битов для задания операции. Последние четыре бита всегда равны 1111, что эквивалентно шестнадцатеричной системе F.
Компьютер должен иметь набор инструкций , чтобы пользователь мог построить машину языковые программы для оценки любой вычислимой функции.
Набор инструкций считается завершенным, если компьютер включает в себя достаточное количество инструкций в каждой из следующих категорий:
1. Арифметические, логические инструкции и инструкции сдвига 2. Инструкции по перемещению информации в память и процессор и обратно. регистры 3. Инструкции по управлению программой вместе с инструкциями по проверке статусные условия 4. Инструкции по вводу и выводу
Арифметические, логические инструкции и инструкции сдвига обеспечивают вычислительные возможности для обработки данных, которые пользователь может пожелать использовать.
Навалом двоичной информации в цифровом компьютере хранится в памяти, но все вычисления производятся в регистрах процессора.
Следовательно, , пользователь должен иметь возможность перемещения информации между этими двумя блоками. Принимать решение возможности — важный аспект цифровых компьютеров.
Например, , можно сравнить два числа, и если первое больше второго, оно может потребоваться действовать иначе, чем если бы второе было больше, чем первый.
Команды управления программой , такие как инструкции ветвления, используются для изменить последовательность выполнения программы. Ввод и вывод инструкции необходимы для связи между компьютером и пользователем.
Программы и данные должны быть перенесены в память, а результаты вычисления должны быть возвращены пользователю. Инструкции, перечисленные в таблице выше, составляют минимальный набор, который обеспечивает все возможности, упомянутые выше.
Имеется одна арифметическая инструкция , ADD, и две связанные инструкции, дополняющие AC (CMA) и увеличивающие AC (INC).
С помощью этих трех инструкций мы можем складывать и вычитать двоичные числа, когда отрицательные числа находятся в дополнительном представлении со знаком-2. Обращение инструкции, CIR и CIL, могут использоваться для арифметических сдвигов, а также любые другие желаемый тип смен.
Умножение и деление можно выполнить с помощью сложение, вычитание и сдвиг.Есть три логические операции: И, дополнить AC (CMA) и очистить AC (CLA).
И и дополнение обеспечить операцию NAND . Можно показать, что с операцией NAND можно реализовать все остальные логические операции с двумя переменными.
Перемещение информации из памяти в AC выполнено с инструкцией load AC (LDA). Сохранение информации из AC в память выполняется с помощью инструкции сохранения AC (STA).
Инструкции ветвления BUN, BSA, и ISZ вместе с четырьмя инструкциями пропуска предоставляют возможности для программный контроль и проверка статусных условий. Вход (lNP) и выход (OUT) инструкции вызывают передачу информации между компьютером. и внешние устройства.
Хотя набор инструкций для базового компьютера полный, он неэффективно, потому что часто используемые операции не выполняются быстро.An эффективный набор инструкций будет включать такие инструкции, как вычитание, умножение, ИЛИ и исключающее ИЛИ.
Время для всех регистров в базовом компьютере контролируется главными часами. генератор.
Тактовые импульсы применяются ко всем триггерам и регистрам в система, включая триггеры и регистры в блоке управления.
Часы импульсы не изменяют состояние регистра, если регистр не активирован управляющим сигналом.
Управляющие сигналы генерируются в блоке управления и обеспечить входы управления для мультиплексоров на общей шине, входы управления в регистрах процессора и микрооперации для аккумулятора.
Существует два основных типа контрольной организации: аппаратный контроль и микропрограммное управление. В аппаратной организации логика управления реализован с помощью вентилей, триггеров, декодеров и других цифровых схем.
Имеет преимущество в том, что его можно оптимизировать для обеспечения быстрого режима работы.
В микропрограммной организации управляющая информация хранится в Контрольная память. Управляющая память запрограммирована на запуск необходимого последовательность микроопераций.
Проводное управление , как следует из названия, требует изменения в проводке между различными компонентами, если в конструкции есть быть измененным или измененным.В микропрограммном управлении любые необходимые изменения или модификации могут быть сделаны путем обновления микропрограммы в управлении объем памяти.
Блок-схема блока управления представлена на рис. Ниже. Это состоит из два декодера, счетчик последовательностей и несколько логических вентилей управления. An инструкция, прочитанная из памяти, помещается в регистр инструкций (IR).
Положение этого регистра в системе общей шины указано на рис.ранее видел. В регистр команд снова показан на рис. ниже, где он разделен на три части: бит I, код операции и биты с 0 по 11.
Код операции в битах с 12 по 14 декодируются декодером 3 x 8. Восемь выходов декодер обозначен символами от D0 до D7.
Индексный десятичное число эквивалентно двоичному значению соответствующей операции код.Бит 15 инструкции передается на триггер, обозначенный символ I.
Биты с 0 по 11 применяются к логическим элементам управления. 4-битный счетчик последовательностей может считать в двоичном формате от 0 до 15. Выходы счетчик декодируются в 16 синхронизирующих сигналов с T0 по T15
Счетчик последовательностей SC может увеличиваться или очищаться синхронно.
. В большинстве случаев счетчик увеличивается до обеспечивают последовательность сигналов синхронизации из декодера 4 x 16.Однажды в некоторое время счетчик сбрасывается до 0, в результате чего следующий активный сигнал синхронизации будет T0.
В качестве примера рассмотрим случай, когда SC увеличивается для обеспечения синхронизации последовательно сигнализирует Т0, Т1, Т2, Т3 и Т4. В момент T4 SC сбрасывается в 0, если декодер выход D3 активен.
Это выражается символически с помощью утверждения D3T4: SC ← 0. Временная диаграмма на Рис. Ниже показывает временную зависимость управления. сигналы.
Счетчик последовательностей SC реагирует на положительный переход Часы. Изначально вход CLR SC активен. Первый положительный переход
clock очищает SC до 0 , что, в свою очередь, активирует сигнал синхронизации T0 из декодер. T0 активен в течение одного тактового цикла.
Положительный тактовый переход , обозначенный на диаграмме T0, будет запускать только те регистры, управляющие входы которых связанный к тактовому сигналу T0.
SC увеличивается на с каждым положительным тактовым сигналом если только его вход CLR не активен.
Это создает последовательность сигналов синхронизации \ (T_0, T_1, T_2, T_3, T_4 \) и так далее, как показано на диаграмме. (Обратите внимание на взаимосвязь между синхронизирующим сигналом и соответствующие ему положительные часы переход.)
Если SC не очищен , сигналы синхронизации продолжатся с T 5 , T 6 вверх до Т15 и обратно до Т 0 .
Последние три формы волны на рис. Выше показывают, как SC очищается, когда D3T4 = 1. Выход D3 из операционного декодера становится активным в конце синхронизирующий сигнал T2
Когда синхронизирующий сигнал T4 становится активным , выход И вентиль, реализующий функцию управления D3T4, становится активным.
Этот сигнал применяется ко входу CLR SC .При следующем положительном часовом переходе (тот отмечен T4 на диаграмме) счетчик сбрасывается на 0. Это приводит к тому, что отсчет времени сигнал T0, чтобы стать активным вместо T5, который был бы активен, если бы SC был увеличивается, а не очищается.
Цикл чтения или записи памяти будет инициирован с нарастающим фронтом сигнала синхронизации. Предполагается, что время цикла памяти меньше, чем часы. время цикла. Согласно этому предположению, инициирован цикл чтения или записи памяти. по тактовому сигналу будет завершено к тому времени, когда пойдут следующие часы через его положительный переход.
Тактовый переход будет использоваться для загрузки слово памяти в регистр. Это временное соотношение недействительно во многих компьютеры, потому что время цикла памяти обычно больше, чем у процессора такт.
В таком случае необходимо обеспечить циклы ожидания в процессоре, пока слово памяти не станет доступным. Чтобы облегчить презентацию, мы будем Предположим, что на базовом компьютере период ожидания не требуется.
Для полного понимания работы компьютера очень важно, чтобы он понимает временные отношения между переходом часов и синхронизирующие сигналы. Например, выписка о передаче реестра T0: AR ← ПК определяет передачу содержимого ПК в AR, если сигнал синхронизации T0 активен.
T0 активен в течение всего интервала тактового цикла . За это время содержание ПК подключается к шине (с S 2 S 1 S 0 = 010) и вход LD (нагрузка) AR включен.Фактическая передача не происходит до конца тактового цикла. когда часы проходят положительный переход.
Те же положительные часы переход увеличивает счетчик последовательности SC с 0000 до 0001. Следующий Тактовый цикл имеет активный T1 и неактивный T0.
Система общей шины — GeeksforGeeks
Система общей шины
В этой статье мы изучим систему общей шины очень простого компьютера. Базовый компьютер имеет 8 регистров, блок памяти и блок управления.Схема общей шины показана ниже.
Подключения:
Выходы всех регистров, кроме OUTR (выходной регистр), подключены к общей шине. Выбранный выход зависит от двоичного значения переменных S2, S1 и S0. Линии от общей шины подключены к входам регистров и памяти. Регистр получает информацию от шины, когда его вход LD (загрузка) активирован, в то время как в случае памяти должен быть включен вход записи для приема информации.Содержимое памяти помещается на шину, когда активирован вход чтения.
Различные регистры:
4 регистра DR, AC, IR и TR имеют 16 бит, а 2 регистра AR и PC имеют 12 бит. INPR и OUTR имеют по 8 бит каждый. INPR принимает символ от устройства ввода и доставляет его в AC, в то время как OUTR принимает символ от AC и передает его на устройство вывода. 5 регистров имеют 3 управляющих входа LD (загрузка), INR (приращение) и CLR (очистка). Эти типы регистров похожи на двоичный счетчик.