Что такое снаряженная, полная и максимально допустимая масса ТС
4 мая 2021
Car.ru
Масса автомобиля — первостепенная характеристика, которая влияет на многие факторы. К последним можно отнести топливный расход, износ узлов и агрегатов, динамика, разгон и прочее. Основные понятия, которые касаются транспортного средства, первым делом проходят в автошколе. Несмотря на такую крепкую базу, для многих автомобилистов остается вопросом — какая масса является, полной, снаряженной и максимально допустимой.
Фото: Car.ruCar.ru
Начать стоит со снаряженной массы. Это масса транспортного средства, в которой учитывается вес стандартного оборудования и эксплуатационных материалов. Сюда можно отнести запасное колесо, инструменты, топливо, антифриз, масло и прочее. Однако, в такой показатель не берется масса груза, водителя и пассажиров. Простыми словами, снаряженная масса — это масса подготовленного автомобиля, емкости которого заправлены на полную.
Видео дня
Во многих европейских странах в снаряженную массу также добавляют вес автомобилиста — 75 кг. Производители придерживаются мнения, что без водителя транспортное средство не может передвигаться, а значит его вес нельзя причислять к полезной нагрузке.
Снаряженную массу часто называют массой без нагрузки. А полная включает также вес оборудования, расходных материалов, вес водителя, пассажиров и груза. Получается, что разница между двумя этими показателями состоит в массе водителя, пассажиров и груза. Есть еще одно понятие — чистая масса транспортного средства. В данном случае речь идет о весе конструкции — фактическая масса не снаряженного автомобиля без оборудования и расходных жидкостей.
Масса полезной нагрузки — важная эксплуатационная характеристика транспортного средства. Это общий вес груза, который может перевозить автомобиль. Если установить максимальную нагрузку на ось состава на метр пути, можно найти расчетную массу полезной нагрузки автомобиля. Автопроизводители также называют этот показатель грузоподъемностью. Его можно поделить на расчетную и номинальную. Расчетная грузоподъемность учитывает вес, который способен перевозить транспорт, а номинальная берет во внимание даже качество дорог. На твердом покрытии грузоподъемность составляет 500 — 28000 кг.
Автопроизводители также называют этот показатель грузоподъемностью. Его можно поделить на расчетную и номинальную. Расчетная грузоподъемность учитывает вес, который способен перевозить транспорт, а номинальная берет во внимание даже качество дорог. На твердом покрытии грузоподъемность составляет 500 — 28000 кг.
Полная масса. Разрешенная максимальная масса транспортного средства — масса снаряженного и предельно загруженного ТС, которая предусмотрена производителем. В этот показатель также берется вес водителя и пассажиров. У каждого автомобиля предусмотрена собственная максимально допустимая масса, которая указывается в документации. Этот показатель зависит от материалов, которые используются при создании автомобиля. Производители не рекомендуют превышать этот показатель, так как это может привести к деформации кузова и некоторых узлов. Но как трактовать данный показатель, если речь идет об автомобильном составе. Например, у автопоезда под максимальной массой подразумевается сумма массы всех транспортных средства, которые входят в автопоезд.
Итог. Снаряженная, полная и максимально допустимая масса — показатели, в которых часто путаются автомобилисты. Каждый из них подразумевает разное определение. В одних случаях во внимание берется масса конструкции автомобиля, а в других она дополняется весом груза и пассажиров.
Автоновости,
Нагрузка на CPU сервера
Как считается нагрузка
Нагрузка на сервер считается количеством процессорного времени потраченного сервером на обработку процессов пользователей. Учитывается то, сколько потребляли исполняемые процессы пользователя, а также затраченные ресурсы MySQL. Подробности того, чем же конкретно заняты пользовательские процессы, системе учёта неизвестны. Это можно косвенно или явно увидеть по логам веб-сервера — система указывает на дату и время, название процесса и количество тактов процессора, потраченное на работу данного процесса.
Зачастую, наиболее затратными процессами, которые могут создавать нагрузку на CPU являются действия экспорта/импорта базы данных, час пик посещаемости сайта, неоптимизированные индексы в базе данных, плохо оптимизированный программный код в скриптах пользователей, инфицированный, взломанный или хакерский код.
Для удобства пользователя в панели управления хостингом есть график (раздел «Аккаунт» → «Статистика CPU, MySQL»), на котором указана максимально допустимая для текущего тарифного плана нагрузка, а также имеется возможность просматривать отдельно статистику нагрузки на CPU, и отдельно статистику нагрузки на MySQL.
Почему нужно следить за нагрузкой?
На сервере находится много пользователей, и ресурсы делятся между ними. В каждый конкретный момент только часть пользователей использует ресурсы сервера. Если кто-то будет монополизировать ресурсы сервера постоянно, то другим пользователям достанется меньше ресурсов, из-за чего их сайты и базы будут работать медленнее. Поэтому мы вынуждены принимать меры, чтобы было комфортно работать всем.
Кроме того, внезапные скачки нагрузки могут означать то, что Ваш сайт пытаются взломать или он уже взломан.
Почему нельзя просто ограничить потребление ресурсов?
Иногда скрипты пользователя потребляют больше, чем положено по тарифному плану. Жёсткое ограничение ресурсов означает аварийное завершение скриптов пользователя и в конечном итоге, нестабильную работу его сайтов.
Как снизить нагрузку?
Если скачок нагрузки был кратковременным, или пиковым, то исходя из времени на графике следует проанализировать лог-файлы сайтов в соответствующий момент времени.
Если нагрузка возникает периодически, то необходимо внимательно просмотреть логи на момент возникновения нагрузки. Определить этот момент точнее Вам поможет график нагрузки с 5-минутным интервалом.
Для поисковых ботов достаточно задать crawl-delay или в файле robots. txt описать, какие разделы сайта можно, а какие нельзя индексировать. Примеры использования robots.txt можно увидеть здесь.
txt описать, какие разделы сайта можно, а какие нельзя индексировать. Примеры использования robots.txt можно увидеть здесь.
Любую нежелательную активность можно ограничить средствами веб-сервера. Это можно сделать через файл .htaccess. Пример ограничения по user-agent:
BrowserMatchNoCase "Baiduspider" bots BrowserMatchNoCase "HTTrack" bots BrowserMatchNoCase "BadBot" bots Order Allow,Deny Allow from ALL Deny from env=bots
Пример ограничения по IP-адресу:
deny from 123.123.123.123
Если нагрузка постоянная, то нужно начинать с анализа логов. При неизменной посещаемости, проблему следует искать в коде Вашей CMS.
Если Вы разработчик, можем предложить подключение модуля php XHprof. Вместе с инструментами веб-разработчика в браузере он предоставляет достаточно информации для профилирования кода.
Для обычных пользователей в качестве общих рекомендаций мы можем предложить включить кэширование средствами CMS (если CMS поддерживает данную функцию), отключить неиспользуемые модули в CMS, или задуматься о смене CMS на потребляющую меньшее количество ресурсов сервера.
При нагрузке на сервер баз данных, следует анализировать структуру запросов и при необходимости создавать дополнительные индексы и оптимизировать базы данных (подробнее об этом можно узнать из нашей статьи). Также у нас ведутся логи медленных запросов, которые мы можем предоставить по просьбе пользователя.
Если бороться с нагрузкой нет возможности или желания, есть несколько решений:
- воспользоваться дополнительной услугой «увеличенная нагрузка CPU»;
- арендовать VDS — все его ресурсы виртуального выделенного сервера будут полностью в Вашем распоряжении.
 Минусы этого решения — администрированием сервера и резервным копированием данных Вам придётся заниматься самостоятельно или покупать дополнительную услугу «расширенное администрирование»;
Минусы этого решения — администрированием сервера и резервным копированием данных Вам придётся заниматься самостоятельно или покупать дополнительную услугу «расширенное администрирование»; - арендовать выделенный сервер. Вы получаете привычное Вам окружение, Вам не приходится заботиться об администрировании и резервном копировании, все заботы о сервере берем мы в свои руки.
Что такое «полная загрузка»?
Инкотермс 2000 — это международно признанные и устоявшиеся определения, определяющие роли покупателя и продавца в транспортных соглашениях и контрактах, а также другие обязательства, определяющие момент передачи и права собственности на товары. Определения, используемые в договорах купли-продажи и других торговых операциях.
Условия перевозки морским и внутренним водным транспортом:
FAS (Франко вдоль борта судна — названный порт отгрузки) Продавец обязан разместить товар вдоль борта судна в названном порту. Продавец должен очистить товар для экспорта. Подходит только для морских перевозок, но НЕ для мультимодальных морских перевозок в контейнерах (см. Инкотермс 2010, публикация ICC 715). Этот термин обычно используется для тяжеловесных или насыпных грузов.
Продавец должен очистить товар для экспорта. Подходит только для морских перевозок, но НЕ для мультимодальных морских перевозок в контейнерах (см. Инкотермс 2010, публикация ICC 715). Этот термин обычно используется для тяжеловесных или насыпных грузов.
FOB (Free On Board — названный порт отгрузки) Продавец должен самостоятельно погрузить товар на борт судна, указанного покупателем. Стоимость и риск делятся, когда товар фактически находится на борту судна (это правило новое!). Продавец должен очистить товар для экспорта. Этот термин применим только к морским и внутренним водным перевозкам, но НЕ к мультимодальным морским перевозкам в контейнерах (см. Инкотермс 2010, публикация ICC 715). Покупатель должен сообщить продавцу данные о судне и порту, в котором должны быть отгружены товары, и не упоминается или не предусматривается использование перевозчика или экспедитора. Этот термин широко использовался неправильно в течение последних трех десятилетий, начиная с Инкотермс 19. 80 пояснил, что FCA следует использовать для контейнерных перевозок.
80 пояснил, что FCA следует использовать для контейнерных перевозок.
CFR (Стоимость и фрахт) Продавец должен оплатить расходы и фрахт, необходимые для доставки товара в указанный порт назначения. Риск утраты или повреждения переходит от продавца к покупателю, когда товар переходит через поручни судна в порту отгрузки. Продавец обязан произвести таможенную очистку товара для экспорта. Этот термин следует использовать только для морского или внутреннего водного транспорта.
CIF (Стоимость, страхование и фрахт) Продавец несет те же обязательства, что и в соответствии с CFR, однако он также обязан обеспечить страхование от риска потери или повреждения товара покупателем во время транспортировки. Продавец обязан произвести таможенную очистку товара для экспорта. Этот термин следует использовать только для морского или внутреннего водного транспорта.
Правила для всех видов транспорта:
EXW (Ex Works) Покупатель несет все расходы и риски, связанные с доставкой товара из помещения продавца в желаемый пункт назначения. Обязанностью продавца является обеспечение наличия товара в его помещении (заводе, фабрике, складе). Этот срок представляет собой минимальные обязательства для продавца. Этот термин может использоваться во всех видах транспорта.
Обязанностью продавца является обеспечение наличия товара в его помещении (заводе, фабрике, складе). Этот срок представляет собой минимальные обязательства для продавца. Этот термин может использоваться во всех видах транспорта.
FCA (Free Carrier) Обязанностью продавца является передача товара, прошедшего таможенную очистку для экспорта, перевозчику, указанному покупателем, в указанном месте или пункте. Если покупатель не указывает точного места, продавец может выбрать в пределах оговоренного места или диапазона, где перевозчик должен принять товар под свою ответственность. Когда при заключении договора с перевозчиком требуется помощь продавца, продавец может действовать на риск и за счет покупателя. Этот термин может использоваться во всех видах транспорта.
CPT (Перевозка оплачена до) Продавец оплачивает фрахт за перевозку товара до указанного пункта назначения. Риск утраты или повреждения товара после его доставки перевозчику переходит от продавца к покупателю. Этот термин требует от продавца таможенной очистки товаров для экспорта и может использоваться для всех видов транспорта.
Этот термин требует от продавца таможенной очистки товаров для экспорта и может использоваться для всех видов транспорта.
CIP (Перевозка и страхование оплачиваются) Продавец несет те же обязательства, что и в соответствии с CPT, но несет ответственность за страхование риска потери или повреждения товара покупателем во время перевозки. Продавец обязан произвести таможенную очистку товаров для экспорта, однако от него требуется только получение страховки с минимальным покрытием. Этот термин требует от продавца таможенной очистки товаров для экспорта и может использоваться для всех видов транспорта.
DAT (Поставка на терминале) Продавец осуществляет поставку, когда товар после разгрузки с прибывающего транспортного средства предоставляется в распоряжение покупателя на названном терминале в названном порту или месте назначения. «Терминал» включает причал, склад, контейнерную площадку или автомобильный, железнодорожный или воздушный терминал. Обе стороны должны согласовать терминал и, если возможно, точку внутри терминала, в которой риски перейдут от продавца к покупателю товара. Если предполагается, что продавец должен нести все расходы и ответственность от терминала до другого пункта, могут применяться DAP или DDP.
Обе стороны должны согласовать терминал и, если возможно, точку внутри терминала, в которой риски перейдут от продавца к покупателю товара. Если предполагается, что продавец должен нести все расходы и ответственность от терминала до другого пункта, могут применяться DAP или DDP.
DAP (Поставка на месте) Продавец доставляет товары, когда они предоставлены в распоряжение покупателя на прибывшем транспортном средстве, готовом к разгрузке в указанном месте назначения. Сторонам рекомендуется как можно четче указывать пункт в пределах согласованного места назначения, поскольку в этом пункте риски переходят от продавца к покупателю. Если продавец несет ответственность за таможенную очистку товаров, уплату пошлин и т. д., следует рассмотреть возможность использования термина DDP.
DDP (Доставка с оплатой пошлины) Продавец несет ответственность за доставку товара в указанное место в стране импорта, включая все расходы и риски, связанные с доставкой товара в пункт назначения импорта. Сюда входят пошлины, налоги и таможенные формальности. Этот термин может использоваться независимо от вида транспорта.
Сюда входят пошлины, налоги и таможенные формальности. Этот термин может использоваться независимо от вида транспорта.
Инфраструктура хранилища данных: полная и добавочная загрузка в ETL
Одной из конечных целей эффективного процесса ETL и хранилища данных ETL является возможность надежно запрашивать данные, получать аналитические сведения и генерировать визуализации. Хранилище данных ETL имеет ряд преимуществ для организаций, позволяя им собирать все свои данные по всей организации (например, ERP, CRM, информацию о платежах, данные о продажах) и запрашивать эти данные, используя их для поиска закономерностей и взаимосвязей, выявления неэффективности. , создавать отчеты и оценивать KPI.
Традиционно после загрузки данных в хранилище данных ETL их можно просмотреть с помощью таких инструментов, как Tableau и Qlik.
Одним из наиболее важных элементов процесса ETL является поток данных в хранилище данных ETL.
Преобразование и подготовка исходных данных
Поскольку данные собираются и хранятся во многих различных системах, каждая из которых имеет свой собственный способ хранения данных, процесс сбора и сопоставления этих данных, а также их полезность для конечных пользователей — это то, где вступает в действие ETL.
Данные сначала извлекаются из этих разных систем, каждая из которых имеет собственный формат. Затем он преобразуется в формат, который стандартизирован и может использоваться во всей системе. Этот этап состоит в основном из удаления посторонних или ошибочных данных, применения правил и проверки целостности данных.
Затем идет подготовка — обычно преобразованные данные не загружаются напрямую в целевое хранилище данных ETL. Как правило, данные поступают в промежуточную базу данных, чтобы, если что-то пойдет не так, было проще выполнить откат. Также на этом этапе могут быть созданы аудиторские отчеты для соответствия нормативным требованиям, а также могут быть выявлены и исправлены проблемы.
Наконец, данные публикуются в хранилище данных ETL и загружаются в целевые таблицы. Однако в случае ошибки, повреждения данных, дублирования или отсутствия записей надежность хранилища данных ETL оказывается под угрозой. Загружаемые данные будут состоять из исторических данных — уже существующих записей, таких как транзакции за предыдущий год, — а также новых данных, которые постоянно добавляются.
Здесь начинается тестирование хранилища данных ETL, чтобы убедиться, что данные в хранилище данных ETL достоверны, точны и полны. В процессе ETL данные проходят через конвейер, прежде чем попадают в хранилище данных ETL. Весь конвейер ETL должен быть протестирован, чтобы убедиться, что каждый тип данных преобразуется или копируется должным образом.
Но как этот процесс ETL в хранилище данных переходит в хранилище данных ETL?
Разница между полной и добавочной загрузкой
Существует два основных метода загрузки данных в хранилище:
Полная загрузка : при полной загрузке весь набор данных сбрасывается или загружается, а затем полностью заменяется (т. е. удаляется и заменяется) новым, обновленным набором данных. Никакой дополнительной информации, такой как метки времени, не требуется.
Например, возьмем магазин, который загружает все свои продажи через процесс ETL в хранилище данных в конце каждого дня. Допустим, в понедельник было совершено 5 продаж, чтобы в понедельник вечером была загружена таблица из 5 записей. Затем во вторник было совершено еще 3 продажи, которые необходимо добавить. Таким образом, во вторник вечером, при полной загрузке, загружаются 5 записей понедельника, а также 3 записи вторника — неэффективная система, хотя относительно простая в настройке и обслуживании. Хотя этот пример слишком упрощен, принцип тот же.
Затем во вторник было совершено еще 3 продажи, которые необходимо добавить. Таким образом, во вторник вечером, при полной загрузке, загружаются 5 записей понедельника, а также 3 записи вторника — неэффективная система, хотя относительно простая в настройке и обслуживании. Хотя этот пример слишком упрощен, принцип тот же.
Добавочная загрузка : только разница между целевыми и исходными данными загружается через процесс ETL в хранилище данных. Существует 2 типа инкрементной загрузки, в зависимости от объема загружаемых данных; потоковая добавочная загрузка и пакетная добавочная загрузка.
Следуя предыдущему примеру, магазин, совершивший 3 продажи во вторник, загрузит только дополнительных 3 записей в таблицу продаж вместо перезагрузки всех 9 записей.0092 записи. Это имеет то преимущество, что экономит время и ресурсы, но увеличивает сложность.
Инкрементная загрузка, конечно, намного быстрее, чем полная загрузка. Основным недостатком этого типа загрузки является ремонтопригодность. В отличие от полной загрузки, при добавочной загрузке вы не можете повторно запустить всю загрузку в случае ошибки. В дополнение к этому файлы необходимо загружать по порядку, поэтому ошибки усугубят проблему, поскольку другие данные будут стоять в очереди.
В отличие от полной загрузки, при добавочной загрузке вы не можете повторно запустить всю загрузку в случае ошибки. В дополнение к этому файлы необходимо загружать по порядку, поэтому ошибки усугубят проблему, поскольку другие данные будут стоять в очереди.
Сегодня организации отказываются от обработки и загрузки данных большими пакетами, предпочитая — или руководствуясь потребностями бизнеса — обрабатывать в режиме реального времени с использованием потоковой обработки, что означает, что по мере того, как клиентские приложения записывают данные в источник данных, данные обрабатываются, преобразованы и сохранены в целевом хранилище данных. Сегодня существуют инструменты для обеспечения этого процесса, такие как Apache Samza, Apache Storm и Apache Kafka. Это устраняет многие недостатки традиционной обработки и загрузки, увеличивает скорость и снижает сложность.
Проблемы с ETL и хранилищем данных
Когда дело доходит до загрузки данных через процесс ETL в хранилище данных в само хранилище данных ETL, особенно при добавочной загрузке, возникает ряд проблем.
Мониторинг : поскольку данные извлекаются из разрозненных источников и преобразуются, обязательно будут ошибки или аномалии. Это может быть вызвано такими вещами, как истечение срока действия учетных данных API или трудности при общении с API. Эти ошибки или аномалии должны быть выявлены и исправлены как можно быстрее.
Несовместимость : могут быть добавлены новые записи, которые делают существующие данные недействительными; например, поле, которое должно быть целым числом, получает значение даты. Это особенно проблематично, когда добавляются данные в реальном времени, и конечные пользователи запрашивают эти данные и получают неверные или неполные результаты, и возникает узкое место, поскольку новые записи не могут быть добавлены.
Заказ : конвейеры данных часто являются распределенными системами, поэтому их доступность максимальна. Это может привести к тому, что данные будут обрабатываться в порядке, отличном от порядка их получения, и это особенно важно, если данные обновляются или удаляются.

Зависимости : понимание зависимостей между процессами или подпроцессами имеет решающее значение, когда речь идет об управлении ETL. Например, будете ли вы выполнять процесс 2, если процесс 1 потерпит неудачу? Это становится более сложным по мере увеличения процессов и подпроцессов.
Согласование : еще одна ключевая задача — процесс согласования для обеспечения правильности и согласованности данных в хранилище данных ETL. Хотя тестирование ETL следует проводить регулярно, согласование хранилища данных — это непрерывный процесс.
Эти проблемы необходимо понимать, смягчать и управлять ими.
Примером решения этой проблемы является поиск баланса между параллельной и последовательной обработкой.
Последовательная обработка — это когда за один раз выполняется одна задача, и задачи выполняются процессором последовательно. Таким образом, одна задача может начаться только тогда, когда предыдущая закончилась.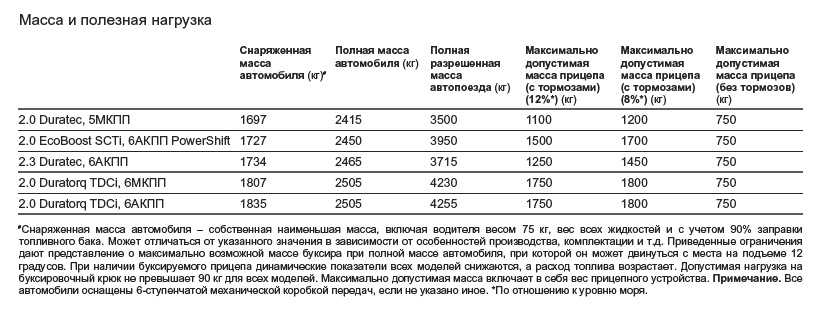 Параллельная обработка, как следует из ее названия, представляет собой тип обработки, при котором несколько задач выполняются одновременно.
Параллельная обработка, как следует из ее названия, представляет собой тип обработки, при котором несколько задач выполняются одновременно.
Когда дело доходит до загрузки данных, если процессы не зависят друг от друга, их можно обрабатывать параллельно, что приводит к значительной экономии времени. Однако при наличии зависимостей это может привести к осложнениям, и данные придется обрабатывать последовательно.
Параллелизм также может быть достигнут с данными — разделение одного последовательного файла на более мелкие файлы данных для обеспечения параллельного доступа — конвейер, позволяющий одновременно запускать несколько компонентов в одном и том же потоке данных, и компонент, который запускает несколько процессов с разными данными потоки в одном и том же задании одновременно.
Стремление к достижению этой эффективности также можно увидеть с помощью инструментов ETL в хранилище данных, таких как Amazon Redshift и Google BigQuery. Например, в Redshift Columnar Storage и MPP Processing обеспечивают высокопроизводительную аналитическую обработку запросов. BigQuery является бессерверным и предоставляет хранилище данных как услугу, управляя хранилищем данных и позволяя выполнять очень быстрые запросы к большим наборам данных.
BigQuery является бессерверным и предоставляет хранилище данных как услугу, управляя хранилищем данных и позволяя выполнять очень быстрые запросы к большим наборам данных.
Что необходимо для успеха в производстве
Процесс ETL в хранилище данных является сложным и включает в себя множество заинтересованных сторон. Это могут быть специалисты по данным, инженеры по данным и инженеры по инфраструктуре, не говоря уже о тех, кто генерирует и/или потребляет данные, например, о руководителях отдела маркетинга. В конечном счете, конечно, весь процесс ETL, включая хранилище данных ETL, бесполезен, если различные части не собираются вместе, что приводит к данным, которым все стороны могут доверять и на которые можно действовать при необходимости. Эти данные также должны быть доступны, время простоя должно быть сведено к минимуму, данные должны быстро и легко запрашиваться, и все это должно удовлетворять потребности различных типов пользователей, использующих систему.
Это, конечно, вызывает разочарование, так как часто специалистов по данным раздражает медленный темп работы инженеров по данным, в то время как инженеры по данным расстраиваются из-за нереалистичных ожиданий и плохого технического понимания ученых по данным, инженеры по инфраструктуре должны постоянно адаптироваться к постоянно растущим требованиям к ресурсам, а конечные пользователи требуют дополнительных функций и более высокой производительности.
Чтобы помочь тем, кто создает и использует информационные панели и визуализации данных, лучше понять, что необходимо для успеха в производстве, важно иметь общее представление о процессе.
Часто конечные пользователи жалуются, например, «Панель управления слишком долго загружается», или ожидания, которые могут быть нереалистичными, например, «Мне нужны эти данные, прежде чем я приду на работу в понедельник утром».
Если все пользователи будут осведомлены о процессе и подводных камнях — от тех, кто видит архитектуру ETL в хранилищах данных, до тех, кто потребляет данные в виде информационных панелей или других инструментов визуализации BI, — организация может успешно использовать данные для достижения успеха в своей деятельности. бизнес-цели.
Сказав это, есть несколько конкретных шагов, которые можно предпринять, чтобы гарантировать, что процесс ETL успешно загружает данные в хранилище данных ETL и что все выиграют:
Получение понимания системы в целом, включая источник данных и цель.
 Это поможет сохранить концентрацию команды, свести к минимуму влияние нерелевантных данных и обеспечить бесперебойную и быструю загрузку данных.
Это поможет сохранить концентрацию команды, свести к минимуму влияние нерелевантных данных и обеспечить бесперебойную и быструю загрузку данных.Планирование: это, пожалуй, самый важный шаг в процессе, и тем не менее именно на него многие команды тратят наименьшее количество времени и усилий. Это так верно, что слишком много команд переходят непосредственно к самому процессу ETL, пытаясь быстро загрузить данные, в конечном итоге срезая углы и в конечном итоге обходясь организации еще дороже, когда речь идет об увеличении затрат на обслуживание, проблемах масштабирования, исправлении ошибок. , а также нарушение хозяйственной деятельности.
Используйте команду: вовлекая в процесс все соответствующие заинтересованные стороны, вы с большей вероятностью получите поддержку, помощь, идеи и помощь, когда что-то пойдет не так или примет неожиданный оборот. Все, от маркетинговой команды до инженеров, должны быть вовлечены, чтобы обеспечить плавный процесс, которым владеют все и в успех которого все вложены.

Чаще пересматривайте. Обеспечьте постоянство производительности, получите отзывы от пользователей и пересмотрите планы и резервные копии, чтобы обеспечить планирование каждой предсказуемой ситуации.
Все просто
При использовании традиционной методологии ETL каждый аспект процесса, от извлечения данных до их преобразования и, наконец, загрузки в хранилище данных ETL, сопряжен с риском. Сложность, движущиеся части и размер задействованной команды означают, что есть множество вещей, которые могут пойти не так.
Традиционный ETL, хотя и верно служит так долго, имеет недостатки, которые делают выполнение требований современного бизнеса все более трудным и ресурсоемким.
С помощью Panoply вы можете автоматизировать прием любых данных из различных источников и создавать четкие, настраиваемые таблицы, к которым можно сразу же обращаться. Он также легко подключает вас к любому необходимому инструменту бизнес-аналитики, чтобы вы могли начать визуализацию, анализ и обмен данными за считанные минуты.