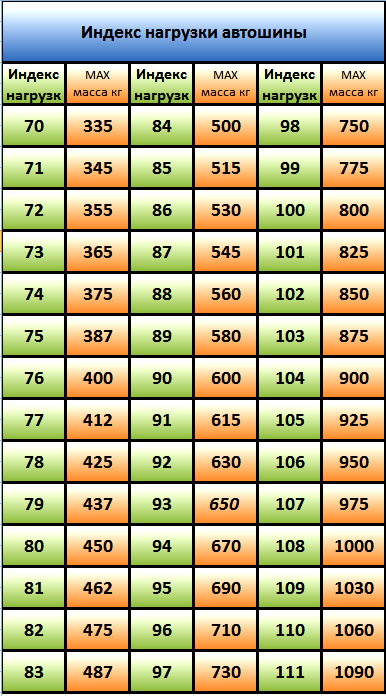
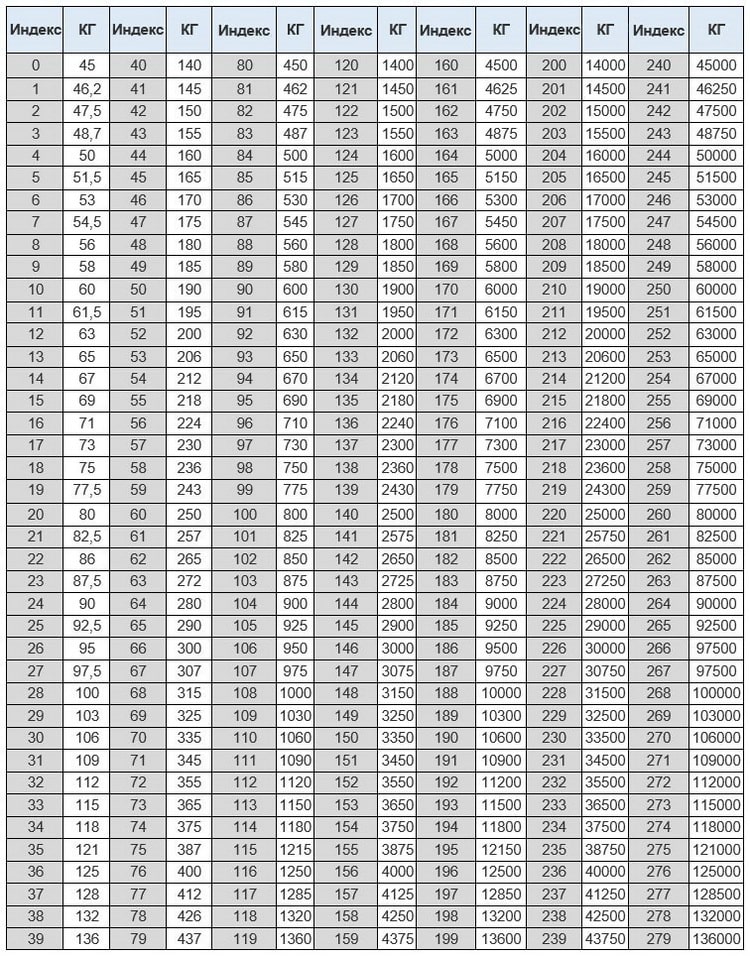
Таблица индексов скорости. Таблица индексов нагрузки
|
Таблица индексов скорости |
Таблица индексов нагрузки |
||||
|
Индекс скорости |
Допустимая скорость, км/ч |
Индекс нагрузки |
Допустимая нагрузка, кг |
Индекс нагрузки |
Допустимая нагрузка, кг |
|
B |
50 |
0 |
45 |
100 |
800 |
|
C |
60 |
1 |
46,2 |
101 |
825 |
|
D |
65 |
2 |
47,5 |
102 |
850 |
|
E |
70 |
3 |
48,7 |
103 |
875 |
|
F |
80 |
4 |
50 |
104 |
900 |
|
G |
90 |
5 |
51,5 |
105 |
925 |
|
|
100 |
6 |
53 |
106 |
950 |
|
K |
110 |
7 |
54,5 |
107 |
975 |
|
L |
120 |
8 |
56 |
108 |
1000 |
|
M |
130 |
9 |
58 |
109 |
1030 |
|
N |
140 |
10 |
60 |
110 |
1060 |
|
P |
150 |
11 |
61,5 |
111 |
1090 |
|
Q |
160 |
12 |
63 |
112 |
1120 |
|
R |
170 |
13 |
65 |
113 |
1150 |
|
S |
180 |
14 |
67 |
114 |
1180 |
|
T |
190 |
15 |
69 |
115 |
1215 |
|
U |
200 |
16 |
71 |
116 |
1250 |
|
H |
|
17 |
73 |
117 |
1285 |
|
V |
240 |
18 |
75 |
118 |
1320 |
|
W |
270 |
19 |
77,5 |
119 |
1360 |
|
Y |
300 |
20 |
80 |
120 |
1400 |
|
ZR |
более 240 |
21 |
82,5 |
121 |
1450 |
|
22 |
85 |
122 |
1500 |
||
|
23 |
87,5 |
123 |
1550 |
||
|
24 |
90 |
124 |
1600 |
||
|
25 |
92,5 |
125 |
1650 |
||
|
26 |
95 |
126 |
1700 |
||
|
27 |
97 |
127 |
1750 |
||
|
28 |
100 |
128 |
1800 |
||
|
29 |
103 |
129 |
1850 |
||
|
30 |
106 |
130 |
1900 |
||
|
|
109 |
131 |
1950 |
||
|
32 |
112 |
132 |
2000 |
||
|
33 |
115 |
133 |
2060 |
||
|
34 |
118 |
134 |
2120 |
||
|
35 |
121 |
135 |
2180 |
||
|
36 |
125 |
136 |
2240 |
||
|
37 |
128 |
137 |
2300 |
||
|
38 |
132 |
138 |
2360 |
||
|
39 |
136 |
139 |
2430 |
||
|
40 |
140 |
140 |
2500 |
||
|
41 |
145 |
141 |
2575 |
||
|
42 |
150 |
142 |
2650 |
||
|
43 |
155 |
143 |
2725 |
||
|
44 |
160 |
144 |
2800 |
||
|
45 |
165 |
145 |
2900 |
||
|
46 |
170 |
146 |
3000 |
||
|
47 |
175 |
147 |
3075 |
||
|
48 |
180 |
148 |
3150 |
||
|
49 |
185 |
149 |
3250 |
||
|
50 |
190 |
150 |
3350 |
||
|
51 |
195 |
151 |
3450 |
||
|
52 |
200 |
152 |
3550 |
||
|
53 |
206 |
153 |
3650 |
||
|
54 |
212 |
154 |
3750 |
||
|
55 |
218 |
155 |
3875 |
||
|
56 |
224 |
156 |
4000 |
||
|
57 |
230 |
157 |
4125 |
||
|
58 |
236 |
158 |
4250 |
||
|
59 |
243 |
159 |
4375 |
||
|
60 |
250 |
160 |
4500 |
||
|
61 |
257 |
161 |
4625 |
||
|
62 |
265 |
162 |
4750 |
||
|
63 |
272 |
163 |
4875 |
||
|
64 |
280 |
164 |
5000 |
||
|
65 |
290 |
165 |
5150 |
||
|
66 |
300 |
166 |
5300 |
||
|
67 |
307 |
167 |
5450 |
||
|
68 |
315 |
168 |
5600 |
||
|
69 |
325 |
169 |
5800 |
||
|
70 |
335 |
170 |
6000 |
||
|
71 |
345 |
171 |
6150 |
||
|
72 |
355 |
172 |
6300 |
||
|
73 |
365 |
173 |
6500 |
||
|
74 |
375 |
174 |
6700 |
||
|
75 |
387 |
175 |
6900 |
||
|
76 |
400 |
176 |
7100 |
||
|
77 |
412 |
177 |
7300 |
||
|
78 |
425 |
178 |
7500 |
||
|
79 |
437 |
179 |
7750 |
||
|
80 |
450 |
180 |
8000 |
||
|
81 |
462 |
181 |
8250 |
||
|
82 |
475 |
182 |
8500 |
||
|
83 |
487 |
183 |
8750 |
||
|
84 |
500 |
184 |
9000 |
||
|
85 |
515 |
185 |
9250 |
||
|
86 |
530 |
186 |
9500 |
||
|
87 |
545 |
187 |
9750 |
||
|
88 |
560 |
188 |
10000 |
||
|
89 |
580 |
189 |
10300 |
||
|
90 |
600 |
190 |
10600 |
||
|
91 |
615 |
191 |
10900 |
||
|
92 |
630 |
192 |
11200 |
||
|
93 |
650 |
193 |
11500 |
||
|
94 |
670 |
194 |
11800 |
||
|
95 |
690 |
195 |
12150 |
||
|
96 |
710 |
196 |
12500 |
||
|
97 |
730 |
197 |
12850 |
||
|
98 |
750 |
198 |
13200 |
||
|
99 |
775 |
199 |
13600 |
||
Поиск по артикулу
Статус заказа
Шаблон таблицы индексов — Azure Architecture Center
Создание в хранилище данных индексов по полям, которые часто используются в запросах. Этот шаблон может повысить производительность запросов, ускоряя поиск данных, которые нужно извлечь из хранилища.
Этот шаблон может повысить производительность запросов, ускоряя поиск данных, которые нужно извлечь из хранилища.
Контекст и проблема
В многих хранилищах данные для коллекций сущностей организованы при помощи первичного ключа. Этот ключ может использоваться в приложении для поиска и извлечения данных. На рисунке представлен пример хранилища данных со сведениями о клиентах. Первичный ключ — это идентификатор клиента. На рисунке представлены сведения о клиенте, упорядоченные по первичному ключу (идентификатору клиента).
Первичный ключ отлично подходит для запросов данных на основе его значения. Но если нужно получить данные на основе другого поля, первичный ключ не всегда можно использовать. В приведенном выше примере для поиска клиентов в приложении нельзя использовать первичный ключ (идентификатор клиента), если данные запрашиваются исключительно по ссылке на значение какого-нибудь другого атрибута, например на название города, в котором находится клиент. Для выполнения такого запроса приложению может потребоваться получить и изучить каждую запись клиента, что может занять довольно много времени.
Многие системы управления реляционными базами данных поддерживают вторичные индексы. Вторичный индекс — это отдельная структура данных, упорядоченных по одному или нескольким вторичным (дополнительным) ключевым полям. Такой индекс указывает, где хранятся данные для каждого индексированного значения. Элементы вторичного индекса обычно сортируются по значению вторичных ключей, чтобы повысить скорость поиска данных. Такие индексы, как правило, автоматически обслуживаются системой управления базами данных.
Вы можете создать любое количество вторичных индексов для поддержки различных запросов, выполняемых в приложении. Например, в таблице со сведениями о клиентах в реляционной базе данных, где идентификатор клиента является первичным ключом, стоит добавить вторичный индекс над полем города, если в приложении часто выполняется поиск клиентов по городу, в котором они находятся.
Однако, хотя вторичные индексы часто используются в реляционных системах, некоторые хранилища данных NoSQL, используемые облачными приложениями, не предоставляют эквивалентную функцию.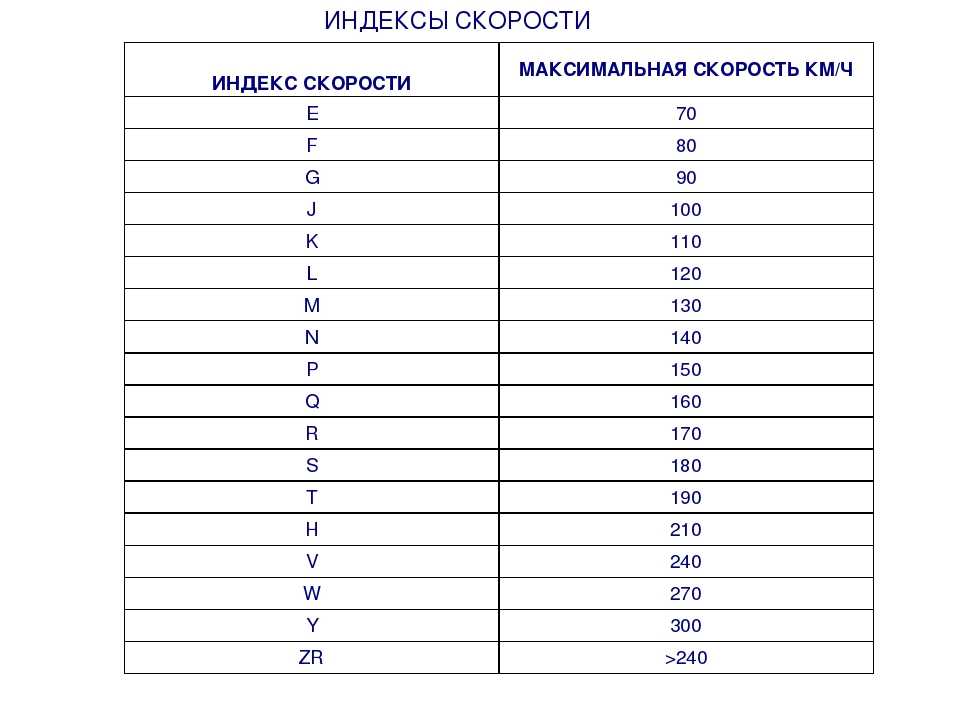
Решение
Если хранилище данных не поддерживает вторичные индексы, их можно эмулировать вручную, создав собственные таблицы индексов. В таблице индексов данные упорядочиваются по указанному ключу. Для структурирования таблицы индексов обычно используются три стратегии. Стратегию выбирают на основе требуемого числа вторичных индексов и характера запросов в приложении.
Первая стратегия — данные дублируются в каждой таблице индексов, но упорядочиваются по разным ключам (полная денормализация). На следующем рисунке представлены таблицы индексов, в которых одни и те же данные клиента упорядочены по городу и фамилии:
Эта стратегия подходит, если данные остаются относительно статическими при любом количестве запросов с помощью каждого ключа. Если данные более динамические, затраты на обслуживание каждой таблицы индексов слишком значительны и такой подход нецелесообразен. Кроме того, если объем данных очень велик, требуется значительное пространство для хранения дублируемых данных.
Вторая стратегия — создаются нормализованные таблицы индексов, которые упорядочены по разным ключам, и добавляются ссылки на исходные данные с помощью первичного ключа (вместо их дублирования), как показано на приведенном ниже рисунке. Исходные данные называются таблицей фактов.
Этот способ позволяет сэкономить место и сократить затраты на обслуживание дублируемых данных. Недостатком такого подхода является то, что приложению требуется выполнять две операции поиска данных с использованием вторичного ключа. Сначала нужно найти первичный ключ для данных в таблице индексов, а затем использовать его для поиска данных в таблице фактов.
Третья стратегия — создаются частично нормализованные таблицы индексов, упорядоченные при помощи различных ключей. В таких таблицах дублируются часто извлекаемые поля. Для доступа к редко используемым полям добавляются ссылки на таблицу фактов. На следующем рисунке показано, как часто используемые данные дублируются в каждой таблице индексов:
Эта стратегия обеспечивает баланс между двумя первыми подходами.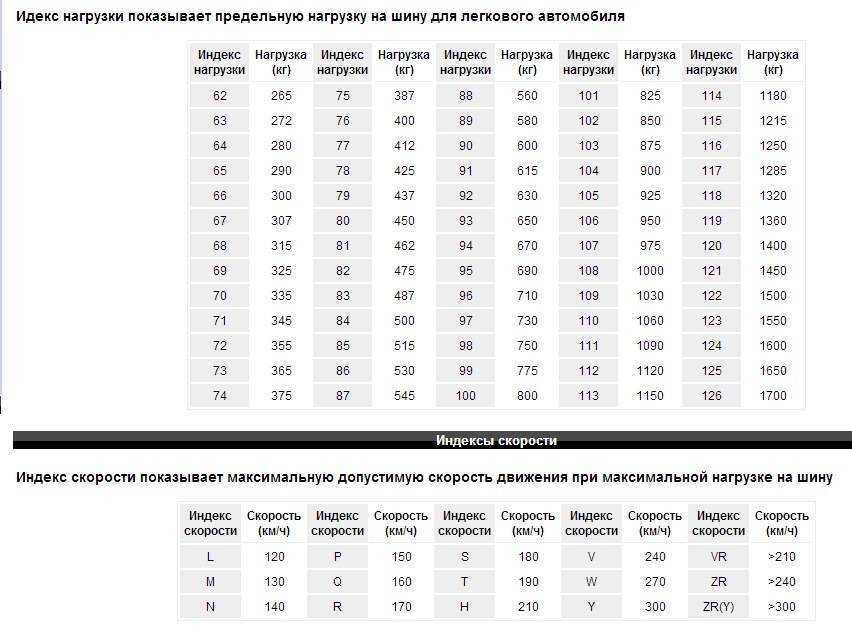 Данные для часто выполняемых запросов можно быстро получить при помощи одной операции поиска, а занимаемое пространство и затраты на обслуживание не так значительны, как при дублировании всего набора данных.
Данные для часто выполняемых запросов можно быстро получить при помощи одной операции поиска, а занимаемое пространство и затраты на обслуживание не так значительны, как при дублировании всего набора данных.
Если приложение часто запрашивает данные, указывая сочетание значений (например, «Найти всех клиентов, которые живут в Редмонде и имеют фамилию Smith»), можно реализовать ключи к элементам в таблице индексов в виде объединения атрибутов Town и LastName. На приведенном ниже рисунке представлена таблица индексов на основе составных ключей. Ключи сортируются по городу, а затем — по фамилиям для записей с одинаковыми значениями города.
Таблицы индексов могут ускорить операции запросов для сегментированных данных и особенно полезны, когда ключ сегмента хэшируется. На приведенном ниже рисунке показан пример, где ключ сегмента является хэшем идентификатора клиента. В таблице индексов можно упорядочить данные по нехэшированному значению (город и фамилия) и указать хэшированный ключ как данные поиска. Это поможет предотвратить многократное вычисление хэш-ключей (ресурсоемкую операцию) в приложении, если требуется получить данные в пределах диапазона или в порядке нехэшированных ключей. Например, запрос типа «Найти всех клиентов, которые живут в Редмонде», можно быстро решить, найдя соответствующие элементы в таблице индексов, где все они хранятся в непрерывном блоке. Затем используйте ссылки на данные клиента с помощью ключей сегментов, которые хранятся в таблице индексов.
Это поможет предотвратить многократное вычисление хэш-ключей (ресурсоемкую операцию) в приложении, если требуется получить данные в пределах диапазона или в порядке нехэшированных ключей. Например, запрос типа «Найти всех клиентов, которые живут в Редмонде», можно быстро решить, найдя соответствующие элементы в таблице индексов, где все они хранятся в непрерывном блоке. Затем используйте ссылки на данные клиента с помощью ключей сегментов, которые хранятся в таблице индексов.
Проблемы и рекомендации
При принятии решения о реализации этого шаблона необходимо учитывать следующие моменты.
Затраты на обслуживание вторичных индексов могут оказаться достаточно велики. Необходимо иметь представление о запросах, которые используются в вашем приложении, и анализировать их. Создавайте таблицы индексов, только если планируете использовать их регулярно. Не создавайте теоретические таблицы индексов для поддержки запросов, которые не выполняются в приложении или выполняются лишь время от времени.
Дублирование данных в таблице индексов может повлечь значительные дополнительные расходы на хранение и трудозатраты, так как при этом требуется обслуживание нескольких копий данных.
Для реализации таблицы индексов в виде нормализованной структуры, в которой добавляется ссылка на исходные данные, приложению требуется выполнить две операции поиска данных. Сначала выполняется поиск первичного ключа в таблице индексов, а затем этот ключ используется для получения данных.
Если система содержит несколько таблиц индексов для очень больших наборов данных, иногда трудно поддерживать согласованность между таблицами индексов и исходными данными. Можно разработать приложение на основе модели конечной согласованности. Например, для вставки, обновления или удаления данных приложение может отправить сообщение в очередь и создать отдельную задачу для выполнения операции и обслуживания таблиц индексов, которые асинхронно ссылаются на эти данные. Сведения о реализации согласованности в конечном счете см.
 в руководстве по обеспечению согласованности данных.
в руководстве по обеспечению согласованности данных.Таблицы в хранилище Microsoft Azure поддерживают обновления транзакций для изменения данных в одной секции (также называются транзакциями группы сущностей). При хранении данных для таблицы фактов и одной или нескольких таблиц индексов в одной секции вы можете использовать эту функцию, чтобы обеспечить согласованность.
Собственно таблицы индексов также можно секционировать или сегментировать.
Когда следует использовать этот шаблон
Этот шаблон используется для повышения производительности запросов, когда приложению часто требуется извлекать данные с помощью ключа, отличного от первичного (или ключа сегментов).
Этот шаблон может оказаться неэффективным в следующих случаях:
- Данные нестабильны. Таблица индексов может очень быстро стать неактуальной. В таком случае не стоит использовать ее, так как затраты на обслуживание таблицы могут превысить экономию от ее применения.

- Поле, выбранное в качестве вторичного ключа для таблицы индексов, недифференцировано и может иметь только небольшой набор значений (например, пол).
- Значения данных поля, выбранного в качестве вторичного ключа для таблицы индексов, очень разрознены. Например, если для 90 % записей в поле содержатся одинаковые значения, создание и обслуживание таблицы индексов для поиска данных на основе этого поля может повлечь большие затраты, чем последовательный просмотр данных. Но если запросы часто обращаются к значениями, которые содержатся в оставшихся 10 % записей, этот индекс можно использовать. Следует иметь представление о запросах, которые выполняет приложение, и об их частоте.
Пример
Таблицы хранилища Azure обеспечивают высокомасштабируемое хранилище ключей и значений для приложений в облаке. В приложениях можно хранить и извлекать значения, указав ключ. Значения данных могут содержать несколько полей, но структура элемента данных непрозрачна для хранилища таблиц, в котором элемент данных просто обрабатывается как массив байтов.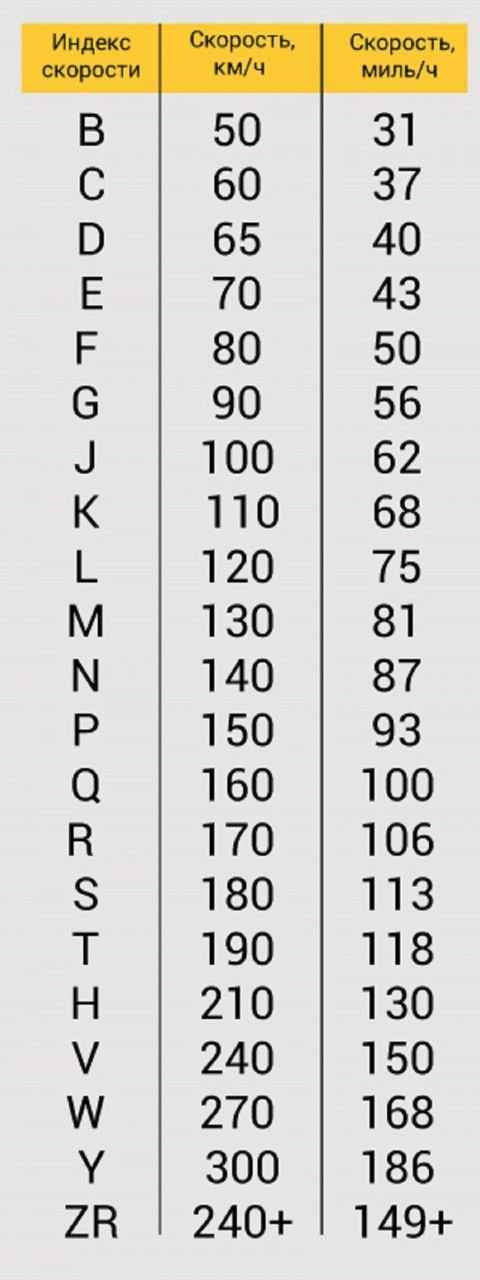
Таблицы хранилища Azure также поддерживают сегментирование. Ключ сегментирования включает два элемента: ключ секции и ключ строки. Элементы с одним ключом секции хранятся в одной секции (сегменте) в порядке ключей строк. Хранилище таблиц оптимизировано для выполнения запросов данных в непрерывном диапазоне значений для ключа строки в секции. Если вы создаете облачные приложения, в которых данные хранятся в таблицах Azure, структурируйте данные с учетом этой функции.
Например, рассмотрим приложение со сведениями о фильмах. В приложении часто выполняются запросы на фильмы по жанру (остросюжетный фильм, документальный фильм, исторический фильм, комедия, драма и т. д). Можно создать таблицу Azure с секцией для каждого жанра, используя жанр в качестве ключа секции и указывая название фильма в качестве ключа строки, как показано на рисунке ниже:
Этот подход менее эффективен, если в приложении также нужно выполнять запросы по имени актеров. В этом случае можно создать отдельную таблицу Azure, которая будет таблицей индексов.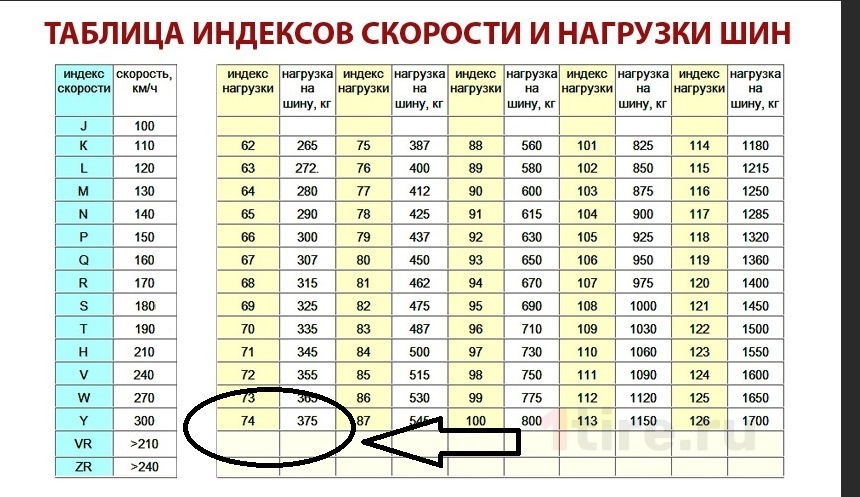 Ключ секции — это имя актера, а ключ строки — название фильма. Данные для каждого актера будут храниться в отдельной секции. Если в фильме снимается несколько искомых актеров, его название будет содержаться в нескольких секциях.
Ключ секции — это имя актера, а ключ строки — название фильма. Данные для каждого актера будут храниться в отдельной секции. Если в фильме снимается несколько искомых актеров, его название будет содержаться в нескольких секциях.
Можно дублировать данные фильма, содержащиеся в значениях в каждой секции, используя первый подход. Он описан выше в разделе «Решение». Но есть вероятность, что каждый фильм будет реплицирован несколько раз (один раз для каждого актера). Поэтому лучше частично денормализовать данные для поддержки наиболее частых запросов (например, по именам других актеров). Также рекомендуем настроить приложение для получения всех оставшихся данных, включая ключ секции, необходимый для поиска подробной информации в секциях для жанра. Этот подход описан как третий вариант в разделе «Решение». Он представлен на рисунке ниже.
Дальнейшие действия
- Руководство по согласованности данных. Таблицы индексов должны обслуживаться, так как индексируемые данные могут измениться.
 Иногда в облаке невозможно или нерентабельно обновлять индексы в рамках той же транзакции, в которой изменяются данные. В этом случае подход конечной согласованности является более уместным. Руководство содержит сведения о проблемах, которые касаются конечной согласованности.
Иногда в облаке невозможно или нерентабельно обновлять индексы в рамках той же транзакции, в которой изменяются данные. В этом случае подход конечной согласованности является более уместным. Руководство содержит сведения о проблемах, которые касаются конечной согласованности.
При реализации этого шаблона также могут быть актуальны следующие шаблоны:
- Шаблон сегментирования. Шаблон таблицы индексов часто используется с данными, которые секционированы с применением сегментов. Шаблон сегментирования предоставляет дополнительные сведения о том, как преобразовать хранилище данных в набор сегментов.
- Шаблон материализованного представления. Вместо индексирования данных для поддержки сводных запросов, возможно, целесообразнее создать материализованное представление данных. Здесь описано, как реализовать эффективную поддержку сводных запросов, создав предварительно заполненные представления данных.
— Центр архитектуры Azure
Создайте индексы для полей в хранилищах данных, на которые часто ссылаются запросы.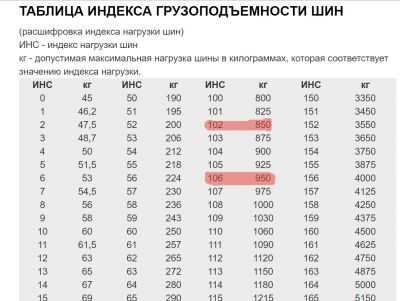 Этот шаблон может повысить производительность запросов, позволяя приложениям быстрее находить данные для извлечения из хранилища данных.
Этот шаблон может повысить производительность запросов, позволяя приложениям быстрее находить данные для извлечения из хранилища данных.
Контекст и проблема
Многие хранилища данных организуют данные для набора сущностей с использованием первичного ключа. Приложение может использовать этот ключ для поиска и извлечения данных. На рисунке показан пример хранилища данных, содержащего информацию о клиентах. Первичный ключ — это идентификатор клиента. На рисунке показана информация о клиенте, упорядоченная по первичному ключу (Customer ID).
Хотя первичный ключ ценен для запросов, извлекающих данные на основе значения этого ключа, приложение может не иметь возможности использовать первичный ключ, если ему необходимо получить данные на основе какого-либо другого поля. В примере с клиентами приложение не может использовать первичный ключ идентификатора клиента для извлечения клиентов, если оно запрашивает данные исключительно со ссылкой на значение какого-либо другого атрибута, например города, в котором находится клиент.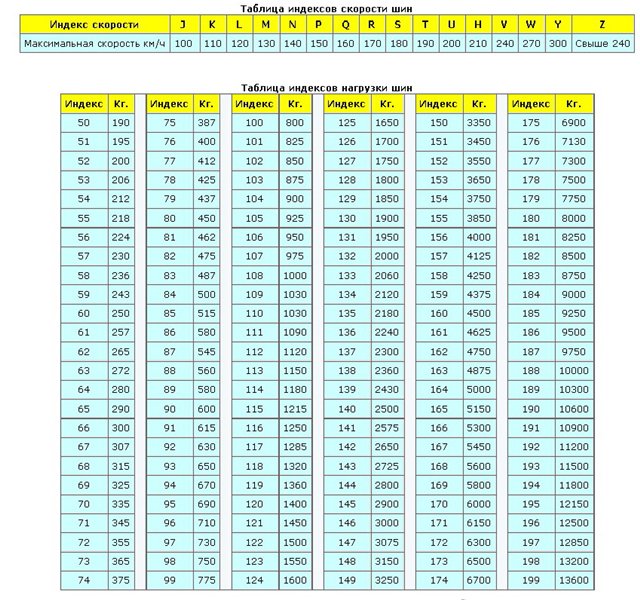 Чтобы выполнить такой запрос, приложению может потребоваться получить и проверить каждую запись о клиенте, что может быть медленным процессом.
Чтобы выполнить такой запрос, приложению может потребоваться получить и проверить каждую запись о клиенте, что может быть медленным процессом.
Многие системы управления реляционными базами данных поддерживают вторичные индексы. Вторичный индекс — это отдельная структура данных, организованная одним или несколькими непервичными (вторичными) ключевыми полями и указывающая, где хранятся данные для каждого индексированного значения. Элементы вторичного индекса обычно сортируются по значению вторичных ключей, чтобы обеспечить быстрый поиск данных. Эти индексы обычно автоматически поддерживаются системой управления базами данных.
Вы можете создать столько вторичных индексов, сколько вам нужно для поддержки различных запросов, выполняемых вашим приложением. Например, в таблице «Клиенты» в реляционной базе данных, где идентификатор клиента является первичным ключом, полезно добавить вторичный индекс к полю города, если приложение часто ищет клиентов по городу, в котором они проживают.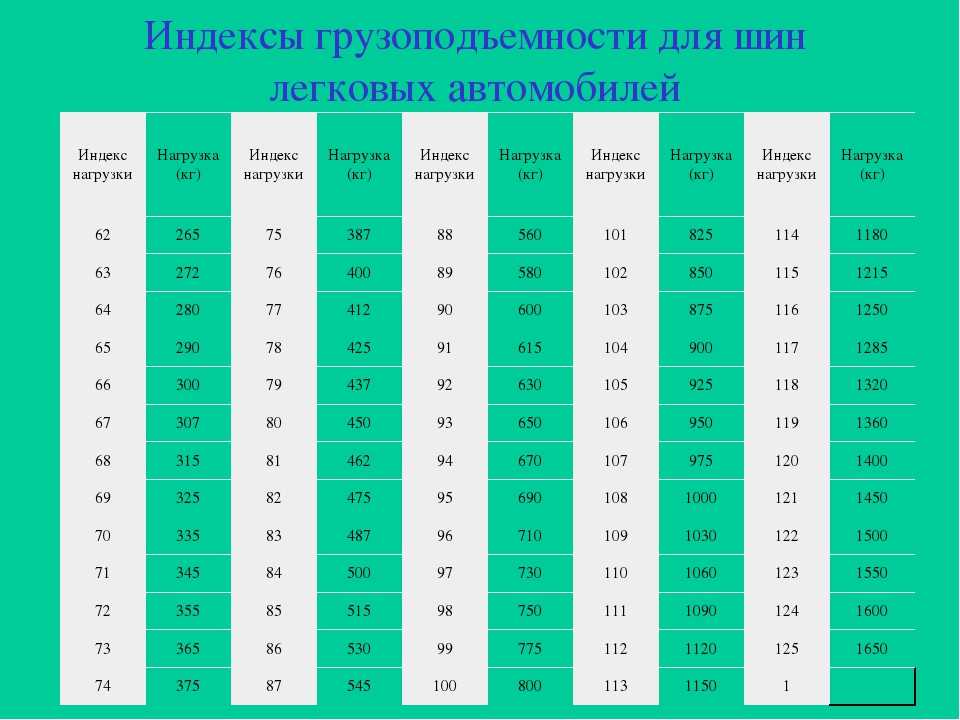
Однако, хотя вторичные индексы распространены в реляционных системах, некоторые хранилища данных NoSQL, используемые облачными приложениями, не предоставляют эквивалентной функции.
Решение
Если хранилище данных не поддерживает вторичные индексы, вы можете эмулировать их вручную, создав собственные индексные таблицы. Индексная таблица упорядочивает данные по указанному ключу. Для структурирования таблицы индексов обычно используются три стратегии, в зависимости от количества требуемых вторичных индексов и характера запросов, выполняемых приложением.
Первая стратегия заключается в дублировании данных в каждой индексной таблице, но организации их по разным ключам (полная денормализация). На следующем рисунке показаны индексные таблицы, в которых одна и та же информация о клиентах организована по городам и фамилиям.
Эта стратегия подходит, если данные относительно статичны по сравнению с тем, сколько раз они запрашивались с использованием каждого ключа. Если данные более динамичны, накладные расходы на обработку каждой индексной таблицы становятся слишком большими, чтобы этот подход был полезен. Кроме того, если объем данных очень велик, объем пространства, необходимый для хранения повторяющихся данных, значителен.
Если данные более динамичны, накладные расходы на обработку каждой индексной таблицы становятся слишком большими, чтобы этот подход был полезен. Кроме того, если объем данных очень велик, объем пространства, необходимый для хранения повторяющихся данных, значителен.
Вторая стратегия заключается в создании нормализованных индексных таблиц, организованных по разным ключам, и ссылки на исходные данные с использованием первичного ключа, а не его дублирования, как показано на следующем рисунке. Исходные данные называются таблицей фактов.
Этот метод экономит место и уменьшает накладные расходы на поддержание дублирующихся данных. Недостатком является то, что приложение должно выполнять две операции поиска, чтобы найти данные с использованием вторичного ключа. Он должен найти первичный ключ для данных в таблице индексов, а затем использовать первичный ключ для поиска данных в таблице фактов.
Третья стратегия заключается в создании частично нормализованных индексных таблиц, организованных по разным ключам, которые дублируют часто извлекаемые поля.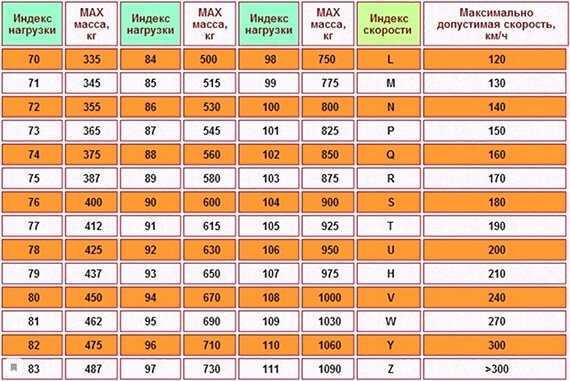 Ссылайтесь на таблицу фактов, чтобы получить доступ к менее часто используемым полям. На следующем рисунке показано, как часто используемые данные дублируются в каждой индексной таблице.
Ссылайтесь на таблицу фактов, чтобы получить доступ к менее часто используемым полям. На следующем рисунке показано, как часто используемые данные дублируются в каждой индексной таблице.
С помощью этой стратегии вы можете найти баланс между первыми двумя подходами. Данные для распространенных запросов можно быстро извлечь с помощью одного поиска, при этом затраты пространства и обслуживания не так значительны, как дублирование всего набора данных.
Если приложение часто запрашивает данные, указывая комбинацию значений (например, «Найти всех клиентов, которые живут в Редмонде и имеют фамилию Смит»), вы можете реализовать ключи к элементам в индексной таблице как конкатенация атрибута Town и атрибута LastName. На следующем рисунке показана индексная таблица на основе составных ключей. Ключи сортируются по Городу, а затем по Фамилии для записей, которые имеют такое же значение для Города.
Таблицы индексов могут ускорить операции запросов к сегментированным данным и особенно полезны, когда ключ сегмента хэшируется. На следующем рисунке показан пример, в котором ключ сегмента является хэшем идентификатора клиента. Таблица индексов может упорядочивать данные по нехэшированным значениям (Город и Фамилия) и предоставлять хешированный ключ сегмента в качестве данных поиска. Это может избавить приложение от многократного вычисления хеш-ключей (дорогостоящая операция), если ему необходимо получить данные, попадающие в диапазон, или ему необходимо получить данные в порядке нехешированного ключа. Например, такой запрос, как «Найти всех клиентов, проживающих в Редмонде», можно быстро решить, найдя соответствующие элементы в индексной таблице, где все они хранятся в непрерывном блоке. Затем следуйте ссылкам на данные клиентов, используя ключи сегментов, хранящиеся в индексной таблице.
На следующем рисунке показан пример, в котором ключ сегмента является хэшем идентификатора клиента. Таблица индексов может упорядочивать данные по нехэшированным значениям (Город и Фамилия) и предоставлять хешированный ключ сегмента в качестве данных поиска. Это может избавить приложение от многократного вычисления хеш-ключей (дорогостоящая операция), если ему необходимо получить данные, попадающие в диапазон, или ему необходимо получить данные в порядке нехешированного ключа. Например, такой запрос, как «Найти всех клиентов, проживающих в Редмонде», можно быстро решить, найдя соответствующие элементы в индексной таблице, где все они хранятся в непрерывном блоке. Затем следуйте ссылкам на данные клиентов, используя ключи сегментов, хранящиеся в индексной таблице.
Вопросы и соображения
При принятии решения о реализации этого шаблона учитывайте следующие моменты:
Накладные расходы на обслуживание вторичных индексов могут быть значительными.
 Вы должны анализировать и понимать запросы, которые использует ваше приложение. Создавайте индексные таблицы только тогда, когда предполагается их регулярное использование. Не создавайте спекулятивные индексные таблицы для поддержки запросов, которые приложение не выполняет или выполняет только время от времени.
Вы должны анализировать и понимать запросы, которые использует ваше приложение. Создавайте индексные таблицы только тогда, когда предполагается их регулярное использование. Не создавайте спекулятивные индексные таблицы для поддержки запросов, которые приложение не выполняет или выполняет только время от времени.Дублирование данных в индексной таблице может привести к значительным накладным расходам на хранение и усилиям, необходимым для поддержки нескольких копий данных.
Реализация индексной таблицы в виде нормализованной структуры, которая ссылается на исходные данные, требует от приложения выполнения двух операций поиска для поиска данных. Первая операция ищет в индексной таблице первичный ключ, а вторая использует первичный ключ для выборки данных.
Если система включает несколько индексных таблиц в очень большие наборы данных, может быть сложно поддерживать согласованность между индексными таблицами и исходными данными.
 Можно было бы спроектировать приложение на основе модели конечной согласованности. Например, чтобы вставить, обновить или удалить данные, приложение может отправить сообщение в очередь и позволить отдельной задаче выполнить операцию и поддерживать индексные таблицы, которые асинхронно ссылаются на эти данные. Дополнительные сведения о реализации окончательной согласованности см. в руководстве по согласованности данных.
Можно было бы спроектировать приложение на основе модели конечной согласованности. Например, чтобы вставить, обновить или удалить данные, приложение может отправить сообщение в очередь и позволить отдельной задаче выполнить операцию и поддерживать индексные таблицы, которые асинхронно ссылаются на эти данные. Дополнительные сведения о реализации окончательной согласованности см. в руководстве по согласованности данных.Таблицы хранилища Microsoft Azure поддерживают транзакционные обновления для изменений, внесенных в данные, хранящиеся в том же разделе (называемые транзакциями групп сущностей). Если вы можете хранить данные для таблицы фактов и одной или нескольких индексных таблиц в одном разделе, вы можете использовать эту функцию для обеспечения согласованности.
Таблицы индексов сами по себе могут быть секционированы или сегментированы.
Когда использовать этот шаблон
Используйте этот шаблон для повышения производительности запросов, когда приложению часто требуется извлекать данные с помощью ключа, отличного от первичного ключа (или сегмента).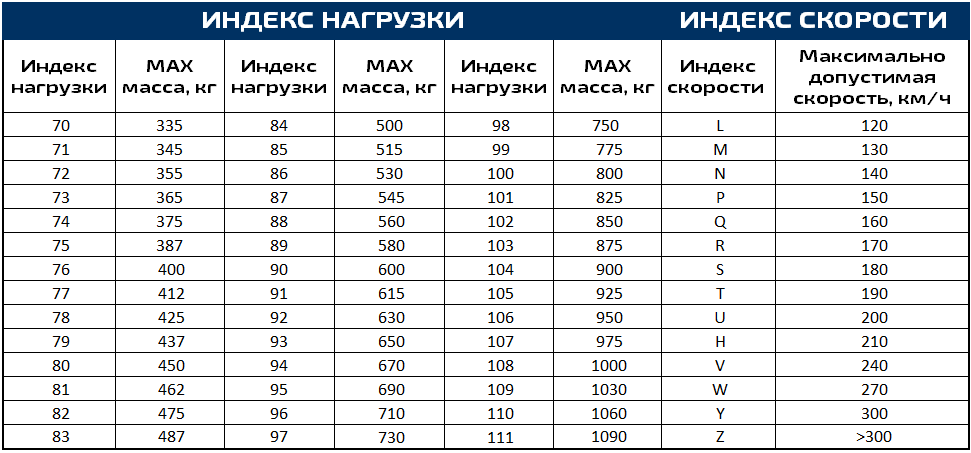
Этот шаблон может быть бесполезен, когда:
- Данные неустойчивы. Индексная таблица может очень быстро устареть, что сделает ее неэффективной или приведет к тому, что накладные расходы на обслуживание индексной таблицы превысят любую экономию, полученную при ее использовании.
- Поле, выбранное в качестве вторичного ключа для индексной таблицы, не является дискриминационным и может иметь только небольшой набор значений (например, пол).
- Баланс значений данных для поля, выбранного в качестве вторичного ключа для индексной таблицы, сильно искажен. Например, если 90% записей содержат одно и то же значение в поле, тогда создание и поддержка индексной таблицы для поиска данных на основе этого поля может создать больше накладных расходов, чем последовательное сканирование данных. Однако, если запросы очень часто нацелены на значения, лежащие в оставшихся 10%, этот индекс может быть полезен. Вы должны понимать, какие запросы выполняет ваше приложение и как часто они выполняются.

Пример
Таблицы хранилища Azure предоставляют масштабируемое хранилище данных типа «ключ-значение» для приложений, работающих в облаке. Приложения сохраняют и извлекают значения данных, указывая ключ. Значения данных могут содержать несколько полей, но структура элемента данных непрозрачна для табличного хранилища, которое просто обрабатывает элемент данных как массив байтов.
Таблицы хранилища Azure также поддерживают сегментирование. Ключ сегментирования состоит из двух элементов: ключа раздела и ключа строки. Элементы с одинаковым ключом раздела хранятся в одном разделе (сегменте), а элементы хранятся в порядке ключа строки внутри сегмента. Хранилище таблиц оптимизировано для выполнения запросов, извлекающих данные, попадающие в непрерывный диапазон значений ключа строки в секции. Если вы создаете облачные приложения, которые хранят информацию в таблицах Azure, вы должны структурировать свои данные с учетом этой функции.
Например, рассмотрим приложение, которое хранит информацию о фильмах. Приложение часто запрашивает фильмы по жанрам (боевики, документальные, исторические, комедии, драмы и т. д.). Вы можете создать таблицу Azure с секциями для каждого жанра, используя жанр в качестве ключа секции и указав имя фильма в качестве ключа строки, как показано на следующем рисунке.
Приложение часто запрашивает фильмы по жанрам (боевики, документальные, исторические, комедии, драмы и т. д.). Вы можете создать таблицу Azure с секциями для каждого жанра, используя жанр в качестве ключа секции и указав имя фильма в качестве ключа строки, как показано на следующем рисунке.
Этот подход менее эффективен, если приложению также необходимо запрашивать фильмы по актерам, играющим главную роль. В этом случае вы можете создать отдельную таблицу Azure, которая действует как индексная таблица. Ключ раздела — это актер, а ключ строки — это имя фильма. Данные для каждого актера будут храниться в отдельных разделах. Если в фильме задействовано более одного актера, один и тот же фильм будет отображаться в нескольких разделах.
Вы можете дублировать данные фильма в значениях, хранящихся в каждом разделе, приняв первый подход, описанный в разделе «Решение» выше. Однако вполне вероятно, что каждый фильм будет реплицироваться несколько раз (один раз для каждого актера), поэтому может быть более эффективным частично денормировать данные для поддержки наиболее распространенных запросов (таких как имена других актеров) и включить приложение. чтобы получить любые оставшиеся сведения, включив ключ раздела, необходимый для поиска полной информации в разделах жанра. Этот подход описан третьим вариантом в разделе «Решение». На следующем рисунке показан этот подход.
чтобы получить любые оставшиеся сведения, включив ключ раздела, необходимый для поиска полной информации в разделах жанра. Этот подход описан третьим вариантом в разделе «Решение». На следующем рисунке показан этот подход.
Следующие шаги
- Учебник по согласованности данных. Индексную таблицу необходимо поддерживать по мере изменения данных, которые она индексирует. В облаке может оказаться невозможным или нецелесообразным выполнять операции по обновлению индекса как часть той же транзакции, которая изменяет данные. В этом случае более подходящим является последовательный в конечном счете подход. Предоставляет информацию о проблемах, связанных с окончательной согласованностью.
Следующие шаблоны также могут иметь значение при реализации этого шаблона:
- Шаблон разделения. Шаблон индексной таблицы часто используется в сочетании с данными, разделенными с помощью осколков. Шаблон сегментирования предоставляет дополнительные сведения о том, как разделить хранилище данных на набор сегментов.

- Шаблон материализованного представления. Вместо индексирования данных для поддержки запросов, обобщающих данные, может быть более целесообразным создать материализованное представление данных. Описывает, как поддерживать эффективные сводные запросы путем создания предварительно заполненных представлений данных.
Как работает индексация | Учебное пособие от Chartio
Что делает индексация?
Индексация — это способ привести неупорядоченную таблицу в порядок, максимально повышающий эффективность запроса при поиске.
Когда таблица не проиндексирована, порядок строк, скорее всего, не будет распознан запросом как оптимизированным каким-либо образом, и поэтому вашему запросу придется искать строки линейно. Другими словами, запросы должны будут выполнять поиск по каждой строке, чтобы найти строки, соответствующие условиям. Как вы понимаете, это может занять много времени. Просмотр каждой строки не очень эффективен.
Например, в таблице ниже представлена таблица в вымышленном источнике данных, которая полностью неупорядочена.
| компания_id | блок | unit_cost |
|---|---|---|
| 10 | 12 | 1,15 |
| 12 | 12 | 1,05 |
| 14 | 18 | 1,31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 16 | 12 | 1,31 |
| 10 | 12 | 1,15 |
| 12 | 24 | 1,3 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1,36 |
| 12 | 12 | 1,05 |
| 20 | 6 | 1,31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 14 | 24 | 1,05 |
Если бы мы выполнили следующий запрос:
SELECT Идентификатор компании, единицы измерения, себестоимость единицы продукции ОТ index_test ГДЕ идентификатор_компании = 18
База данных должна будет выполнить поиск по всем 17 строкам в порядке их появления в таблице, сверху вниз, по одной за раз. Таким образом, для поиска всех потенциальных экземпляров
Таким образом, для поиска всех потенциальных экземпляров company_id число 18, база данных должна просмотреть всю таблицу на наличие всех вхождений 18 в столбце company_id .
Это будет занимать все больше и больше времени по мере увеличения размера таблицы. По мере усложнения данных в конечном итоге может произойти следующее: таблица с одним миллиардом строк соединяется с другой таблицей с одним миллиардом строк; запрос теперь должен выполнять поиск в удвоенном количестве строк, что требует в два раза больше времени.
Вы можете видеть, как это становится проблематичным в нашем постоянно перенасыщенном данными мире. Таблицы увеличиваются в размерах, а время выполнения поиска увеличивается.
Запрос к неиндексированной таблице, если он представлен визуально, будет выглядеть так:
Что делает индексация, так это настраивает столбец, в котором находятся условия поиска, в отсортированном порядке, чтобы помочь оптимизировать производительность запроса.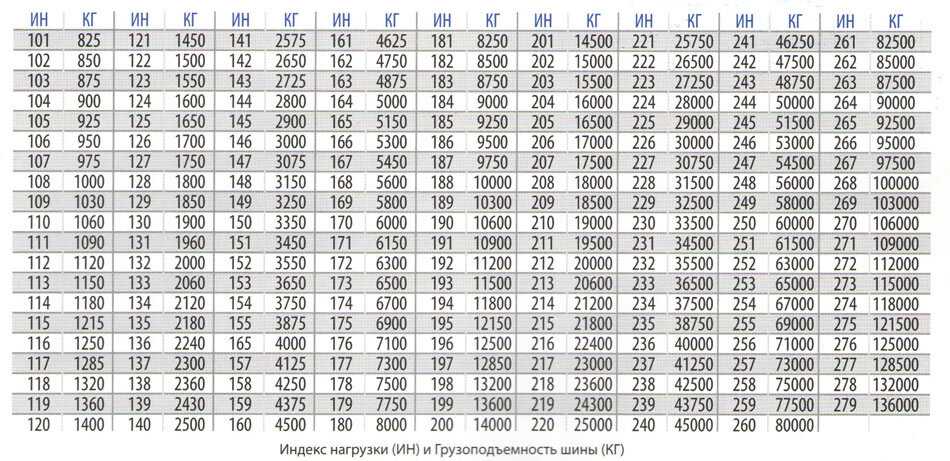
С индексом в столбце company_id таблица будет, по сути, «выглядеть» так:
| company_id | блок | unit_cost |
|---|---|---|
| 10 | 12 | 1,15 |
| 10 | 12 | 1,15 |
| 11 | 24 | 1,15 |
| 11 | 24 | 1,15 |
| 12 | 12 | 1,05 |
| 12 | 24 | 1,3 |
| 12 | 12 | 1,05 |
| 14 | 18 | 1,31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1,05 |
| 16 | 12 | 1,31 |
| 18 | 18 | 1,34 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 18 | 18 | 1,34 |
| 20 | 6 | 1,31 |
| 21 | 18 | 1,36 |
Теперь база данных может искать company_id номер 18 и возвращать все запрошенные столбцы для этой строки, а затем переходить к следующей строке.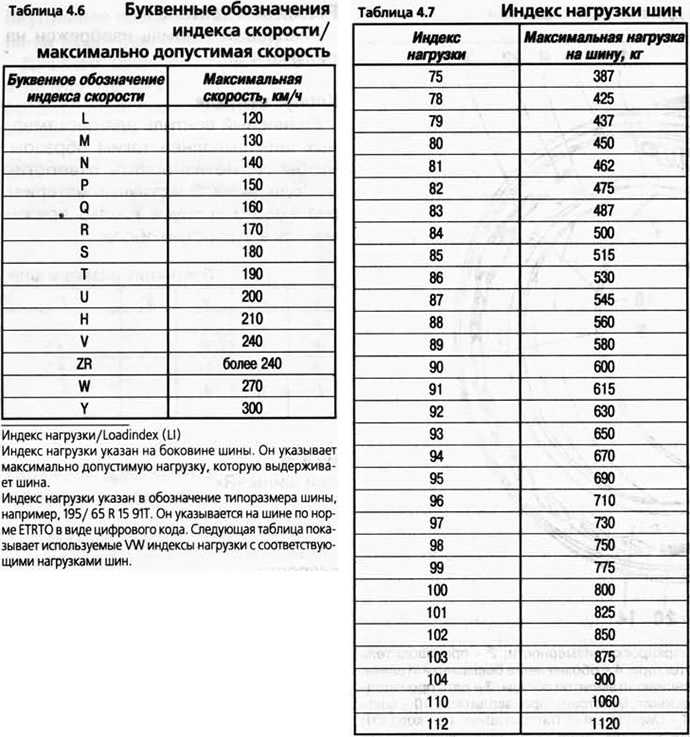 Если в следующей строке
Если в следующей строке comapny_id номер также равен 18, тогда он вернет все столбцы, запрошенные в запросе. Если в следующей строке company_id равен 20, запрос прекращает поиск и завершается.
Как работает индексация?
На самом деле таблица базы данных не переупорядочивается каждый раз при изменении условий запроса для оптимизации производительности запроса: это было бы нереалистично. На самом деле происходит то, что индекс заставляет базу данных создавать структуру данных. Тип структуры данных, скорее всего, B-Tree. Несмотря на множество преимуществ B-дерева, основное преимущество для наших целей заключается в том, что его можно сортировать. Когда структура данных отсортирована по порядку, это делает наш поиск более эффективным по очевидным причинам, которые мы указали выше.
Когда индекс создает структуру данных для определенного столбца, важно отметить, что никакой другой столбец не сохраняется в структуре данных. Наша структура данных для приведенной выше таблицы будет содержать только номера company_id .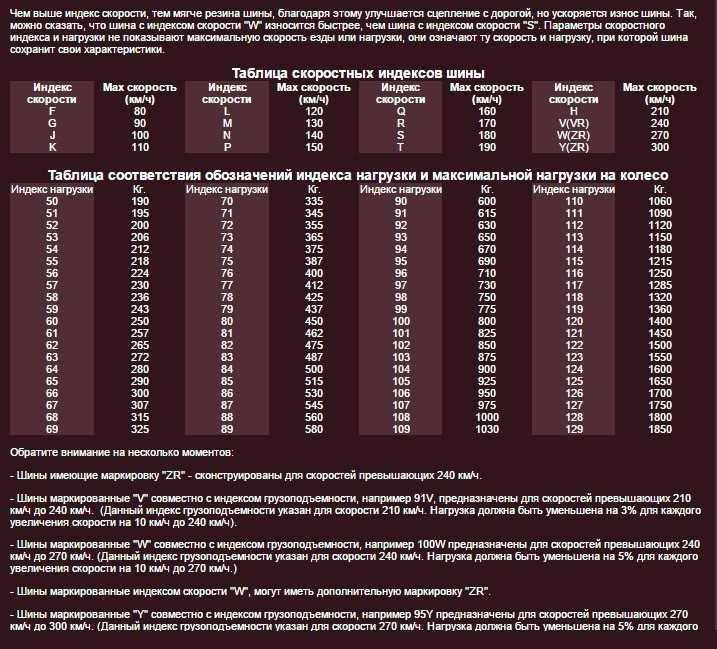 Units и
Units и unit_cost не будут храниться в структуре данных.
Откуда база данных узнает, какие еще поля в таблице нужно вернуть?
Индексы базы данных также будут хранить указатели, которые являются просто справочной информацией о расположении дополнительной информации в памяти. В основном индекс держит company_id и домашний адрес этой конкретной строки на диске памяти. На самом деле индекс будет выглядеть так:
| company_id | указатель |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
С помощью этого индекса запрос может искать только строки в столбце company_id , которые имеют 18, а затем с помощью указателя можно перейти в таблицу, чтобы найти конкретную строку, в которой находится этот указатель.