1.2.2. Случайные погрешности
Случайные погрешности вызываются большой совокупностью причин, остающихся при проведении измерений неизвестными. Случайные погрешности неизбежны и неустранимы. Случайная погрешность, как и всякая случайная величина, наиболее полно характеризуется законом распределения. В практике встречаются различные законы распределения случайных погрешностей. Наиболее часто приходиться иметь дело с нормальным законом распределения, но встречаются также: равномерный закон распределения; треугольный закон (закон Симпсона) и др. [6, 8].
Таким образом, погрешность результата измерений в общем случае включает систематическую и случайную составляющие
(1.5)
(грубая погрешность входит в состав случайной погрешности).
В
выражении (1.5) перед составляющими
погрешности оставлен только знак “+”, но и здесь, и далее следует иметь ввиду что может иметь как знак “+”, так и знак
“-“, а если систематическая погрешность
задана в виде границ (как чаще всего и
бывает для неисключенных остатков
систематической погрешности), то перед
значением подразумевается знак “”
(т.
В соответствии с законами теории вероятностей погрешность , записанная в форме (1.5), также становиться случайной величиной, имеющей тот же закон распределения, что и . Все сказанное в равной мере относится и к результату измерения, если на основании (1.2) и (1.5) его записать в виде
(1.6)
Из теории вероятностей известно, что закон распределения можно охарактеризовать числовыми характеристиками, которые являются уже неслучайными величинами. Эти характеристики и используются для количественной оценки случайной погрешности.
Основными числовыми характеристиками законов распределения погрешности , записанной в виде (1.5), являются
Математическое ожидание —
, (1.7)
где — плотность вероятности погрешности ;
и дисперсия —
. (1.8)
(1.8)
Математическое ожидание погрешности измерений, вычисляемое в соответствии с (1.7) есть неслучайная величина, она характеризует систематическую составляющую погрешности измерения. Т.е. , для чисто случайной погрешности (когда ) .
Дисперсия характеризует степень разброса отдельных значений погрешности относительно и может служить характеристикой точности проведенных измерений, но имеет размерность в единицах измеряемой величины в квадрате. Поэтому в качестве числовой характеристики случайной погрешности чаще используют
(1.9)
Положительное значение , вычисленное в соответствии с (1.9), называется средним квадратическим отклонением (СКО) случайной величины , а применительно к погрешностям измерений ее следует называть средней квадратической погрешностью (СКП) результата измерений.
Графическое
представление нормального закона
распределения случайных погрешностей
(дифференциальная функция распределения или плотность вероятностей) приведена
на рисунке 1. 5, а аналитическое выражение
этого закона имеет вид:
5, а аналитическое выражение
этого закона имеет вид:
(1.10)
В такой форме записи вид кривой распределения будет изменяться в зависимости от величины (см. рис. 1.5), но если характеризовать случайную погрешность безразмерным нормированным числом (нормировка относительно СКП), то получим кривую нормированного нормального распределения
, (1.11)
с аргументом
. (1.12)
Вид кривой нормированного нормального распределения чисто случайной погрешности () приведен на рисунке 1.6.
Графическое представление дифференциальной функции равномерного и треугольного законов распределения приведены на рисунке 1.7 и рисунке 1.8. Аналитическая запись этих законов распределения представлена выражениями (1.13) и (1.14) соответственно.
Часто
по условиям измерительной задачи
требуется найти максимальную (предельную)
случайную погрешность, которая может
иметь место. Максимальная случайная
погрешность ()
связана с и зависит
от закона распределения
Максимальная случайная
погрешность ()
связана с и зависит
от закона распределения
. (1.15)
Для других законов распределения соотношения между и отличаются от (1.15). Так для равномерного закона распределения ; для треугольного соответственно и т.д. [8].
Определить числовые характеристики случайной погрешности воспользовавшись (1.7) и (1.8) можно только в том случае, если известно аналитическое описание закона распределения .
Рисунок 1.5
Рисунок 1.6
(1.13)
Рисунок 1.7
(1.14)
Рисунок 1.8
На
практике числовые характеристики
случайной погрешности приходится
находить путем соответствующей
математической обработки результатов
измерений.
Если все результаты полученного ряда исправлены (т.е. не содержат систематических погрешностей), то пользуясь правилами теории вероятностей можно найти действительное значение измеряемой ФВ и числовые характеристики случайной погрешности. При этом следует учитывать тот факт, что числовые характеристики и находятся всегда на основании ограниченного ряда результатов измерений (на практике n всегда конечное число, т.е. ). Поэтому в результате вычислений при обработке результатов измерений находим не теоретические значения и , а их оценки
 Для
вычисления оценок в соответствии с ГОСТ
8.207-76 используются следующие формулы:
Для
вычисления оценок в соответствии с ГОСТ
8.207-76 используются следующие формулы:; (1.16)
. (1.17)
где — среднее арифметическое значение результатов серии из n измерений (оценка математического ожидания результата измерений), оценка действительного значения измеряемой ФВ;
— оценка средней квадратической погрешности единичного измерения в ряду равноточных измерений.
Средняя квадратическая погрешность и ее оценка , полученная путем обработки опытных данных, является основным показателем точности применительно к случайным погрешностям измерений. Но кроме этого показателя иногда (например, в экспериментальной физике) применяются и другие показатели точности: средняя абсолютная погрешность (САП), мера точности. Соотношения между этими показателями для нормального распределения следующие:
Вероятная погрешность — ,
,
погрешность, соответствующая доверительному интервалу при ;
Средняя арифметическая погрешность (САП) — ,
(теоретическое значение),
оценка САП по экспериментальным данным для большого количества наблюдений, или
оценка САП при малом количестве экспериментальных данных;
Мера точности — ,
.
Точность оценок, полученных по формулам (1.16) и (1.17) растет с увеличением n
Поскольку при вычислении по формуле (1.16) получаем оценку математического ожидания и эту оценку принимаем за результат измерения, необходимо знать степень разброса величины относительно . Характеристикой меры разброса служит оценка средней квадратической погрешности среднего арифметического — , вычисляемая по формуле:
. (1.18)
Как следует из (1.18) средняя квадратическая погрешность среднего арифметического в раз меньше средней квадратической погрешности единичного измерения .
Полученные
в соответствии с (1.17) и (1.18) оценки СКП имеют
размерность измеряемой ФВ,
т.е. выражены в абсолютной форме. Для
выражения этих оценок в относительной
форме следует поступать по общему
правилу (см.
; .
и могут быть выражены как безразмерным числом, так и в процентах, что чаще всего и бывает.
Полученные по формулам (1.16 — 1.18) числовые характеристики выражаются определенным числом и называются точечными оценками.
С использование точечных оценок результат измерения с учетом случайной погрешности может быть представлен в виде :
. (1.19)
Такая запись говорит о том, что действительное значение измеряемой ФВ может находиться в интервале значений до . Вероятность этого события пока не определена. Более того, результат измерения может находиться и вне интервала ограниченного значения и . Вероятность этого события также пока не определена. Более полную информацию о действительном значении измеряемой величины дает представление результата измерения в виде

Для результата измерения доверительным называется интервал, который с заданной вероятностью, называемой доверительной вероятностью (), включает действительное значение измеряемой ФВ, т.е. это интервал значений (, ), для которого
(1.20)
Для случайной погрешности доверительным интервалом называется интервал значений случайной погрешности, внутри которого с заданной вероятностью находится искомое значение погрешности , т.е.
. (1.21)
При
определении доверительных интервалов
доверительной вероятностью задаются
(если она не задана условиями измерительной
задачи). В зависимости от условий
измерений и конкретных требований принимают, например, равной от 0.9 до
0.999. Чем больше принятое значение
,
тем более надежно будет оценен интервал,
но тем шире будут его границы, т.е.
надежность оценок (,
)
будет выше. Для технических измерений
при нормальном законе распределения в
большинстве случаев достаточной
считается величина
.
Следует заметить, что точечная оценка , полученная на основании экспериментальных данных при ограниченном числе измерений n остается случайной величиной (так, например, если обработать другую выборку результатов измерения той же ФВ с другим числом измерений , то получим новую оценку , немного отличающуюся от ). Следовательно может быть рассмотрена задача о определении доверительного интервала для оценки средней квадратической погрешности среднего арифметического при некоторой доверительной вероятности. Методику определения доверительного интервала для , при необходимости, можно найти в [5, 6].
При
определении характеристик случайной
погрешности приходиться решать как
задачи определения доверительных границ
СКП при заданной доверительной
вероятности, так и обратную задачу,
определения доверительной вероятности с которой СКП не выйдет за границы
заданного (симметричного или
несимметричного) интервала при заданном
законе распределения случайной
погрешности.
Границы симметричного доверительного интервала (), за пределы которого с заданной доверительной вероятностью не выходят случайные погрешности результата статистических измерений, определяют в соответствии с выражением:
, (1.22)
где — безразмерный коэффициент, определяемый задаваемой доверительной вероятностью () и видом закона распределения случайных погрешностей.
При несимметричном задании доверительного интервала говорят о нижней — и верхней — границах интервала для случайной погрешности результата измерений. Выражение (1.21) в этом случае следует записать в виде:
,
а вероятность того, что случайная погрешность окажется внутри указанного интервала определяется в общем случае в соответствии с выражением
(1.23)
Для
случайной погрешности, распределенной
по нормальному закону, выражение (1. 23),
с использованием нормированной функции
нормального распределения (1.11), можно
записать в виде:
23),
с использованием нормированной функции
нормального распределения (1.11), можно
записать в виде:
, (1.24)
где — значение безразмерного коэффициента для нижней границы доверительного интервала;
— значение того же коэффициента для верхней границы доверительного интервала. Для симметричного интервала () (1.24) можно переписать в виде:
. (1.25)
Интеграл вида:
(1.26)
называется
нормированной функцией Лапласа или
интегралом вероятностей. Значения этого
интеграла или интеграла вида (1.25) для
различных значений аргумента приводятся
в справочных таблицах (см. таблицу 1
приложения в методических указаниях),
с
использованием которых можно решить
прямую и обратную задачи определения
характеристик случайной погрешности, распределенной
по нормальному закону.
При этом не следует забывать, что
пользуясь табличными значениями
интеграла вида (1. 25) находим полную
вероятность попадания в симметричный интервал с
границами
,
а пользуясь табличными значениями
интеграла вида (1.26) — только половину
полной вероятности для одной части
симметричного доверительного интервала.
При решении этих задач можно использовать
также таблицы значений нормированной
интегральной функции нормального
распределения вида:
25) находим полную
вероятность попадания в симметричный интервал с
границами
,
а пользуясь табличными значениями
интеграла вида (1.26) — только половину
полной вероятности для одной части
симметричного доверительного интервала.
При решении этих задач можно использовать
также таблицы значений нормированной
интегральной функции нормального
распределения вида:
(1.27)
С использованием табличных значений функции (см. таблицу 2 приложения в методических указаниях) выражение (1.24) для доверительной вероятности нахождения случайной погрешности внутри несимметричного интервала от до записывается следующим образом:
(1.28)
Табличными значениями нормированной функции Лапласа удобно пользоваться для решения задач при симметричном задании доверительного интервала, а табличными значениями нормированной интегральной функции — при несимметричном.
При
определении числовых характеристик
случайной погрешности по результатам
эксперимента табличные значения
интегралов вида (1. 25) и (1.28) следует
использовать в том случае, если количество
наблюдений в выборке достаточно велико
().
При малом n точечные оценки случайной погрешности
сами становятся случайными величинами.
Учитывая это, выражение (1.12) для
нормированного отклонения результата
измерений от действительного значения
при следует записать в виде:
25) и (1.28) следует
использовать в том случае, если количество
наблюдений в выборке достаточно велико
().
При малом n точечные оценки случайной погрешности
сами становятся случайными величинами.
Учитывая это, выражение (1.12) для
нормированного отклонения результата
измерений от действительного значения
при следует записать в виде:
. (1.29)
Использование символа в (1.29) подчеркивает тот факт, что нормированное отклонение определено с использованием оценок ( и ) полученных при обработке выборки малого объема.
Величина
,
таким образом, является некоторой
функцией числа наблюдений в выборке n.
Следовательно и границы доверительного
интервала определяемые в соответствии
с (1.22) будут зависеть не только от
доверительной вероятности, но и от числа
наблюдений n.
Закон
распределения случайной величины отличается от нормального и называется
распределением Стьюдента. Это различие
существенно при малых n,
а при распределение Стьюдента полностью
совпадает с нормальным. Таким образом, при обработке
результатов статистических измерений
при малом количестве наблюдений ()
доверительный интервал следует определять
с использованием распределения Стьюдента. Чтобы подчеркнуть, что в этом случае
коэффициент t в (1.22)
зависит не только от доверительной
вероятности
,
но и от числа наблюдений n,
выражение (1.22) записывается в виде:
Таким образом, при обработке
результатов статистических измерений
при малом количестве наблюдений ()
доверительный интервал следует определять
с использованием распределения Стьюдента. Чтобы подчеркнуть, что в этом случае
коэффициент t в (1.22)
зависит не только от доверительной
вероятности
,
но и от числа наблюдений n,
выражение (1.22) записывается в виде:
(1.30)
где — коэффициент, определяемый по таблицам распределения Стьюдента при выбранной доверительной вероятности для конкретного количества наблюдений n.
Распределение Стьюдента также табулировано и значения коэффициента при выбранной доверительной вероятности для каждого конкретного значения n можно определить по таблице 4 (см. приложение в методических указаниях).
Формулой
(1.22) для определения границ симметричного
доверительного интервала можно
пользоваться при любом законе распределения
случайной погрешности, если имеются таблицы соответствующего
закона распределения аналогичные таблицам 1 и 2 (см. приложение
в методических указаниях). К сожалению,
для других законов распределения (кроме
нормального) такие таблицы не получили
широкого применения. Но анализ интегральных
кривых различных законов распределения
обнаружил уникальное свойство
доверительного интервала, соответствующего
доверительной вероятности
.
Оказалось, что для широкого класса
симметричных распределений (нормального,
равномерного, треугольного, трапецеидального,
экспоненциального и даже ряда двухмодальных
законов) с погрешностью не более 10%
границы симметричного доверительного
интервала при равны [8].
Поэтому ГОСТ 11.001-73 предписывает при
отсутствии данных о виде закона
распределения определять симметричный доверительный
интервал только при пользуясь соотношением:
приложение
в методических указаниях). К сожалению,
для других законов распределения (кроме
нормального) такие таблицы не получили
широкого применения. Но анализ интегральных
кривых различных законов распределения
обнаружил уникальное свойство
доверительного интервала, соответствующего
доверительной вероятности
.
Оказалось, что для широкого класса
симметричных распределений (нормального,
равномерного, треугольного, трапецеидального,
экспоненциального и даже ряда двухмодальных
законов) с погрешностью не более 10%
границы симметричного доверительного
интервала при равны [8].
Поэтому ГОСТ 11.001-73 предписывает при
отсутствии данных о виде закона
распределения определять симметричный доверительный
интервал только при пользуясь соотношением:
.
Таким же образом следует определять доверительный интервал для перечисленных выше законов распределение при отсутствии таблиц соответствующего распределения.
Результат измерений с многократными наблюдениями, при указании случайной погрешности в виде симметричного доверительного интервала должен быть представлен в виде:
(1. 31)
31)
Как уже отмечалось, ряд экспериментальных данных, полученных при многократном измерении одного и того же значения измеряемой ФВ, может содержать результаты, имеющие в своем составе грубые погрешности. Для того, чтобы эти данные не искажали результат измерений, их следует исключить до того, как будет определяться оценка и доверительный интервал (или ). Эта процедура называется исключением грубых погрешностей. Статистический критерий обнаружения грубых погрешностей разработан для случая, когда группа обрабатываемых данных подчиняется нормальному закону распределения. В этом случае теория вероятностей позволяет при выбранной доверительной вероятности рассчитать теоретически допустимые границы максимальных (по модулю) нормированных отклонений для выборки из n наблюдений
(1.32)
Теоретически
допустимые границы табулированы для различных значений n при разных
уровнях доверительной вероятности (или разных уровнях значимости g,
где
). Табличные значения приведены в таблице 3
приложения в методических указаниях.
Табличные значения приведены в таблице 3
приложения в методических указаниях.
Применение статистического критерия обнаружения грубых погрешностей регламентировано ГОСТ 11.002-73 и состоит в следующем. После определения и для некоторого , который резко выделяется из общей совокупности обрабатываемых результатов, определяют величину нормированного отклонения
. (1.33)
Задав уровень доверительной вероятности по таблице 3 (см. приложение в методических указаниях) для числа n, соответствующего обрабатываемой выборке, находят допустимое нормированное отклонение .
Если , то результат можно отбросить. В противном случае результат должен быть оставлен.
Если после исключения вызывает сомнение какое-либо другое данное, то указанный порядок действий(определение ; и ) повторяют, но уже не учитывая исключенное данное .
Следует
подчеркнуть, что
если нет достаточных оснований считать
обрабатываемую совокупность результатов
нормально распределенной, описанный
критерий обнаружения
грубых погрешностей применять
нельзя.
Если о виде распределения опытных данных заранее ничего определенного сказать нельзя, то прежде чем исключать грубые погрешности, определять и необходимо проверить гипотезу о принадлежности группы экспериментальных данных нормальному распределению. Проверить гипотезу о том, что распределение опытных данных не противоречит теоретическому, можно по ряду критериев. Но следует иметь ввиду, что при n<10 проверить гипотезу о виде распределения экспериментальных данных невозможно. При проверка гипотезы затруднена, в этом случае пользуются, как правило, составным критерием [5]. При достаточно большом числе данных () лучшим критерием проверки гипотезы о виде распределения является критерий (или критерий согласия К. Пирсона) [5, 6].
Критерий
Пирсона используется для проверки
согласия распределения предварительно
сгруппированных по интервалам опытных
данных теоретическому распределению. Идея метода состоит в контроле отклонения
гистограммы опытных данных от гистограммы
с таким же числом интервалов, построенной
на основе теоретического распределения. Мерой
расхождения служит сумма квадратов разностей
экспериментального количества
результатов, попавших в соответствующий
интервал, и количества результатов, которые
теоретически должны попадать в этот интервал. Сумма квадратов разностей
()
не должна выходить за границы
(),определенные
по таблицам
-распределения
(таблица 5
см.
приложение
в
методических указаниях) при
заданном уровне доверительной вероятности
(или уровне значимости
).
Положительный ответ, полученный при
использовании критерия согласия
,
следует трактовать так, что
распределение опытных данных не
противоречит теоретическому (на соответствие которому проверялось). Но это не
означает что оно полностью соответствует
теоретическому.
При определенной доверительной
вероятности критерийможет
дать положительный результат и для
некоторого другого теоретического
закона распределения.
Идея метода состоит в контроле отклонения
гистограммы опытных данных от гистограммы
с таким же числом интервалов, построенной
на основе теоретического распределения. Мерой
расхождения служит сумма квадратов разностей
экспериментального количества
результатов, попавших в соответствующий
интервал, и количества результатов, которые
теоретически должны попадать в этот интервал. Сумма квадратов разностей
()
не должна выходить за границы
(),определенные
по таблицам
-распределения
(таблица 5
см.
приложение
в
методических указаниях) при
заданном уровне доверительной вероятности
(или уровне значимости
).
Положительный ответ, полученный при
использовании критерия согласия
,
следует трактовать так, что
распределение опытных данных не
противоречит теоретическому (на соответствие которому проверялось). Но это не
означает что оно полностью соответствует
теоретическому.
При определенной доверительной
вероятности критерийможет
дать положительный результат и для
некоторого другого теоретического
закона распределения. Однозначным
ответом является лишь отрицательный
результат применения критерия
,
который трактуется так: распределение
опытных данных не
соответствует теоретическому, на соответствие которому
проверялось. Таким образом при
использовании критерия согласия Пирсона
следует помнить следующее.
Однозначным
ответом является лишь отрицательный
результат применения критерия
,
который трактуется так: распределение
опытных данных не
соответствует теоретическому, на соответствие которому
проверялось. Таким образом при
использовании критерия согласия Пирсона
следует помнить следующее.
Критерий позволяет проверить соответствие опытных данных любому (выбранному заранее по каким либо признакам) теоретическому распределению, а не только нормальному. Однако этот критерий (как, впрочем, и другие критерии согласия) не позволяет однозначно установить вид распределения этих данных.
Методика использования критерия с необходимыми пояснениями приводится на примере в п.1.3.4.
Методы повышения точности измерений
Анализ причин появления погрешностей измерений, выбор способов их обнаружения и уменьшения являются основными этапами процесса измерений. Погрешности измерений, принято делить на систематические и случайные. В процессе измерений систематические и случайные погрешности проявляются совместно и образуют нестационарный случайный процесс. Деление погрешностей на систематические и случайные является удобным приемом для их анализа и разработки методов уменьшения их влияния на результат измерения.
В процессе измерений систематические и случайные погрешности проявляются совместно и образуют нестационарный случайный процесс. Деление погрешностей на систематические и случайные является удобным приемом для их анализа и разработки методов уменьшения их влияния на результат измерения.
Рассмотрим способы обнаружения и исключения систематических погрешностей, поскольку они зависят от выбора метода измерений и его осуществелния.
По характеру изменения систематические погрешности делятся:
- постоянные – погрешности, связанные с неточной градуировкой шкалы прибора, отклонением размера меры от номинального значения, неточным выбором моделей объектов.
- переменные
– периодические – погрешность изменяющаяся по периодическому закону, например погрешность отсчета при определении времени по башенным часам, если смотреть на стрелку снизу, температурная погрешность от изменения температуры в течение суток и т. п.
п.
– прогрессирующие – погрешности монотонно изменяющиеся (увеличивающиеся или уменьшающиеся) в общем случае по сложному, обычно неизвестному закону. Прогрессирующие погрешности во многих случаях обусловлены старением элементов средств измерений и могут быть скорректированы при его периодической поверке.
По причине возникновения погрешности измерений разделяются на три основные группы:
- методические – погрешности обусловленные неадекватностью принимаемых моделей реальным объектам, несовершенством методов измерений, упрощением зависимостей, положенных в основу измерений, неопределенностью объекта измерения;
- инструментальные – погрешности обусловленные прежде всего особенностями используемых в средствах измерений принципов и методов измерений, а также схемным, конструктивным и технологическим несовершенством средств измерений.
- взаимодейтствия – обусловлены взаимным влиянием средства измерений, объекта исследования и экспериментатора.
 Погрешности из-за взаимного влияния средства и объекта измерений обычно принято относить к методическим погрешностям, а погрешности, связанные с действиями экспериментатора, называются личными погрешностями. Однако такая классификация недостаточно полно отражает суть рассматриваемых погрешностей.
Погрешности из-за взаимного влияния средства и объекта измерений обычно принято относить к методическим погрешностям, а погрешности, связанные с действиями экспериментатора, называются личными погрешностями. Однако такая классификация недостаточно полно отражает суть рассматриваемых погрешностей.
Выявление и устранение причин возникновения погрешностей – наиболее распространенный способ уменьшения всех видов систематических погрешностей. Примерами такого способа являются: термостатирование отдельных узлов или прибора в целом, а также проведение измерений в термостатированных помещениях для исключения температурной погрешности, применение экранов, фильтров и специальных цепей (например, эквипотенциальных цепей) для устранения погрешностей из-за влияния электромагнитных полей, наводок и токов утечек, применение стабилизированных источников питания.
Для уменьшения прогрессирующей погрешности из-за старения элементов средств измерений, параметры таких элементов стабилизируют путем искусственного и естественного старения. Кроме этого систематические погрешности можно уменьшить рациональным расположением средств измерений по отношению друг к другу, к источнику влияющих воздействий и к объекту исследования. Например магнитоэлектрические приборы должны быть удалены друг от друга, оси катушек индуктивности, должны быть расположены под углом 90°, выводы термопары должны располагаться по изотермическим линиям объекта.
Кроме этого систематические погрешности можно уменьшить рациональным расположением средств измерений по отношению друг к другу, к источнику влияющих воздействий и к объекту исследования. Например магнитоэлектрические приборы должны быть удалены друг от друга, оси катушек индуктивности, должны быть расположены под углом 90°, выводы термопары должны располагаться по изотермическим линиям объекта.
Многие систематические погрешности, являющиеся не изменяющимися во времени функциями влияющих величин или обусловленные стабильными физическими эффектами, могут быть теоретически рассчитаны и устранены введением поправок или использованием специальных корректирующих цепей.
Другим радикальным способом устранения систематических погрешностей является поверки средств измерений в рабочих условиях с целью определения поправок к результатам измерения. Это дает возможность учесть все систематические погрешности без выяснения причин их возникновения. Степень коррекции систематических погрешностей в этом случае, естественно, зависит от метрологических характеристик используемых эталонных приборов и случайных погрешностей поверяемых приборов.
Фактически поверка средств измерений перед их использованием и введение поправок адекватна применению средств измерений более высоких классов точности при условии, что случайные погрешности средств измерений малы по сравнению с систематическими, а сами систематические погрешности медленно изменяются во времени.
Метод инвертирования широко используется для устранения ряда постоянных и медленно изменяющихся систематических погрешностей. Этот метод и ряд его разновидностей (метод исключения погрешности по знаку, коммутационного инвертирования, структурной модуляции, двукратных измерений, инвертирования функции преобразования и др.) основаны на выделении алгебраической суммы чесного числа сигналов измерительной информации, которые вследствие инвертирования отличаются направлением информативного сигнала, опорного сигнала или знаком погрешности.
Метод модуляции – метод близкий к методу инвертирования, в котором производится периодическое инвертирование входного сигнала и подавление помехи, имеющей однонаправленное действие.
Метод исключения погрешности по знаку — вариант метода инвертирования, который часто применяется для исключения известных по природе погрешностей, источники которых имеют направленное действие, например погрешностей из-за влияния постоянных магнитных полей, ТЭДС и др.
Метод замещения (метод разновременного сравнения) является наиболее универсальным методом, который дает возможность устранить большинство систематических погрешностей. Измерения осуществляются в два приема. Сначала по отсчетному устройству прибора делают отсчет измеряемой величины, затем, сохраняя все условия эксперимента неизменными, вместо измеряемой величины на вход прибора подают известную величину, значение которой с помощью регулируемой меры (калибратором) устанавливают таким образом, чтобы показание прибора было таким же, как при включении измеряемой величины.
Метод равномерного компарирования является разновидностью метода замещения, он используется при измерениях таких величин, которые нельзя с высокой точностью воспроизводить с помощью регулируемых мер или других технических средств. Обычно это величины, изменяющиеся с высокой частотой или по сложному закону. В качестве известных регулируемых величин при этом используются величины такого же рода, как измеряемые, но отличаютщиеся от них спектральным составом (обычно постоянные во времени и в пространстве) и создающие такой же, как и измеряемая величина, сигнал на выходе компарирующего преобразователя.
Обычно это величины, изменяющиеся с высокой частотой или по сложному закону. В качестве известных регулируемых величин при этом используются величины такого же рода, как измеряемые, но отличаютщиеся от них спектральным составом (обычно постоянные во времени и в пространстве) и создающие такой же, как и измеряемая величина, сигнал на выходе компарирующего преобразователя.
Метод эталонных сигналов заключается в том, что на вход средств измерений периодически вместо измеряемой величины подаются эталонные сигналы такого же рода, что и измеряемая величина. Разность между реальной градуировочной характеристикой используется для коррекции чувствительности или для автоматического введения поправки в результат измерения. При этом, как и при методе замещения, устраняются все систематические погрешности, но только в тех точках диапазона измерений, которые соответствуют эталонным сигналам. Метод широко используется в современных точных цифровых приборах и в информационно-измерительных системах. Примером использования этого метода является периодическая подстройка рабочего тока в компенсаторах и цифровых вольтметрах постоянного тока при помощи нормального элемента.
Примером использования этого метода является периодическая подстройка рабочего тока в компенсаторах и цифровых вольтметрах постоянного тока при помощи нормального элемента.
Тестовый метод – при использовании данного метода значение измеряемой величины определяется по результатам нескольких наблюдений, при которых в одном случае входным сигналом средства измерений является сама измеряемая величина Х, а в других – так называемые тесты, являющиеся функциями измеряемой величины.
Метод вспомагательных измерений используется для исключения погрешностей из-за влияющих величин и неинформативных параметров входного сигнала. Для реальзации этого метода одновременно с измеряемой величиной Х с помощью вспомогательных измерительных устройств производится измерение каждой из влияющих величин и вычисление с помощью вычислительного устройства, а также формул и алгоритмов поправок к результатам измерения.
Метод симметричных наблюдений заключается в проведении многократных наблюдений через равные промежутки времени и усреднении результатов наблюдений, симметрично расположенных относительно среднего наблюдения. Обычно этот метод применяется для исключения прогрессирующих погрешностей, изменяющихся по линейному закону. Так, при измерении сопротивления резистора путем сравнения напряжения на измеряемом и эталонном резисторах, включенных последовательно и питаемых от общего аккумулятора, может возникнуть погрешность вследствие разряда источника питания.
Обычно этот метод применяется для исключения прогрессирующих погрешностей, изменяющихся по линейному закону. Так, при измерении сопротивления резистора путем сравнения напряжения на измеряемом и эталонном резисторах, включенных последовательно и питаемых от общего аккумулятора, может возникнуть погрешность вследствие разряда источника питания.
Для исключения этой погрешности проводят три измерения падения напряжения:
- на эталонном резисторе U01 = I·R0;
- через равные промежутки времени на измеряемом резисторе UX = (I — ΔI1)·RX;
- снова на эталонном резисторе U02 = (I — ΔI2)·R0.
- Если ток изменяется во времени по линейному закону, то ΔI2 = 2ΔI1; I — ΔI1 = (U01 + U02) / (2R0) и RX = R0·2·UX / (U01 + U02).
Метод симметричных наблюдений можно также использовать для устранения других видов погрешностей, например систематических погрешностей из-за влияющих величин, изменяющихся по периодическому закону. В этом случае симметричные наблюдения проводят через половину периода, когда погрешность имеет разные знаки, но одинаковые значения. Таким образом, например, можно исключить погрешность из-за наличия четных гармоник при измерении амплитудного значения напряжения при искаженной форме кривой.
Таким образом, например, можно исключить погрешность из-за наличия четных гармоник при измерении амплитудного значения напряжения при искаженной форме кривой.
Случайная ошибка — Основы эпидемиологии
Прочитав эту главу, вы сможете сделать следующее:
- Определить случайную ошибку и отличить ее от смещения
- Проиллюстрируйте случайную ошибку примерами
- Интерпретировать p -значение
- Интерпретация доверительного интервала
- Различать статистические ошибки типа 1 и типа 2 и объяснять, как они применимы к эпидемиологическим исследованиям
- Опишите, как статистическая мощность влияет на исследования
В этой главе мы рассмотрим — откуда он взялся, как мы с ним справляемся и что он означает для эпидемиологии.
Прежде всего, случайная ошибка не . Систематическая ошибка — это систематическая ошибка, которая более подробно рассматривается в главе 6.
Случайная ошибка — это то, на что это похоже: случайные ошибки в данных. Все данные содержат случайные ошибки, потому что ни одна система измерения не идеальна. Величина случайных ошибок частично зависит от масштаба, в котором что-то измеряется (ошибки в измерениях на молекулярном уровне будут порядка нанометров, тогда как ошибки в измерении человеческого роста, вероятно, составляют порядка сантиметра или двух), а частично от масштаба. качество используемых инструментов. В лабораториях физики и химии есть очень точные и дорогие весы, которые могут измерять массу с точностью до грамма, микрограмма или нанограмма, тогда как средние весы в чьей-то ванной, вероятно, имеют точность в пределах полфунта или фунта.
Все данные содержат случайные ошибки, потому что ни одна система измерения не идеальна. Величина случайных ошибок частично зависит от масштаба, в котором что-то измеряется (ошибки в измерениях на молекулярном уровне будут порядка нанометров, тогда как ошибки в измерении человеческого роста, вероятно, составляют порядка сантиметра или двух), а частично от масштаба. качество используемых инструментов. В лабораториях физики и химии есть очень точные и дорогие весы, которые могут измерять массу с точностью до грамма, микрограмма или нанограмма, тогда как средние весы в чьей-то ванной, вероятно, имеют точность в пределах полфунта или фунта.
Чтобы понять случайную ошибку, представьте, что вы печете торт, для которого требуется 6 столовых ложек масла. Чтобы получить 6 ст. выстроены правильно. Или, возможно, вы могли бы последовать методу моей матери, который заключается в том, чтобы развернуть палку, сделать небольшую отметку на том, что похоже на половину палки, а затем перейти к трем четвертям, взглянув на половину половины. Или вы можете использовать мой метод, который состоит в том, чтобы с самого начала определить на глаз три четверти и отрезать. Любой из этих методов «измерения» даст вам примерно 6 столовых ложек масла, чего, безусловно, достаточно для выпечки торта, но, вероятно, не точно 3 унции, а именно столько весят 6 столовых ложек масла в США. . [i] То, что в этот раз вы чуть больше 3 унций и, возможно, чуть меньше 3 унций в следующий раз, вызывает случайную ошибку в вашем измерении масла. Если бы вы всегда недооценивали или всегда переоценивали, то это было бы предвзятостью, однако ваши последовательно недооцененные или переоцененные измерения содержали бы в себе случайную ошибку.
Или вы можете использовать мой метод, который состоит в том, чтобы с самого начала определить на глаз три четверти и отрезать. Любой из этих методов «измерения» даст вам примерно 6 столовых ложек масла, чего, безусловно, достаточно для выпечки торта, но, вероятно, не точно 3 унции, а именно столько весят 6 столовых ложек масла в США. . [i] То, что в этот раз вы чуть больше 3 унций и, возможно, чуть меньше 3 унций в следующий раз, вызывает случайную ошибку в вашем измерении масла. Если бы вы всегда недооценивали или всегда переоценивали, то это было бы предвзятостью, однако ваши последовательно недооцененные или переоцененные измерения содержали бы в себе случайную ошибку.
Для любой заданной переменной, которую мы можем захотеть измерить в эпидемиологии (например, рост, средний балл, частота сердечных сокращений, количество лет работы на конкретном заводе, уровень триглицеридов в сыворотке и т. д.), мы ожидаем, что в выборке будет вариабельность— то есть мы не ожидаем, что все в популяции будут иметь точно такое же значение. Это не случайная ошибка. Случайная ошибка (и предвзятость) возникает, когда мы пытаемся измерить эти вещи. Действительно, эпидемиология как наука опирается на эту присущую ей изменчивость. Если бы все были одинаковыми, мы бы не смогли определить, какие люди подвержены более высокому риску развития того или иного заболевания.
Это не случайная ошибка. Случайная ошибка (и предвзятость) возникает, когда мы пытаемся измерить эти вещи. Действительно, эпидемиология как наука опирается на эту присущую ей изменчивость. Если бы все были одинаковыми, мы бы не смогли определить, какие люди подвержены более высокому риску развития того или иного заболевания.
В эпидемиологии иногда наши измерения основаны на человеке, отличном от участника исследования, который измеряет что-то на участнике или о нем. Примеры могут включать измеренный рост или вес, артериальное давление или уровень холестерина в сыворотке. Для некоторых из них (например, веса и холестерина в сыворотке) в данные вкрадывается случайная ошибка из-за используемого прибора — в данном случае весов, которые, вероятно, имеют колебания в полфунта, или лабораторного анализа с погрешностью несколько миллиграммов на децилитр. Для других измерений (например, роста и кровяного давления) за любую случайную ошибку несет ответственность сам измеряющий, как в примере со сливочным маслом.
Однако многие из наших измерений основаны на самоотчетах участников. Существуют целые учебники и курсы, посвященные разработке анкет, и наука о том, как получить наиболее точные данные от людей с помощью методов опроса, довольно хороша. Исследовательский центр Pew предлагает на своем веб-сайте хороший вводный курс по дизайну анкет.
В связи с нашим обсуждением здесь случайная ошибка появится и в данных анкеты. Для некоторых переменных будет меньше случайных ошибок, чем для других (например, расовая принадлежность, о которой сообщают сами, вероятно, достаточно точна), но некоторые все же будут — например, люди, случайно поставившие галочку не в том поле. Для других переменных будет больше случайных ошибок (например, неточные ответы на такие вопросы, как «Сколько раз в месяц в прошлом году вы ели рис?»). Хороший вопрос, который следует задать себе при рассмотрении количества случайных ошибок, которые могут быть в переменной, полученной из вопросника, звучит так: « Могут ли человек сказать мне это?» Большинство людей теоретически могут сказать вам, сколько они спали прошлой ночью, но им будет трудно сказать вам, сколько они спали той же ночью год назад. Скажут ли они вам или нет — это другой вопрос, который касается предвзятости (см. главу 6). Несмотря на это, случайная ошибка в данных анкеты увеличивается по мере того, как уменьшается вероятность того, что люди смогут дать вам ответ.
Скажут ли они вам или нет — это другой вопрос, который касается предвзятости (см. главу 6). Несмотря на это, случайная ошибка в данных анкеты увеличивается по мере того, как уменьшается вероятность того, что люди смогут дать вам ответ.
Хотя мы можем и должны работать над тем, чтобы свести к минимуму случайную ошибку (используя высококачественные инструменты, обучая персонал тому, как проводить измерения, разрабатывая качественные вопросники и т. д.), полностью устранить ее невозможно. К счастью, мы можем использовать статистику для количественной оценки случайных ошибок, присутствующих в исследовании. Собственно, для этого и нужна статистика. В этой книге я расскажу лишь о небольшой части обширной области статистики: интерпретация и . Вместо того, чтобы сосредоточиться на том, как их вычислить [1] , я вместо этого сосредоточусь на том, что они означают (и что они не означают). Знание p-значений и доверительных интервалов достаточно для точной интерпретации результатов эпидемиологических исследований для начинающих студентов-эпидемиологов.
p
-значенияПри проведении научных исследований любого рода, в том числе эпидемиологических, начинают с гипотезы, которая затем проверяется по мере проведения исследования. Например, если мы изучаем средний рост студентов бакалавриата, наша гипотеза (обычно обозначаемая цифрой H 1 ) может заключаться в том, что учащиеся мужского пола в среднем выше, чем учащиеся женского пола. Однако для целей статистической проверки мы должны перефразировать нашу гипотезу как [2] . В этом случае наша нулевая гипотеза (обычно обозначаемая как H 0 ) будет следующей:
H 0 : Между студентами бакалавриата мужского и женского пола нет разницы в среднем росте.
Затем мы предпримем наше исследование, чтобы проверить эту гипотезу. Сначала мы определяем целевую группу (студенты бакалавриата) и берем из нее выборку. Затем мы измеряем рост и пол всех участников выборки и вычисляем средний рост мужчин и женщин. Затем мы проведем статистический тест, чтобы сравнить средний рост в двух группах. Поскольку у нас есть непрерывная переменная (рост), измеренная в 2 группах (мужчины и женщины), мы будем использовать [3] , а t -статистика, рассчитанная с помощью этого теста, будет иметь соответствующее значение p , что нас действительно волнует.
Затем мы проведем статистический тест, чтобы сравнить средний рост в двух группах. Поскольку у нас есть непрерывная переменная (рост), измеренная в 2 группах (мужчины и женщины), мы будем использовать [3] , а t -статистика, рассчитанная с помощью этого теста, будет иметь соответствующее значение p , что нас действительно волнует.
A p -значение — это вероятность того, что если вы повторите исследование, вы получите результат, по крайней мере, столь же экстремальный, при условии, что нулевая гипотеза верна.
Допустим, в нашем исследовании мы обнаружили, что средний рост студентов мужского пола составляет 5 футов 10 дюймов, а среди студенток средний рост составляет 5 футов 6 дюймов (при разнице в 4 дюйма), и мы вычисляем p — значение 0,04. Это означает, что если действительно нет разницы в среднем росте между учащимися мужского и женского пола (т. е. если нулевая гипотеза верна) и мы повторяем исследование (вплоть до составления новой выборки из населения), то существует 4% вероятность того, что мы снова обнаружим разницу в среднем росте в 4 дюйма и более .
Есть несколько следствий, вытекающих из вышеприведенного абзаца. Во-первых, в эпидемиологии мы всегда вычисляем двусторонние p -значения. Здесь это просто означает, что 4%-ная вероятность разницы в росте ≥4 дюймов ничего не говорит о том, какая группа выше — просто одна группа (мужчины или женщины) будет выше в среднем как минимум на 4 дюйма. Во-вторых, p-значения бессмысленны, если вам удастся включить в свое исследование все население. В качестве примера предположим, что наш исследовательский вопрос касается студентов факультета общественного здравоохранения 425 (h525, основы эпидемиологии) во время зимнего семестра 2020 года в Университете штата Орегон (OSU). Мужчины или женщины выше в этой популяции? Поскольку население довольно мало, и всех участников легко идентифицировать, мы можем зарегистрировать всех, а не полагаться на выборку. В измерении роста по-прежнему будет случайная ошибка, но мы больше не используем p — значение для его количественной оценки. Это потому, что если бы мы повторили исследование, мы бы нашли точно такое же, поскольку мы фактически измерили всех в популяции. P — значения применяются только в том случае, если мы работаем с образцами.
Это потому, что если бы мы повторили исследование, мы бы нашли точно такое же, поскольку мы фактически измерили всех в популяции. P — значения применяются только в том случае, если мы работаем с образцами.
Наконец, обратите внимание, что p -значение описывает вероятность ваших данных, предполагая, что нулевая гипотеза верна, но не описывает вероятность того, что нулевая гипотеза верна, учитывая ваши данные. Это распространенная ошибка интерпретации, которую допускают как начинающие, так и опытные читатели эпидемиологических исследований. p -value ничего не говорит о том, насколько вероятно, что нулевая гипотеза верна (и, таким образом, с другой стороны, об истинности вашей действительной гипотезы). Скорее, он количественно определяет вероятность получения данных, которые вы получили, если нулевая гипотеза действительно оказалась верной. Это тонкое различие, но очень важное.
Статистическая значимость Что будет дальше? У нас есть значение p , которое говорит нам о вероятности получения наших данных с учетом нулевой гипотезы. Но что это на самом деле означает с точки зрения выводов о результатах исследования? В общественном здравоохранении и клинических исследованиях стандартной практикой является использование p ≤ 0,05 для обозначения . Другими словами, десятилетиями исследователи в этой области коллективно решили, что если вероятность совершения (подробнее об этом ниже) составляет 5% или меньше, мы «отвергаем нулевую гипотезу». Продолжая приведенный выше пример роста, мы, таким образом, пришли бы к выводу, что существует разница в росте между полами, по крайней мере, среди студентов бакалавриата. Для p — значений выше 0,05 мы «не можем отвергнуть нулевую гипотезу» и вместо этого заключаем, что наши данные не предоставили доказательств того, что между студентами бакалавриата и студентками существовала разница в росте.
Но что это на самом деле означает с точки зрения выводов о результатах исследования? В общественном здравоохранении и клинических исследованиях стандартной практикой является использование p ≤ 0,05 для обозначения . Другими словами, десятилетиями исследователи в этой области коллективно решили, что если вероятность совершения (подробнее об этом ниже) составляет 5% или меньше, мы «отвергаем нулевую гипотезу». Продолжая приведенный выше пример роста, мы, таким образом, пришли бы к выводу, что существует разница в росте между полами, по крайней мере, среди студентов бакалавриата. Для p — значений выше 0,05 мы «не можем отвергнуть нулевую гипотезу» и вместо этого заключаем, что наши данные не предоставили доказательств того, что между студентами бакалавриата и студентками существовала разница в росте.
Если p > 0,05, мы не можем отвергнуть нулевую гипотезу. Мы никогда не принимаем нулевую гипотезу, потому что очень трудно доказать отсутствие чего-либо. «Принятие» нулевой гипотезы означает, что мы доказали, что на самом деле нет разницы в росте между учащимися мужского и женского пола, чего на самом деле не было. Если p > 0,05, это просто означает, что мы не нашли свидетельств, противоречащих нулевой гипотезе — , а не , что указанное свидетельство не существует. Мы могли получить странную выборку, у нас могла быть слишком маленькая выборка и т. д. Существует целая область клинических исследований (сравнительные исследования эффективности 9).0033 vi ), предназначенный для демонстрации того, что одно лечение не лучше и не хуже другого; применяемые в этой области методы сложны, а требуемые размеры выборки довольно велики. В большинстве эпидемиологических исследований мы просто придерживаемся отказа от отказа.
«Принятие» нулевой гипотезы означает, что мы доказали, что на самом деле нет разницы в росте между учащимися мужского и женского пола, чего на самом деле не было. Если p > 0,05, это просто означает, что мы не нашли свидетельств, противоречащих нулевой гипотезе — , а не , что указанное свидетельство не существует. Мы могли получить странную выборку, у нас могла быть слишком маленькая выборка и т. д. Существует целая область клинических исследований (сравнительные исследования эффективности 9).0033 vi ), предназначенный для демонстрации того, что одно лечение не лучше и не хуже другого; применяемые в этой области методы сложны, а требуемые размеры выборки довольно велики. В большинстве эпидемиологических исследований мы просто придерживаемся отказа от отказа.
Является ли пороговое значение p ≤ 0,05 произвольным? Абсолютно. Это стоит иметь в виду, особенно для значений p , очень близких к этой границе. Действительно ли 0,49 так сильно отличается от 0,51? Скорее всего нет, но они находятся по разные стороны от этой произвольной линии. Размер p -значение зависит от 3 вещей: размера выборки, размера эффекта (нуль-гипотезу легче отвергнуть, если истинная разница в росте — если бы мы измеряли всех в популяции, а не только нашу выборку — равна 6 дюймы, а не 2 дюйма), и согласованность данных, чаще всего измеряемую стандартными отклонениями от среднего роста в 2 группах. Таким образом, p -значение 0,51 почти наверняка может быть уменьшено путем простого включения большего числа людей в исследование (это относится к , который является обратным , обсуждаемому ниже). Важно иметь в виду этот факт, когда вы читаете исследования.
Размер p -значение зависит от 3 вещей: размера выборки, размера эффекта (нуль-гипотезу легче отвергнуть, если истинная разница в росте — если бы мы измеряли всех в популяции, а не только нашу выборку — равна 6 дюймы, а не 2 дюйма), и согласованность данных, чаще всего измеряемую стандартными отклонениями от среднего роста в 2 группах. Таким образом, p -значение 0,51 почти наверняка может быть уменьшено путем простого включения большего числа людей в исследование (это относится к , который является обратным , обсуждаемому ниже). Важно иметь в виду этот факт, когда вы читаете исследования.
Проверка статистической значимости является частью раздела статистики, именуемого частотной статистикой . ii Хотя эта практика чрезвычайно распространена в эпидемиологии и смежных областях, она не считается идеальной наукой по ряду причин. Прежде всего, пороговое значение 0,05 является совершенно произвольным, iii , и строгая проверка значимости отклонит нулевое значение для p = 0,049.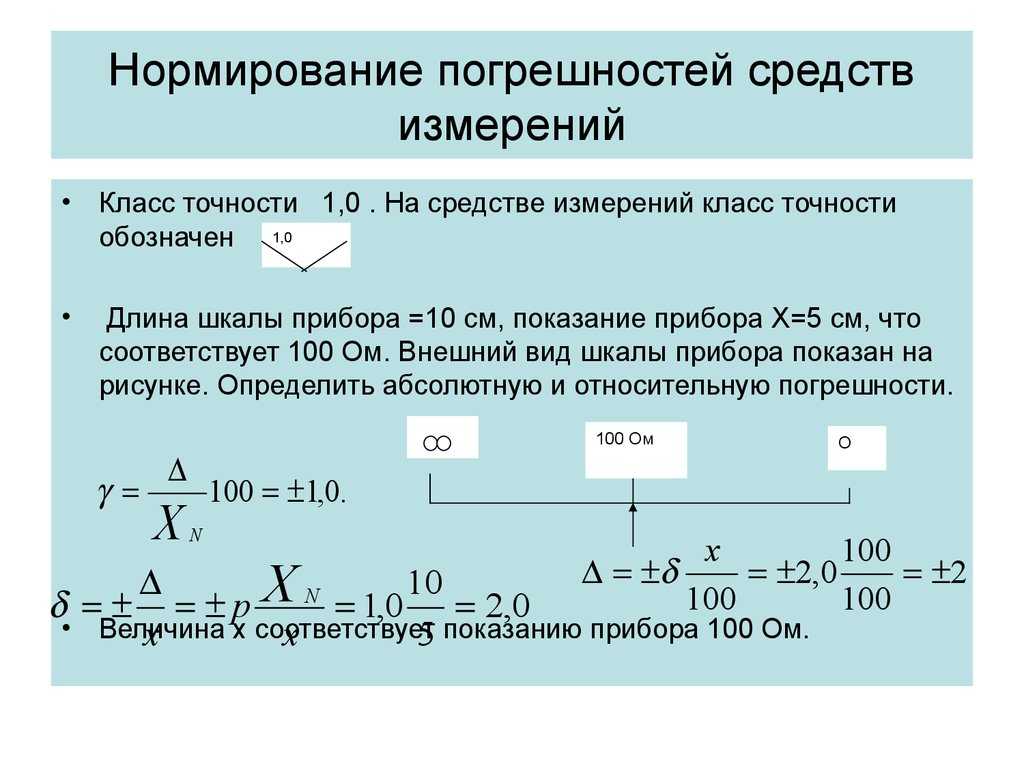 но не могут отклонить для p = 0,051, хотя они почти идентичны. Во-вторых, существует гораздо больше нюансов интерпретации p значений и доверительных интервалов, чем те, которые я рассмотрел в этой главе. iv Например, значение p на самом деле проверяет все допущения анализа, а не только нулевую гипотезу, а большое значение p часто просто указывает на то, что данные не могут различать многочисленные конкурирующие гипотезы. Однако, поскольку как общественное здравоохранение, так и клиническая медицина требуют принятия решений «да» или «нет» (должны ли мы тратить ресурсы на эту кампанию по санитарному просвещению? должен ли этот пациент получать это лекарство?), должно быть какая-то система для принятия решения «да» или «нет», и в настоящее время ею является проверка статистической значимости. Существуют и другие способы количественной оценки случайной ошибки, и действительно байесовская статистика (которая вместо ответа «да» или «нет» дает вероятность того, что что-то произойдет) ii становится все более и более популярной.
но не могут отклонить для p = 0,051, хотя они почти идентичны. Во-вторых, существует гораздо больше нюансов интерпретации p значений и доверительных интервалов, чем те, которые я рассмотрел в этой главе. iv Например, значение p на самом деле проверяет все допущения анализа, а не только нулевую гипотезу, а большое значение p часто просто указывает на то, что данные не могут различать многочисленные конкурирующие гипотезы. Однако, поскольку как общественное здравоохранение, так и клиническая медицина требуют принятия решений «да» или «нет» (должны ли мы тратить ресурсы на эту кампанию по санитарному просвещению? должен ли этот пациент получать это лекарство?), должно быть какая-то система для принятия решения «да» или «нет», и в настоящее время ею является проверка статистической значимости. Существуют и другие способы количественной оценки случайной ошибки, и действительно байесовская статистика (которая вместо ответа «да» или «нет» дает вероятность того, что что-то произойдет) ii становится все более и более популярной. Тем не менее, поскольку частотная статистика и проверка нулевой гипотезы по-прежнему являются наиболее распространенными методами, используемыми в эпидемиологической литературе, именно им посвящена эта глава.
Тем не менее, поскольку частотная статистика и проверка нулевой гипотезы по-прежнему являются наиболее распространенными методами, используемыми в эпидемиологической литературе, именно им посвящена эта глава.
Ошибка первого рода (обычно обозначаемая α, греческой буквой альфа и тесно связанная с p -значениями) — это вероятность того, что вы ошибочно отклоните нулевую гипотезу, другими словами, что вы «найдёте» что-то, что не совсем там. Выбрав 0,05 в качестве нашего порога статистической значимости, мы в области общественного здравоохранения и клинических исследований молчаливо согласились с тем, что мы готовы признать, что 5% наших результатов действительно будут ошибками первого рода, или ложных срабатываний .
Ошибка типа II (обычно обозначаемая буквой β, греческой буквой бета ) противоположна: β — это вероятность того, что вы ошибочно не отвергнете нулевую гипотезу — другими словами, вы упустите что-то, что действительно существует.
Мощность = 1 – β и интерпретируется как вероятность того, что вы найдете вещи, если они есть.
Мощность в эпидемиологических исследованиях варьируется в широких пределах: в идеале она должна составлять не менее 90% (что означает, что частота ошибок типа II составляет 10%), но часто она намного ниже. Мощность пропорциональна размеру выборки, но экспоненциально — мощность возрастает с увеличением размера выборки, но чтобы получить от 9Для мощности от 0 до 95% требуется гораздо больший скачок в размере выборки, чем для перехода от мощности от 40 до 45%. Если исследование не может опровергнуть нулевую гипотезу, но данные выглядят так, как будто между группами может быть большая разница, часто проблема заключается в том, что исследование было недостаточно мощным, и с большей выборкой значение p , вероятно, упадет ниже волшебное отсечение 0,05. С другой стороны, часть проблемы с небольшими выборками заключается в том, что вы могли просто случайно получить нерепрезентативную выборку, и добавление дополнительных участников могло бы , а не приближают результаты к статистической значимости. В качестве примера предположим, что нас снова интересуют различия в росте по половому признаку, но на этот раз только среди спортсменов из университетских команд. Мы начинаем с очень небольшого исследования — всего одна мужская команда и одна женская команда. Если нам случится выбрать, скажем, мужскую баскетбольную команду и женскую команду по гимнастике, мы, скорее всего, обнаружим колоссальную разницу в среднем росте — возможно, 18 дюймов или больше. Добавление других команд к нашему исследованию почти наверняка приведет к гораздо более узкой разнице в среднем росте, а разница в 18 дюймов, «обнаруженная» в нашем первоначальном небольшом исследовании, не будет сохраняться со временем.
В качестве примера предположим, что нас снова интересуют различия в росте по половому признаку, но на этот раз только среди спортсменов из университетских команд. Мы начинаем с очень небольшого исследования — всего одна мужская команда и одна женская команда. Если нам случится выбрать, скажем, мужскую баскетбольную команду и женскую команду по гимнастике, мы, скорее всего, обнаружим колоссальную разницу в среднем росте — возможно, 18 дюймов или больше. Добавление других команд к нашему исследованию почти наверняка приведет к гораздо более узкой разнице в среднем росте, а разница в 18 дюймов, «обнаруженная» в нашем первоначальном небольшом исследовании, не будет сохраняться со временем.
Поскольку мы установили приемлемый уровень [латекс]\альфа[/латекс] на уровне 5%, в эпидемиологии и смежных областях мы чаще всего используем 95% доверительные интервалы (95% ДИ). Можно использовать 95% ДИ для проверки значимости: если 95% ДИ не включает нулевое значение (0 для разницы рисков и 1,0 для отношений шансов, отношений рисков и отношений скоростей), тогда p < 0,05, и результат составляет статистически значимых .
Хотя 95% ДИ можно использовать для тестирования значимости, они содержат гораздо больше информации, чем просто значение p <0,05 или нет. Большинство эпидемиологических исследований сообщают о 95% ДИ вокруг любых представленных . Правильная интерпретация 95% ДИ выглядит следующим образом:
Если вы повторите исследование 100 раз (назад к выборке из населения) и исследование будет свободным от какой-либо систематической ошибки, то 95 из этих 100 раз рассчитанный вами доверительный интервал будет включать «реальный» ответ, который вы получите. Вы смогли зарегистрировать всех в населении.
Мы также можем проиллюстрировать это визуально:
Рисунок 5-1Источник: https://es.wikipedia.org/wiki/Intervalo_de_confianza
На рисунке 5-1 параметр совокупности μ представляет собой «реальный» ответ, который вы получили бы, если бы вы могли включить в исследование абсолютно всех представителей совокупности. Мы оцениваем μ с данными из нашей выборки. Продолжая наш пример с ростом, это может быть 5 дюймов: если бы мы могли волшебным образом измерить рост каждого студента бакалавриата в США (или в мире, в зависимости от того, как вы определили свою целевую группу), средняя разница между студентами мужского и женского пола будет 5 дюймов. Важно отметить, что этот параметр населения почти всегда не поддается наблюдению — он становится наблюдаемым только в том случае, если вы определяете свое население достаточно узко, чтобы вы могли зарегистрировать всех. Каждая синяя вертикальная линия представляет собой КИ отдельного «исследования» — в данном случае их 50. Доверительные интервалы различаются, потому что выборка каждый раз немного отличается, однако большинство доверительных интервалов (фактически все, кроме трех) содержат μ.
Мы оцениваем μ с данными из нашей выборки. Продолжая наш пример с ростом, это может быть 5 дюймов: если бы мы могли волшебным образом измерить рост каждого студента бакалавриата в США (или в мире, в зависимости от того, как вы определили свою целевую группу), средняя разница между студентами мужского и женского пола будет 5 дюймов. Важно отметить, что этот параметр населения почти всегда не поддается наблюдению — он становится наблюдаемым только в том случае, если вы определяете свое население достаточно узко, чтобы вы могли зарегистрировать всех. Каждая синяя вертикальная линия представляет собой КИ отдельного «исследования» — в данном случае их 50. Доверительные интервалы различаются, потому что выборка каждый раз немного отличается, однако большинство доверительных интервалов (фактически все, кроме трех) содержат μ.
Если мы проведем наше исследование и обнаружим среднюю разницу в 4 дюйма (95% ДИ, 1,5–7), ДИ скажет нам 2 вещи. Во-первых, значение p для нашего t -теста будет <0,05, поскольку ДИ исключает 0 (в данном случае нулевое значение, поскольку мы вычисляем меру различия). Во-вторых, интерпретация ДИ такова: если мы повторим наше исследование (включая взятие нового образца) 100 раз, то 95 из этих раз наш ДИ будет включать реальное значение (которое, как мы знаем здесь, составляет 5 дюймов, но которое в реальной жизни вы бы не знали). Таким образом, глядя на CI здесь от 1,5 до 7,0 дюймов, можно понять, в чем может заключаться реальная разница — она почти наверняка находится где-то в этом диапазоне, но может быть от 1,5 до 7 дюймов. Нравится p -значения, ДИ зависят от размера выборки. Большая выборка даст сравнительно более узкий ДИ. Считается, что более узкие доверительные интервалы лучше, потому что они дают более точную оценку того, каким может быть «истинный» ответ.
Во-вторых, интерпретация ДИ такова: если мы повторим наше исследование (включая взятие нового образца) 100 раз, то 95 из этих раз наш ДИ будет включать реальное значение (которое, как мы знаем здесь, составляет 5 дюймов, но которое в реальной жизни вы бы не знали). Таким образом, глядя на CI здесь от 1,5 до 7,0 дюймов, можно понять, в чем может заключаться реальная разница — она почти наверняка находится где-то в этом диапазоне, но может быть от 1,5 до 7 дюймов. Нравится p -значения, ДИ зависят от размера выборки. Большая выборка даст сравнительно более узкий ДИ. Считается, что более узкие доверительные интервалы лучше, потому что они дают более точную оценку того, каким может быть «истинный» ответ.
Случайная ошибка присутствует во всех измерениях, хотя некоторые переменные более подвержены ей, чем другие. P -значения и ДИ используются для количественной оценки случайной ошибки. Значение p , равное 0,05 или меньше, обычно считается «статистически значимым», и соответствующий доверительный интервал исключает нулевое значение. ДИ полезны для выражения потенциального диапазона оцениваемого «реального» значения на уровне популяции.
ДИ полезны для выражения потенциального диапазона оцениваемого «реального» значения на уровне популяции.
я. Масло в США и остальном мире. Кухня Эрренс . Март 2014 г. https://www.errenskitchen.com/cooking-conversions/butter-measurement-weight-conversions/. По состоянию на 26 сентября 2018 г. (↵ Возврат)
ii. Байесовский и частотный подход: одни и те же данные, противоположные результаты. 365 Data Sci . Август 2017 г. https://365datascience.com/bayesian-vs-frequentist-approach/. По состоянию на 17 октября 2018 г. (↵ Возврат 1) (↵ Возврат 2)
iii. Смит Р.Дж. Продолжающееся неправильное использование проверки значимости нулевой гипотезы в биологической антропологии. Am J Phys Anthropol . 2018;166(1):236-245. doi:10.1002/ajpa.23399 (↵ Возврат)
iv. Фарланд Л.В., Коррейя К.Ф., Уайз Л.А., Уильямс П.Л., Гинзбург Э.С., Миссмер С.А. P-значения и репродуктивное здоровье: чему клинические исследователи могут научиться у Американской статистической ассоциации? Hum Reprod Oxf Engl . 2016;31(11):2406-2410. doi:10.1093/humrep/dew192 (↵ Return)
2016;31(11):2406-2410. doi:10.1093/humrep/dew192 (↵ Return)
v. Greenland S, Senn SJ, Rothman KJ, et al. Статистические тесты, значения p, доверительные интервалы и мощность: руководство по неверным толкованиям. Евро J Эпидемиол . 2016;31:337-350. doi:10.1007/s10654-016-0149-3
vi. Почему важны исследования сравнительной эффективности? Исследовательский институт результатов, ориентированных на пациента. https://www.pcori.org/files/why-comparative-efficientness-research-important. По состоянию на 17 октября 2018 г. (↵ Возврат)
- Существует не одна формула для расчета p -value или CI. Скорее, формулы меняются в зависимости от того, какой статистический тест применяется. Любой вводный текст по биостатистике, в котором обсуждается, какие статистические методы следует использовать и когда, также содержит соответствующую информацию о p — вычисление значения и CI. ↵
- Не тратьте слишком много времени на то, чтобы понять, зачем нужна нулевая гипотеза; мы просто делаем.
 Обоснование погребено в веках аргументов академической философии науки. ↵
Обоснование погребено в веках аргументов академической философии науки. ↵ - Как выбрать правильный тест выходит за рамки этой книги — см. любую книгу по вводной биостатистике ↵
случайных и систематических ошибок | Определение и примеры
Опубликован в 7 мая 2021 г. к Прита Бхандари. Отредактировано 13 февраля 2023 г.
В научных исследованиях ошибка измерения — это разница между наблюдаемым значением и истинным значением чего-либо. Ее также называют ошибкой наблюдения или экспериментальной ошибкой.
Существует два основных типа ошибок измерения:
- Случайная ошибка — это случайная разница между наблюдаемыми и истинными значениями чего-либо (например, исследователь, неправильно взвешивающий весы, записывает неверное измерение).
- Систематическая ошибка — это постоянная или пропорциональная разница между наблюдаемыми и истинными значениями чего-либо (например, неправильно откалиброванные весы постоянно регистрируют веса как более высокие, чем они есть на самом деле).

Распознавая источники ошибок, вы можете уменьшить их влияние и записывать точные и точные измерения. Оставленные незамеченными, эти ошибки могут привести к предвзятости исследования, такой как предвзятость из-за пропущенных переменных или информационная предвзятость.
Содержание
- Случайные или систематические ошибки хуже?
- Случайная ошибка
- Уменьшение случайной ошибки
- Систематическая ошибка
- Уменьшение систематической ошибки
- Часто задаваемые вопросы о случайной и систематической ошибке
Случайные или систематические ошибки хуже?
В исследованиях систематические ошибки обычно представляют большую проблему, чем случайные ошибки.
Случайная ошибка — это не обязательно ошибка, а скорее естественная часть измерения. В измерениях всегда есть некоторая изменчивость, даже если вы неоднократно измеряете одно и то же, из-за колебаний окружающей среды, инструмента или ваших собственных интерпретаций.
Но изменчивость может быть проблемой, когда она влияет на вашу способность делать правильные выводы о взаимосвязях между переменными. Чаще всего это происходит из-за систематической ошибки.
Точность против точности
Случайная ошибка в основном влияет на точность , то есть на то, насколько воспроизводимо одно и то же измерение в эквивалентных условиях. Напротив, систематическая ошибка влияет на точность измерения или на то, насколько близко наблюдаемое значение к истинному значению.
Проведение измерений похоже на попадание в центральную мишень на мишени для дротиков. Для точных измерений вы должны максимально приблизить свой дротик (ваши наблюдения) к цели (истинным значениям). Для точных измерений вы стремитесь получить повторные наблюдения как можно ближе друг к другу.
Случайная ошибка приводит к вариации между различными измерениями одного и того же объекта, в то время как систематическая ошибка отклоняет ваше измерение от истинного значения в определенном направлении.
Когда у вас есть только случайная ошибка, если вы измеряете одно и то же несколько раз, ваши измерения будут иметь тенденцию группироваться или варьироваться вокруг истинного значения. Некоторые значения будут выше, чем истинный балл, а другие будут ниже. Когда вы усредните эти измерения, вы будете очень близки к истинному результату.
По этой причине случайная ошибка не считается большой проблемой при сборе данных из большой выборки — ошибки в разных направлениях будут компенсировать друг друга при расчете описательной статистики. Но это может повлиять на точность вашего набора данных, если у вас небольшая выборка.
Систематические ошибки представляют гораздо большую проблему, чем случайные ошибки, поскольку они могут исказить ваши данные, что приведет к ложным выводам. Если у вас есть систематическая ошибка, ваши измерения будут отклонены от истинных значений. В конечном итоге вы можете сделать ложноположительный или ложноотрицательный вывод (ошибка типа I или II) о связи между изучаемыми переменными.
Случайная ошибка
Случайная ошибка влияет на ваши измерения непредсказуемым образом: ваши измерения с одинаковой вероятностью могут быть выше или ниже истинных значений.
На приведенном ниже графике черная линия представляет собой идеальное совпадение между истинными и наблюдаемыми оценками по шкале. В идеальном мире все ваши данные попадут именно на эту линию. Зеленые точки представляют фактические наблюдаемые оценки для каждого измерения с добавлением случайной ошибки.
Случайная ошибка называется «шумом», поскольку она искажает истинное значение (или «сигнал») измеряемого объекта. Сохранение случайной ошибки на низком уровне помогает собирать точные данные.
Источники случайных ошибок
Некоторые распространенные источники случайных ошибок включают:
- естественных вариаций в реальном мире или в экспериментальных условиях.
- неточные или ненадежные измерительные приборы.

- индивидуальных различий между участниками или подразделениями.
- плохо контролируемых экспериментальных процедур.
| Источник случайной ошибки | Пример |
|---|---|
| Естественные вариации в контексте | В ходе эксперимента по объему памяти участники проходят тесты на память в разное время суток. Тем не менее, некоторые участники, как правило, работают лучше утром, а другие лучше в конце дня, поэтому ваши измерения не отражают истинный объем памяти каждого человека. |
| Неточный инструмент | Вы измеряете окружность запястья с помощью рулетки. Но ваша рулетка точна только до ближайшего полусантиметра, поэтому при записи данных вы округляете каждое измерение в большую или меньшую сторону. |
| Индивидуальные различия | Вы просите участников нанести себе безопасный удар электрическим током и оценить уровень боли по 7-балльной шкале. Поскольку боль субъективна, ее трудно надежно измерить. Некоторые участники завышают уровень своей боли, в то время как другие преуменьшают уровень своей боли. Поскольку боль субъективна, ее трудно надежно измерить. Некоторые участники завышают уровень своей боли, в то время как другие преуменьшают уровень своей боли. |
Уменьшение случайной ошибки
Случайная ошибка почти всегда присутствует в исследованиях, даже в строго контролируемых условиях. Хотя вы не можете полностью избавиться от нее, вы можете уменьшить случайную ошибку, используя следующие методы.
Провести повторные измерения
Простой способ повысить точность — провести повторные измерения и использовать их среднее значение. Например, вы можете измерить окружность запястья участника три раза и каждый раз получать несколько разные значения. Взяв среднее значение трех измерений вместо одного, вы намного приблизитесь к истинному значению.
Увеличьте размер выборки
Большие выборки имеют меньшую случайную ошибку, чем маленькие выборки. Это потому, что ошибки в разных направлениях компенсируют друг друга более эффективно, когда у вас больше точек данных. Сбор данных из большой выборки повышает точность и статистическую мощность.
Сбор данных из большой выборки повышает точность и статистическую мощность.
Переменные управления
В контролируемых экспериментах вы должны тщательно контролировать любые посторонние переменные, которые могут повлиять на ваши измерения. Их следует контролировать для всех участников, чтобы исключить ключевые источники случайных ошибок по всем направлениям.
Систематическая ошибка
Систематическая ошибка означает, что ваши измерения одного и того же объекта будут различаться предсказуемым образом: каждое измерение будет отличаться от истинного измерения в одном и том же направлении, а в некоторых случаях даже на одну и ту же величину.
Систематическая ошибка также называется предвзятостью, поскольку ваши данные искажены стандартизированными способами, которые скрывают истинные значения. Это может привести к неверным выводам.
Типы систематических ошибок
Ошибки смещения и ошибки коэффициента масштабирования — это два поддающихся количественной оценке типа систематических ошибок.
Ошибка смещения возникает, когда весы не откалиброваны на правильную нулевую точку. Ее также называют аддитивной ошибкой или ошибкой установки нуля.
Пример: ошибка смещения. При измерении окружности запястий участников вы неправильно поняли цифру «2» на рулетке как нулевую точку. Ко всем вашим измерениям добавлены дополнительные 2 сантиметра.Ошибка масштабного коэффициента возникает, когда измерения постоянно и пропорционально отличаются от истинного значения (например, на 10%). Ее также называют корреляционной систематической ошибкой или ошибкой множителя.
Пример: Ошибка коэффициента масштабирования Весы последовательно добавляют 10% к каждому весу. Истинный вес 10 кг записывается как 11 кг, а истинный вес 40 кг записывается как 44 кг. Вы можете отобразить ошибки смещения и ошибки коэффициента масштабирования на графиках, чтобы определить их различия. На приведенных ниже графиках черная линия показывает, когда наблюдаемое значение является точным истинным значением и нет случайной ошибки.
Синяя линия — это ошибка смещения: она сдвигает все ваши наблюдаемые значения вверх или вниз на фиксированную величину (здесь это одна дополнительная единица).
Фиолетовая линия — это ошибка коэффициента масштабирования: все ваши наблюдаемые значения умножаются на коэффициент — все значения сдвигаются в одном направлении на одинаковую пропорцию, но на разные абсолютные величины.
Источники систематических ошибок
Источники систематических ошибок могут варьироваться от ваших исследовательских материалов до ваших процедур сбора данных и ваших методов анализа. Это не исчерпывающий список источников систематических ошибок, потому что они могут возникать во всех аспектах исследования.
Предвзятость ответов возникает, когда материалы вашего исследования (например, анкеты) побуждают участников отвечать или действовать недостоверно посредством наводящих вопросов . Например, предвзятость социальной желательности может привести к тому, что участники попытаются соответствовать общественным нормам, даже если они на самом деле не так себя чувствуют.
В вашем вопросе говорится: «Эксперты считают, что только систематические действия могут уменьшить последствия изменения климата. Вы согласны с тем, что отдельные действия бессмысленны?»
Ссылаясь на «мнения экспертов», этот тип загруженного вопроса сигнализирует участникам, что они должны согласиться с мнением или рискнуть показаться неосведомленными. Участники могут неохотно ответить, что они согласны с утверждением, даже если они этого не делают.
Дрейф экспериментатора возникает, когда наблюдатели устают, скучают или теряют мотивацию после длительных периодов сбора или кодирования данных и постепенно отходят от использования стандартных процедур определенным образом.
Пример: дрейф экспериментатора (наблюдателя). Вы качественно кодируете видео из социальных экспериментов, чтобы отметить любые совместные действия или поведение между участниками.
Первоначально вы кодируете все незаметные и очевидные действия, соответствующие вашим критериям, как кооперативные. Но, потратив несколько дней на эту задачу, вы кодируете только чрезвычайно полезные действия как совместные.
Вы постепенно отходите от первоначальных стандартных критериев кодирования данных, и ваши измерения становятся менее надежными.
Систематическая ошибка выборки возникает, когда некоторые члены совокупности с большей вероятностью будут включены в ваше исследование, чем другие. Это снижает обобщаемость ваших результатов, потому что ваша выборка не является репрезентативной для всего населения.
Уменьшение систематической ошибки
Вы можете уменьшить систематические ошибки, применяя эти методы в своем исследовании.
Триангуляция
Триангуляция означает использование нескольких методов для записи наблюдений, чтобы вы не полагались только на один инструмент или метод.
Например, если вы измеряете уровень стресса, вы можете использовать в качестве индикаторов ответы на опросы, физиологические записи и время реакции. Вы можете проверить, сходятся или перекрываются все три измерения, чтобы убедиться, что ваши результаты не зависят от конкретного используемого прибора.
Вы можете проверить, сходятся или перекрываются все три измерения, чтобы убедиться, что ваши результаты не зависят от конкретного используемого прибора.
Регулярная калибровка
Калибровка прибора означает сравнение показаний прибора с истинным значением известной стандартной величины. Регулярная калибровка вашего прибора с помощью точного эталона помогает снизить вероятность систематических ошибок, влияющих на ваше исследование.
Вы также можете калибровать наблюдателей или исследователей с точки зрения того, как они кодируют или записывают данные. Используйте стандартные протоколы и рутинные проверки, чтобы избежать дрейфа экспериментатора.
Рандомизация
Методы вероятностной выборки помогают гарантировать, что ваша выборка систематически не отличается от генеральной совокупности.
Кроме того, если вы проводите эксперимент, используйте случайное распределение, чтобы поместить участников в разные условия лечения. Это помогает противостоять предвзятости, уравновешивая характеристики участников между группами.
Это помогает противостоять предвзятости, уравновешивая характеристики участников между группами.
Маскировка
По возможности следует скрыть задание условия от участников и исследователей с помощью маскировки (ослепления).
На поведение или реакцию участников могут влиять ожидания экспериментатора и характеристики спроса в окружающей среде, поэтому контроль над ними поможет вам уменьшить систематическую предвзятость.
Часто задаваемые вопросы о случайной и систематической ошибке
- В чем разница между случайной и систематической ошибкой?
Случайная и систематическая ошибка — это два типа ошибок измерения.
Случайная ошибка — это случайная разница между наблюдаемыми и истинными значениями чего-либо (например, исследователь, неправильно взвешивающий весы, записывает неверное измерение).

Систематическая ошибка — это постоянная или пропорциональная разница между наблюдаемыми и истинными значениями чего-либо (например, неверно откалиброванные весы постоянно записывают веса выше, чем они есть на самом деле).
- Случайная ошибка или систематическая ошибка хуже?
Систематическая ошибка, как правило, является более серьезной проблемой в исследованиях.
При случайной ошибке множественные измерения будут группироваться вокруг истинного значения. Когда вы собираете данные из большой выборки, ошибки в разных направлениях компенсируют друг друга.
Систематические ошибки гораздо более проблематичны, поскольку они могут исказить ваши данные от истинного значения. Это может привести к ложным выводам (ошибки типа I и II) о взаимосвязи между изучаемыми переменными.

- Как избежать ошибок измерения?
Случайная ошибка почти всегда присутствует в научных исследованиях, даже в строго контролируемых условиях. Хотя вы не можете полностью избавиться от нее, вы можете уменьшить случайную ошибку, выполняя повторные измерения, используя большую выборку и контролируя посторонние переменные.
Вы можете избежать систематических ошибок, тщательно разработав процедуры отбора проб, сбора данных и анализа. Например, используйте триангуляцию для измерения ваших переменных несколькими методами; регулярно калибровать инструменты или процедуры; использовать случайную выборку и случайное распределение; и применяйте маскировку (ослепление), где это возможно.
Процитировать эту статью Scribbr
Если вы хотите процитировать этот источник, вы можете скопировать и вставить цитату или нажать кнопку «Цитировать эту статью Scribbr», чтобы автоматически добавить цитату в наш бесплатный генератор цитирования.
Бхандари, П. (2023, 13 февраля). Случайная и систематическая ошибка | Определение и примеры. Скриббр. Проверено 13 февраля 2023 г., из https://www.scribbr.com/methodology/random-vs-systematic-error/
Процитировать эту статью
Полезна ли эта статья?
Вы уже проголосовали. Спасибо 🙂 Ваш голос сохранен 🙂 Обработка вашего голоса…
Прита имеет академическое образование в области английского языка, психологии и когнитивной нейробиологии. Как междисциплинарный исследователь, она любит писать статьи, объясняющие сложные исследовательские концепции для студентов и ученых.