Классификация автомобилей — это… Что такое Классификация автомобилей?
По назначению
Грузовые
- По грузоподъёмности
- Особо малой грузоподъёмности — до 1 тонны
- Малой грузоподъёмности — 1-2 тонны
- Средней грузоподъёмности — 2-5 тонны
- Большой грузоподъёмности — свыше 5 тонн
- Особо большой грузоподъёмности — свыше предела, установленного дорожными габаритами и весовыми ограничениями
- По виду перевозимого груза
- По типу кузова
Пассажирские
Автобусы (вместимость свыше 8 человек)
- По габаритной длине
- Особо малый (до 5м)
- Малый (6 м — 7,5м)
- Средний (8 м — 9,5м)
- Большой (10,5 м — 12,0м)
- Особо большой (14,5 м и более)
- По назначению
- Городские
- Внутригородские
- Пригородные
- Местного сообщения (для сельских перевозок)
- Междугородные
- Туристические.

Легковые (вместимость до 8 человек)
- По размеру [источник не указан 672 дня]
- A-класс: малогабаритные городские автомобили. Типичные представители: Smart, Toyota iQ, Ford Ka, Hyundai i10, Renault Twingo, Chevrolet Spark, ЗАЗ, (Запорожец).
- B-класс: малогабаритные автомобили особо малого класса, большинство из которых имеет кузов хетчбэк (3 или 5 дверей) и передний привод. Типичные представители: Chevrolet Aveo, Opel Corsa, Fiat Punto, Toyota Yaris, Kia Rio, Seat Ibiza, Hyundai Solaris
- C-класс: средний класс (или Гольф-класс), большинство из которых имеет кузов хетчбэк (3 или 5 дверей). Типичные представители: Toyota Corolla, BMW 1, Renault 19, Toyota Auris, Volkswagen Golf, Seat Leon,Renault Megane, Opel Astra, Audi A3, KIA Ceed, Ford Focus, Chevrolet Cruze, Hyundai Elantra.
- D-класс: средний класс. Типичные представители: Audi A4, BMW 3, Opel Vectra C, Mercedes-Benz C-класс, Toyota Avensis, Suzuki Kizashi, Mitsubishi Galant, Hyundai Sonata YF, Volkswagen Passat, Ford Mondeo.

- E-класс: высший средний класс. Типичные представители: Audi A6, BMW 5, Mercedes-Benz E-класс, Toyota Avalon, Hyundai Genesis, Infiniti M, Lexus GS, Ford Scorpio, ГАЗ-31105.
- F-класс: представительский класс. Типичные представители: Audi A8, BMW 7, Hyundai Equus, Mercedes-Benz S-класс, Jaguar XJ, Lexus LS, ЗИЛ-41047.
- По типу кузова
- По рабочему объёму цилиндров двигателя
- Особо малый — до 1,2л
- Малый — от 1,2л до 1,8л
- Средний — от 1,8л до 3,5л
- Большой — свыше 3,5л
- Высший — не регламентируется
Грузопассажирские
- На базе легковых
- На базе грузовых
Специальные
- Уборочные автомобили
По степени приспособления к работе в различных дорожных условиях
- Дорожный (обычной проходимости) — предназначенный для работы по дорогам общей сети

- Вездеходы
По общему числу колёс и числу ведущих колёс
Условно обозначают формулой, где первая цифра — число колёс автомобиля, а вторая — число ведущих колёс, при этом каждое из сдвоенных ведущих колёс считается за одно колесо.
- 4х2 — двухосный автомобиль с одной ведущей осью (ГАЗ-53А, ЗИЛ-130)
- 4х4 — двухосный автомобиль с обеими ведущими осями
- 6х6 — трёхосный автомобиль со всеми ведущими осями (ЗИЛ-131)
- 6х4 — трёхосный автомобиль с двумя ведущими осями (КАМАЗ 5320)
- 2-x осные
- 3-x осные
- 4-x осные
- 6-и осные
По составу
По типу двигателя
- по способу преобразования тепловой энергии в механическую(внутреннего сгорания, с внешним подводом теплоты)
- по способу осуществления рабочего цикла (четырёхтактные с наддувом и без наддува, двухтактные с наддувом и без наддува)
- по способу воспламенения рабочей смеси(С искровым зажиганием, с воспламенением от сжатия, с воспламенением газового топлива от небольшой дозы дизельного топлива воспламеняющегося от сжатия, с форкамерно-факельным зажиганием)
- По роду используемого топлива(лёгкие жидкие топлива нефтяного происхождения (бензин, керосин), тяжёлые жидкие топлива нефтяного происхождения (мазут, соляровое масло, дизельное топливо), газовое топливо (природный газ, сжиженный газ нефтяного происхождения, биогаз), альтернативные топлива (спирты, водород, органические масла))
- по конструкции (поршневые тронковые, поршневые крейцкопфные, поршневые траверсные, поршневые барабанные, поршневые бесшатунные, роторно-поршневые, газотурбинные и др.
 )
) - по способу регулирования в зависимости от нагрузки (с количественным регулированием, с качественным регулированием, со смешанным регулированием)
- по способу охлаждения (жидкостного и воздушного охлаждения)
- Электродвигатели
- Газотурбинные двигатели
- Силовые агрегаты со свободно-поршневым генератором газа
По принадлежности
- Гражданские
- Личный автомобиль
- Государственный автомобиль
- Коммерческий автомобиль
- Военные
По типу шасси
- Колёсные
- Гусеничные
- Смешанное или комбинированное
По параметрам пробега
- Новые автомобили
- Автомобили с пробегом
См. также
Ссылки
Примечания
Классификация автомобилей: распространенные классы авто
Загрузка…Классификация автомобилей появилась в середине 20-го века, когда автомобильные бренды озадачились созданием классов. Моделей было настолько много, что возникла необходимость все это упорядочить. Этот вопрос СССР, особенно, не касался, тогдашних вариантов моделей машин можно было пересчитать по пальцам. А вот в Европе и в США, наоборот, в то время шло самое активное развитие автомобильной промышленности. На сегодняшний день классификаций автомобилей несколько. Но сначала поговорим о европейской классификации, которая легла в основу и российской системы классификации автомобилей, где каждому классу присвоена своя буква.
Моделей было настолько много, что возникла необходимость все это упорядочить. Этот вопрос СССР, особенно, не касался, тогдашних вариантов моделей машин можно было пересчитать по пальцам. А вот в Европе и в США, наоборот, в то время шло самое активное развитие автомобильной промышленности. На сегодняшний день классификаций автомобилей несколько. Но сначала поговорим о европейской классификации, которая легла в основу и российской системы классификации автомобилей, где каждому классу присвоена своя буква.Как не странно, тип кузова или цена автомобиля значения не имеют, в первую очередь, на классификацию автомобиля влияют размеры, вместительность и технические характеристики автомобиля. Рассмотрим основные модели, принадлежащие к тому или иному классу автомобилей.
Класс А — микроавтомобили с предельно малым объемом двигателе до 1,2 литра и с, естественно, небольшим размером кузова. Это: Дэу Матиз, Киа Пиканте, Пежо 106, Смарт и др. Данный вариант в системе классификации автомобилей подходит только для города.
Хэтчбеки A-класса 2018 года: Audi A1, Toyota Auris, Mercedes-Benz A-Class
Класс B — хоть и следующий, но тоже считается малым классом автомобилей. Он более популярен за счет соотношения функционала и цены. Размер машин в этом классе побольше — может достигать 4 метров, двигатель мощнее и объемнее — от 1,2 до 1,6 литров. Это: Фольксваген Поло, Лада Гранта, Пежо 206, Форд Фьюжн и Киа Рио — что называется, дешево и сердито.
Автомобили B-класса: Lada Granta, Hyundai Solaris и Volkswagen Polo
Класс С — автомобили, имеющие вместительность 5 человек и двигатель до 2-хлитров. Его яркие представители: Фольксваген Гольф, Форд Фокус, Хонда Цивик, Тойота Королла и т.д. — типичные городские лошадки.
Седаны C-класса: Audi A3, Peugeot 408, Kia Cerato
Класс D — большие семейные автомобили, где размер имеет значение. В длину эти машины достигают 5 метров и имеют объем двигателя до 2,5 литров. Это, в первую очередь, Фольксваген Пасса, Форд Мондео и др. Вот они уже с претензией.
В длину эти машины достигают 5 метров и имеют объем двигателя до 2,5 литров. Это, в первую очередь, Фольксваген Пасса, Форд Мондео и др. Вот они уже с претензией.
Автомобили D-класса: Kia K5, Hyundai Sonata 8, Volkswagen Arteon
Класс E — бизнес-класс. Здесь все ясно. Это: БМВ 5, Ниссан Тиана, Тойота Камри, Мерседес-Бенц Е. Автомобили данного класса имеют просторный салон, большой объем двигателя и кузова, такую же цену и, конечно же, престиж.
Автомобили бизнес-класса: Volvo S80, Audi A6, Jaguar XF
Класс K — люксовые внедорожники. К ним относятся: БМВ X5 (X6), Мерседес-Бенц GL (ML) и т.д. и т.п., все перечислять, наверное, нет смысла, просто не хватит времени.
Люксовые внедорожники: Hyundai Santa Fe, Range Rover Sport, BMW X5
Класс J — брутальные внедорожники и кроссоверы, такие как Nissan Pathfinder, Nissan Patrol, Ford Ranger и др. Все они обладают повышенной проходимостью, мощным двигателем и надежной конструкцией подвески.
Все они обладают повышенной проходимостью, мощным двигателем и надежной конструкцией подвески.
Большие люксовые внедорожники: Lamborghini Urus, Bentley Bentayga, Rolls-Royce Cullinan
Кстати, в Америке, классификация автомобилей схожа с европейской. Класс автомобиля там тоже зависит от размера, но в названии не используют буквы. Все просто: мини, субкомпакт, компакт, среднеразмерный, полноразмерный и т.д.
Конечно, вся эта система классификации автомобилей удобна, скорее, для профессионалов. Простой обыватель, вряд ли «заморачивается» по поводу, на машине какого класса он катается. Да и, в общем-то, оно и не надо.
ПОХОЖИЕ СТАТЬИ:Европейская классификация автомобилей
Класс автомобилей представляет собой термин, который используется для отличия разных типов транспортных средств. В Америке он определяется после измерения объема салона и багажника. Также там применяется классификация машин по рыночной оценке. В Японии существует три класса автомобилей: стандартные, малые и мини. В Европе, в частности в Италии, используется европейская классификация автомобилей. А ее основе лежат габаритные размеры машин.
В Японии существует три класса автомобилей: стандартные, малые и мини. В Европе, в частности в Италии, используется европейская классификация автомобилей. А ее основе лежат габаритные размеры машин.
Производители чаще всего ее применяют для определения места автомобиля на рынке, поэтому внутри одного класса можно встретить модели, обладающие абсолютно разными характеристиками, набором опций и использованием в производстве разных технологий. Границы между ними существуют довольно условные и постепенно размываются, потому что автопроизводители стараются предоставить покупателям более заряженные автомобили за те же деньги.
Популярные машины
Сегмент «А» включает малогабаритные автомобили, которые предназначены для эксплуатации в стесненных городских условиях. Данные машины не превышают по ширине 1,6м и по длине 3,6м. Их динамические и ходовые качества в основном посредственные, а кузов 3-5-дверный хэтчбек. Такие модели привлекают своей экономичностью и широкими возможностями, позволяющими легко парковаться в ограниченном городском пространстве. Поэтому они часто используются прокатными компаниями для предоставления дешевой аренды авто в Италии. Среди типичных представителей этого сегмента стоит отметить «Renault Tvingo», «Smart», «Ford K». Популярный сегмент «В» отличается наличием в машинах переднего привода и кузова хетчбэк. Он объединяет малогабаритные машины шириной до 1,7 м и длиной до 3,9 м. Кроме хетчбэков сюда иногда входят универсалы и седаны с объемом двигателя до 1,6 л. Его типичными представителями является «Opel Corsa», «Ford Fiesta» и «Fiat Punto».
Поэтому они часто используются прокатными компаниями для предоставления дешевой аренды авто в Италии. Среди типичных представителей этого сегмента стоит отметить «Renault Tvingo», «Smart», «Ford K». Популярный сегмент «В» отличается наличием в машинах переднего привода и кузова хетчбэк. Он объединяет малогабаритные машины шириной до 1,7 м и длиной до 3,9 м. Кроме хетчбэков сюда иногда входят универсалы и седаны с объемом двигателя до 1,6 л. Его типичными представителями является «Opel Corsa», «Ford Fiesta» и «Fiat Punto».
Низшим средним классом считается сегмент «С». Его часто называют «гольф-классом». Сюда включаются относительно компактные, но достаточно вместительные автомобили. Этот сегмент считается наиболее популярным на территории Европы. В течение последних десятилетий законодателем в этой группе был «Volkswagen Golf». Предельная ширина представителей «гольф-класса» равна 1,75 м, а длина — 4,4 м. Типы кузовов — седан, универсал и хэтчбек. Иногда встречаются кабриолеты и купе. Эксплутационные и динамические характеристики варьируются в достаточно широких пределах. Эти машины комфортны для путешествий. К типичным представителям данного сегмента относится «Toyota Corolla», «Opel Astra» и «VW Golf».
Эксплутационные и динамические характеристики варьируются в достаточно широких пределах. Эти машины комфортны для путешествий. К типичным представителям данного сегмента относится «Toyota Corolla», «Opel Astra» и «VW Golf».
Машины среднего и представительского класса
Семейный или средний класс «D» относится к одним из самых быстро развивающихся. Сюда входят универсалы, хетчбэки и седаны, имеющие просторные салоны, объёмные багажники, длину, не превышающую 4,7м и ширину — 1,8м. Основные представители: «Audi A4», «VW Passat», «Hyundai Sonata» и «Opel Vektra». Высший бизнес-класс «Е» представлен роскошными седанами и универсалами, обладающими просторным салоном и высоким набором базовой комплектации. Машины этого сегмента по длине превышают 4,6м, а по ширине — 1,7м. Сюда относится «Opel Omega», «BMW 5-серии», «Renault Safrane».
Люкс или представительский класс «F» собрал комфортабельные мощные машины с кузовами исключительно седанами и очень просторными салонами. Их ширина обычно превышает 1.7 м, а длина — 5 м. К типичным представителям относится «Lexus LS», «BMW 7-серии», «Jaguar XJ8». Кроме основных классов существует несколько отдельных групп. Это сегмент «S», объединяющий спорткары, кабриолеты и купе, сегмент «J», включающий кроссоверы, внедорожники и спортивно-утилитарные автомобили, а также сегмент «M» — универсалы повышенной вместительности и минивэны.
Их ширина обычно превышает 1.7 м, а длина — 5 м. К типичным представителям относится «Lexus LS», «BMW 7-серии», «Jaguar XJ8». Кроме основных классов существует несколько отдельных групп. Это сегмент «S», объединяющий спорткары, кабриолеты и купе, сегмент «J», включающий кроссоверы, внедорожники и спортивно-утилитарные автомобили, а также сегмент «M» — универсалы повышенной вместительности и минивэны.
Будем рады ответить на Ваши дополнительные вопросы — воспользуйтесь формой запроса или звоните:
(495) 730-13-30 или 912-80-20.
Мы работаем с 09:00 до 20:30 в будние дни и с 11:30 до 15:30 по субботам.
Дополнительная информация:
Классификация разгрузочных машин механического действия
Разгрузочные машины механического действия. Стационарный скребковый разгрузчик применяется для разгрузки железнодорожных платформ.
Классификация разгрузочных машин
Разгрузочные машины механического действия
Стационарный скребковый разгрузчик применяется для разгрузки железнодорожных платформ.
Конструкция скребкового погрузчика
- скребок;
- направляющие;
- рукоять;
- станина;
- конвейер;
- бункер.
Самоходный элеваторный разгрузчик применяется для разгрузки полувагонов (с щебнем, гравием, песком и т.д.).
Оборудование пневматического действия
Вакуумный разгрузчик применяется для разгрузки цемента из вагона общего назначения.
Установка нагнетательного действия применяется для разгрузки цемента из вагонов-хопперов.
Специальные транспортные устройства (машины, установки) и дополнительные компоненты (вспомогательные устройства) к ним, которые используются для погрузочно-разгрузочных работ, основываясь на механизме работы подразделяются на: аппараты (машины, устройства, установки) цикличного действия и аппараты (машины, устройства, установки) непрерывно действия.
Аппараты цикличного действия функционируют в виде замкнутого цикла операций, которые постоянно повторяются. Это может быть механизм захвата образца, перемещение сыпучих материалов на заданное расстояние, выгрузка продукта в определенном месте. Такой процесс состоит из повторяющегося набора последовательных операций. Перевозимые продукты, образцы или материалы могут быть сыпучие, штучные и т.д. Экскаваторы, краны-погрузчик, краны на автомобиле, разгрузчики железнодорожных вагонов и некоторые другие относятся к этому классу устройств.
Это может быть механизм захвата образца, перемещение сыпучих материалов на заданное расстояние, выгрузка продукта в определенном месте. Такой процесс состоит из повторяющегося набора последовательных операций. Перевозимые продукты, образцы или материалы могут быть сыпучие, штучные и т.д. Экскаваторы, краны-погрузчик, краны на автомобиле, разгрузчики железнодорожных вагонов и некоторые другие относятся к этому классу устройств.
Аппараты непрерывного действия — устройства (машины, установки), осуществляющие постоянный отбор материала или постоянное перемещение чего-либо к определенному месту, а также дополнительные компоненты к ним. Такие приборы представлены многоковшовыми погрузчиками с подгребающим и черпающим питателями, передвижными ленточными конвейерами, элеваторами, шнеками, большим количеством аппаратов, которые используются как вспомогательные транспортные устройства (дополнительные компоненты) к погрузочно-разгрузочным машинам.
Установки пневматического действия и разгрузчики железнодорожных вагонов (а также вспомогательные/дополнительные устройства к ним) — отдельный тип аппаратов непрерывного действия, они состоят из таких аппаратов, которые перемешивают материал в потоке воздуха и таких аппаратов, которые перемешивают материал аэрационно.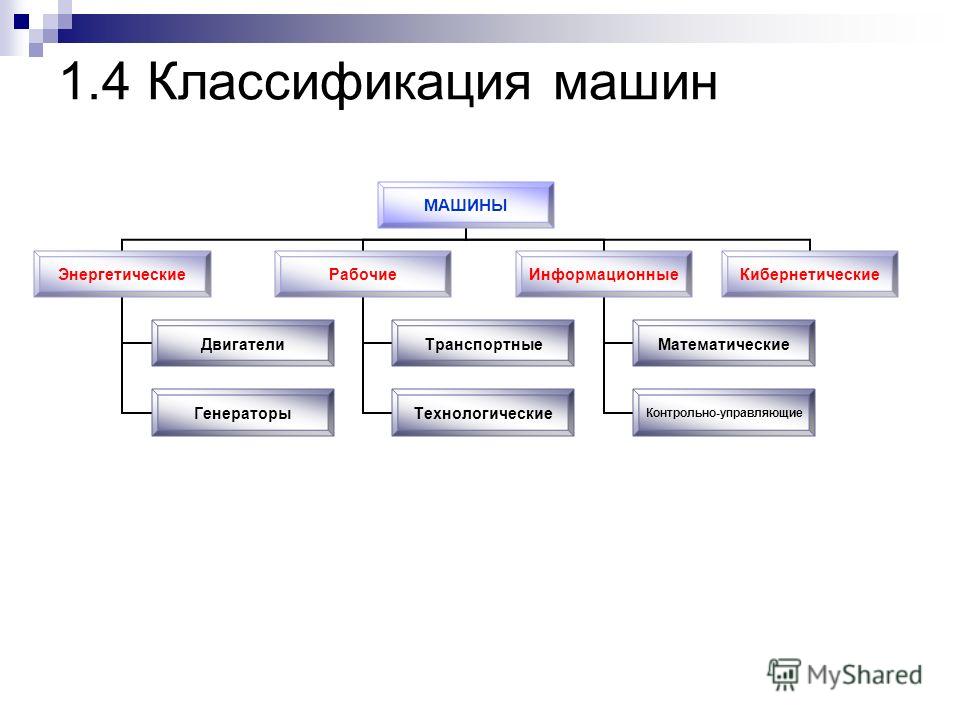
По типу образования воздушного потока и механизмам движения приборы подразделяют они на установки всасывающего, всасывающе-нагнетательного, нагнетательного действий. Первый тип из них может классифицироваться на те приборы, которые перемешивают мелкодисперсные материалы (гипс, цемент, известь) без участия атмосферного воздуха (вакуумные условия) и такие приборы, которые перемешивают зерно с участием воздуха атмосферы (они не используется в строительстве и не рассматриваются).
Классификация по степени разрежения воздуха следующая: низкий вакуум (максимально — 100 мм. вод. ст.), который создают с использованием вентиляторов, средний вакуум (до 3000 мм. вд. ст.), который создают с использованием воздуходувки и высокий вакуум (до 700 мм. рт. ст.), с использованием кольцовых вакуумных насосов.
Установки всасывающе-нагнетательного действия ранжируются так же как и установки всасывающего действия, но также содержат схему пневматических подъемников, которые увеличивают расстояние транспортного материала.
Последний тип приборов — установки нагнетательного действия, которые состоят из аппаратов способных перемешивать продукт в потоке сжатого воздуха строго вертикально или почти вертикально (около 70°) внутри трубы за счет пневматических винтовых или камерных подъёмников. А также, установки произвольной конфигурации (они могут быть с наклонной конфигурацией, вертикальной или поворотной), осуществляющие перемешивание за счет следующих типов насосов — винтовые, струйные и камерные.
Дата публикации статьи: 18 мая 2016 в 03:28Последнее обновление: 29 сентября 2021 в 11:40
Загрузка…
Классификация автомобилей по классам — классы авто
Сегодня существует определенная классификация автомобилей по классам, которая делит все современные средства передвижения (в зависимости от их размера) на шесть классов, обозначенных буквами латинского алфавита «А», «В», «С», «D», «Е», «F». Остановимся на каждом из них более детально.
Представитель A класса
«А» класс включает в себя автомобили с минимальными размерами кузова (длина до 3,6м, ширина – не более 1,6м). Обычно такие транспортные средства хорошо использовать в условиях современных тесных мегаполисов. Автомобили «А» класса в большинстве своем имеют трехдверный тип кузова, однако встречаются и пятидверные машины в кузове «hatchback». Отличительная особенность автомобилей данного класса заключается в их экономичном расходе топлива. Не исключено, что именно поэтому они являются востребованными в европейских странах, отличающихся бережным и экономным отношением к ресурсам.
Обычно такие транспортные средства хорошо использовать в условиях современных тесных мегаполисов. Автомобили «А» класса в большинстве своем имеют трехдверный тип кузова, однако встречаются и пятидверные машины в кузове «hatchback». Отличительная особенность автомобилей данного класса заключается в их экономичном расходе топлива. Не исключено, что именно поэтому они являются востребованными в европейских странах, отличающихся бережным и экономным отношением к ресурсам.
Автомобили B класса
«В» класс включает в себя так называемые малолитражки (длина до 3,9м, ширина – не более 1,7м). Такие автомобили пользуются большой популярностью в европейских государствах и в странах средиземноморья. Большинство представителей класса имеют кузов «hatchback» с передним приводом. «В» класс характеризуется достаточно высокой степенью комфорта и для водителя, и для пассажиров, однако на задних сидениях свободно будут чувствовать себя не более двух пассажиров. Нередко можно услышать, что транспортные средства, принадлежащие к классу «В», называют дамскими автомобилями.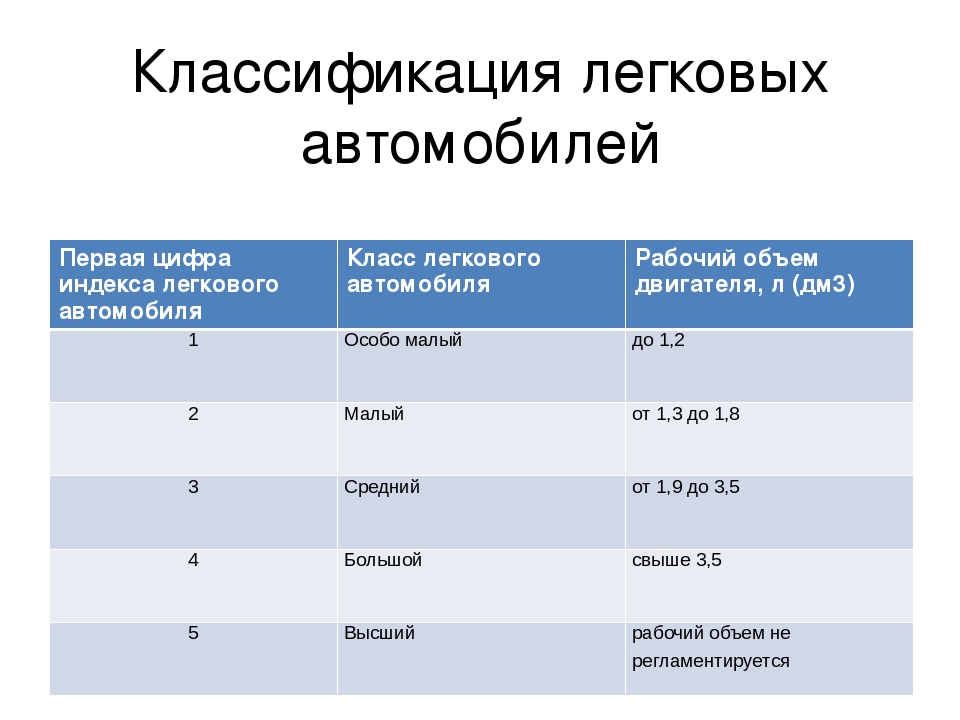
C класс
«С» класс объединяет в себе машины так называемого «Гольф-класса» (длина до 4,3м, ширина – не более 1,8м), названного в честь автомобиля Volkswagen Golf, который по праву считается его основателем. В салоне автомобилей данного класса кроме водителя помещаются еще четыре человека.
При полной загрузке салона (пять человек) пассажирам на заднем сидении будет достаточно тесно.
Автомобили D класса
«D» класс (длина до 4,6м) находится посередине классификационной шкалы транспортных средств, поэтому его представители являются отличными автомобилями для большой семьи в кузовах «hatchback» и «sedan». Автомобили класса «D» имеют вместительный багажник и отличаются большим просторным салоном. Внутри класса автомобили можно разделить на семейные и элитные. Семейные транспортные средства хорошо сочетают в себе потребительские качества и объемный салон.
Элитные автомобили отличаются повышенным комфортом, наличием мощного двигателя, способного составить конкуренцию многим спортивным моделям машин, и большим количеством различных опций, которые присутствуют уже в стандартной комплектации.

Следует заметить, что стоимость элитных автомобилей «D» класса довольно высока.
Мерседес E класса
«Е» класс (длина более 4,6м) объединяет в себе автомобили, обладающие вместительным и комфортным салоном, насыщенной комплектацией стандартного пакета опций. Кроме того, машины бизнес-класса оснащаются сложными независимыми системами подвески и отличаются наличием большой колесной базы. Данное сочетание придает машинам плавность и бесшумность хода, способствует отличной устойчивости на дорогах.
Управление такими транспортными средствами не создает ощущения дискомфорта даже после нескольких часов непрерывного вождения.
F класс
«F» класс (длина более 5м) является представительским классом. Все автомобили высшего класса имеют кузов «sedan», просторные салоны, мощные двигатели (шесть и более цилиндров). На машины «F» класса устанавливаются только самые передовые и функциональные электронные системы. При отделке салонов применяются эксклюзивные и дорогостоящие материалы. Владельцы представительских автомобилей зачастую пользуются услугами наемных водителей, в то время как сами, расположившись на заднем сидении, управляют различными электронными системами, которые значительно повышают комфорт во время передвижения.
При отделке салонов применяются эксклюзивные и дорогостоящие материалы. Владельцы представительских автомобилей зачастую пользуются услугами наемных водителей, в то время как сами, расположившись на заднем сидении, управляют различными электронными системами, которые значительно повышают комфорт во время передвижения.
Кабриолет-купе
Существует еще несколько обособленных групп транспортных средств, которые нельзя отнести под какой-либо из представленных в статье классов:
- «Кабриолет/купе». Представители данной группы – это двух и четырехместные спортивные автомобили, популярность которых ежегодно набирает обороты в европейских странах.
- «Внедорожник» — полноприводные транспортные средства, рассчитанные на пассажирские и грузопассажирские перевозки.
- «УВП (универсал повышенной вместимости)/мин-вэн». Представители класса – пяти – девяти местные машины.
- «Кроссовер» — наиболее «молодая» категория транспортных средств. Автомобили этой категории сочетают в себе качества сразу нескольких классов транспортных средств.

Внедорожники
В последнее время границы, разделяющие автомобили на различные классы, постепенно стираются. Происходит это по причине того, что производители транспортных средств, в жесткой борьбе за своих покупателей, стараются снабдить машину наибольшим количеством различных дополнительных опций и увеличить общий уровень комфорта, не поднимая конечную стоимость автомобиля. Помимо этого практически каждую обновленную модель производитель увеличивает в кузове на 10 – 15 см.
Видео
О всех буквенных сокращениях классов автомобилей смотрите в следующем ниже видео:
Классификация и структура машин. Основные требования предъявляемые к машинам и механизмам ПОП. Классификация оборудования ПОП
Контрольная работа по дисциплине
«Оборудование» № 02858
Вопрос №4. Классификация и структура машин. Основные требования предъявляемые к машинам и механизмам ПОП. Классификация оборудования ПОП
Классификация и структура машин. Основные требования предъявляемые к машинам и механизмам ПОП. Классификация оборудования ПОП
Машины и механизмы, применяемые на предприятиях общественного питания, классифицируют: по структуре рабочего цикла, функциональному признаку, степени механизации и автоматизации, технологических процессов, виду и свойствам продуктов (предметов), подвергающихся обработке.
По структуре рабочего цикла различают машины и механизмы непрерывного и периодического действия. В машинах и механизмах непрерывного действия процессы загрузки, обработки и выгрузки продукта происходят непрерывно. Продукты постоянно поступают в рабочую камеру, перемещаются вдоль неё и одновременно подвергаются воздействию рабочих органов машины, после чего удаляются из рабочей камеры.
В машинах и механизмах периодического действия продукт обрабатывается рабочими органа в течение определенного времени. Приступить к обработке следующей порции продукта можно только после того, как из рабочей камеры машины будет выгружен обработанный продукт.
По функциональному признаку машины и механизмы подразделяют на группы оборудовании, характеризующиеся одинаковым воздействием на обрабатываемый продукт.
По степени механизации и автоматизации выполняемых технологических процессов различают машины неавтоматические, полуавтоматические и автоматические. В машинах неавтоматического действия нагрузка, выгрузка, контроль и вспомогательные технологические операции выполняются оператором. В машинах полуавтоматического действия основные технологические операции выполняются машиной; ручными остаются только транспортные, контрольные и некоторые вспомогательные процессы. В машинах автоматического действия все технологические и вспомогательные процессы выполняются машиной. Они могут использоваться в составе поточных и поточно-механизированных линий и полностью заменять труд человека.
По виду и свойствам продуктов (предметов), подвергающихся обработке, машины и механизмы подразделяют на следующие группы.
1. Машины для обработки овощей и картофеля — сортировочные, моечные, очистительные, овощерезательные, протирочные, поточные линии по переработке овощей.
2. Машины для обработки мяса и рыбы — мясорубки, фаршемешалки, мясорыхлительные машины, котлетоформовочные, рыбоочистительные.
3. Машины для приготовления теста и кремов — просеиватели, тестомесильные машины, тестораскаточные, взбивальные.
4. Универсальные приводы общего и специализированного назначения.
5. Машины для нарезки хлеба и гастрономических продуктов.
6. Посудомоечные машины.
7. Подъемно-транспортные машины.
Основные части машин. Машина представляет собой совокупность механизмов: двигательного, передаточного и исполнительного, которые состоят из большого числа деталей. Деталью называется часть машины, изготовленная без сборочных операций. Соединение нескольких деталей называется узлом.
Основными узлами любой машины, используемой на предприятиях общественного питания, являются станина, корпус, приводной и исполнительный механизмы, а также аппаратура управления.
Станина — это неподвижное основание, на котором укрепляются все узлы машины.
Корпус машины предназначен для размещения приводного и исполнительного механизмов. Станина и корпус могут выполняться как единое целое.
В состав приводного механизма входят электродвигатель, преобразующий электрическую энергию в механическую, и передаточный механизм (передача), передающий движение от электродвигателя к исполнительному механизму.
Исполнительный механизм состоит из рабочей камеры — закрытого пространства, где осуществляется процесс обработки продукта, и рабочих органов — деталей, которые осуществляют этот процесс. Рабочая камера имеет загрузочное и разгрузочное устройства.
Аппаратура управления служит для пуска и останова машины, а также для контроля за ее работой.
Рассматривая узлы различных машин, можно обнаружить, что в их состав входит большое количество однотипных деталей или деталей общего назначения (валы, оси, опоры, подшипники и др.).
Другие детали характерны только для определенного типа машин — это детали специального назначения.
Требования к материалам, используемым для изготовления машин. Для изготовления деталей и узлов выбирают материалы, обеспечивающие надежность работы машины при минимальных массе, габаритах и стоимости.
Основными материалами для изготовления деталей машин служат черные и цветные металлы или их сплавы, а также пластмассы и другие синтетические материалы. К черным металлам относятся сплавы железа, важнейшими из которых являются чугуны и стали.
Чугун обладает высокими литейными свойствами и применяется для изготовления деталей сложной конфигурации.
Сталь прочнее чугуна, легче сваривается и лучше обрабатывается. Из стали обыкновенного качества изготовляют сварные корпусные детали, крышки, кожухи и другие детали. Если в состав стали ввести небольшое количество цветных металлов (хром, никель и др.), то можно увеличить ее прочность, твердость, пластичность, а также устойчивость к коррозии и износу. Такие стали называются легированными. Они применяются для изготовления деталей машин, непосредственно контактирующих с пищевыми продуктами. Для лужения стальных деталей используют олово (лужение рабочих органов мясорубок).
Большое применение в машиностроении находят пластмассы, детали из которых (шестерни, шкивы) легче металлических, бесшумны в работе и имеют достаточную прочность, износоустойчивость, антикорозийность.
Из цветных металлов для изготовления деталей, соприкасающихся с пищевыми продуктами, используют сплавы алюминия.
Материалы, контактирующие с пищевыми продуктами, должны быть инертны к жирам, маслам, влаге, кислотам и запахам, быть антикоррозийными, легко поддаваться чистке, мытью, обеззараживанию и просушиванию. Кроме того, они не должны оказывать вредного воздействия на продукты или готовую пищу.
Вопрос №17. Роторные овощерезки: типы, назначение, устройство. Принцип действия и правила эксплуатации, отличительные особенности
Для нарезки сырых и вареных овощей на кусочки определенной формы на предприятиях общественного питания применяются овощерезательные машины. Промышленность выпускает овощерезки с механическим и ручным приводом. Машины для нарезки вареных овощей устанавливаются в холодных цехах, а машины для нарезки сырых овощей устанавливаются в овощных и горячих цехах. Форма частиц нарезного продукта зависит от конструкции ножа. В движение они приводятся от индивидуальных или универсальных приводов.
В зависимости от принципа работы овощерезательные машины бывают: дисковые, роторные, пуансонные и с комбинированным срезом. Дисковые овощерезательные машины имеют комплект ножей с лезвиями прямоугольной или криволинейной формы. Эти сменные ножи являются рабочими органами, укрепляются на опорном диске, который получает вращательное движение от индивидуального или универсального привода.
Срез продукта в дисковых овощерезательных машинах происходит за счет прижатия продукта к вращающему диску. Толщина срезанного слоя продукта определяется расстоянием между плоскостью ножа и диска. %о расстояние может регулироваться по заданной величине. Форма частиц нарезанного продукта зависит от конструкции установленного ножа на опорный диск. В роторных овощерезательных машинах продукт, загруженный в камеру, заклинивается между пластинами вращающегося ротора и неподвижной цилиндрической стенкой рабочей камеры. При этом продукт под действием центробежной силы прижимается к внутренней стенке рабочей камеры и скользит по ней. Овощи нарезаются неподвижными ножами в зависимости от формы установленных ножей.
В пуансонных овощерезательных машинах измельчение продукта происходит путем продавливания их поршнем через неподвижную ножевую решетку.
В комбинированных овощерезательных машинах нарезка производится с помощью вращающихся горизонтальных прямолинейнывх ножей и неподвижной ножевой решетки с вертикальными прямолинейными ножами.
Принцип работы овощерезок сводится к следующему, а производится с помощью вращающихся горизонтальных прямолинейных ножей и неподвижной ножевой решетки с вертикальными прямолинейными ножами.
Принцип работы овощерезок сводится к следующему. Через загрузочный бункер сырые овощи поступают к вращающемуся ножевому диску, увлекаются им вниз, заклиниваются между стенкой бункера и диском (благодаря улиткообразной форме бункера) и нарезаются ножами диска. Отрезанные частицы овощей проходят через щель между ножами и диском и собираются в подставленную тару.
Техника безопасности и эксплуатации машины заключается в следующем. Включают электродвигатель и через загрузочный бункер засыпают промытые сырые овощи. Овощи должны поступать равномерно и в достаточном количестве, в противном случае качество нарезки ухудшается. Запрещается проталкивать измельченные овощи к вращающемуся ножевому диску руками, для этой цели следует пользоваться деревянным толкачом. При работе на машине работники должны иметь сухую и специальную форму одежды, категорически запрещается во время работы отвлекаться и покидать рабочее место до окончания работы с машиной. После работы машину разбирают, промывают и просушивают. Затем во избежание появления ржавчины рабочий вал и ножи смазывают пищевым несоленым жиром. При снятии диска с ножами с горизонтального вала обязательно нужно использовать специальный крючок. На техническое обслуживание овощерезательных машин составляется график обслуживания из расчета не реже одного раза» в 10 дней. В этот день квалифицированный механик, который закреплен за данным предприятием, проводит обслуживание — смазывание, крепление, заточку или замену ножей и т.д.
Овощерезательная машина МРО-400-1000 с роторным приспособлением. Машина состоит из станины, корпуса, приводного и исполнительного механизмов, а также механизма управления. Выполнена она с двумя сменными исполнительными приспособлениями — роторным и дисковым.
Конструкция дискового приспособления аналогична конструкции дискового приспособления машины МРО-50-200. Роторное приспособление состоит из загрузочной емкости (барабана), подвижного ротора с лопастями и режущего инструмента в виде ножевых блоков.
Барабан крепится к корпусу неподвижно и имеет откидную крышку. Внутрь барабана вставляется ротор с тремя вертикальными лопастями, подающими продукт к режущему инструменту. Последний представляет собой блок с плоскими ножами для нарезки овощей кружочками и шинкования капусты (3 мм) и блок с ножом и ножевой гребенкой для нарезки овощей брусочками (3X3, 6X6, 10X10 мм). Толщина нарезки продукта регулируется и равняется расстоянию от стенки камеры до лезвия ножа. Во время работы машины ножи остаются неподвижными, а ротор вращается.
Принцип действия. К корпусу с помощью зацепа и фиксатора крепят барабан, внутрь которого помещают ротор, затем устанавливают сменный ножевой блок. Продукт через загрузочное отверстие попадает на вращающийся ротор, лопасти которого прижимают его к стенкам барабана. Прижатый и скользящий по внутренней стенке камеры продукт при каждом обороте ротора нарезается, выталкивается через щель камеры наружу и попадает в разгрузочный лоток.
Для безопасной работы машина МРО-400-1000 снабжается блокировочным выключателем.
Вопрос №23 Машины для замеса теста: типы, назначение, устройство, принцип действия, правила эксплуатации, сравнительная характеристика
Тестомесильная машина ТММ-1М. Машина состоит из чугунной фундаментной плиты, корпуса, дежи, месильного рычага с лопастью и приводного механизма. Фундаментная плита служит станиной, на которой устанавливают тележку с дежой. Последняя является рабочей камерой и представляет собой бак конической формы. Машина имеет три сменные дежи вместимостью 140 л каждая. Для равномерного перемешивания теста деже сообщается вращательное движение. С нижней стороны дежа имеет хвостовик с квадратным сечением, один конец которого жестко прикреплен к ее днищу, а другой входит в гнездо приводного диска, смонтированного на редукторе привода дежи. При накатывании и скатывании дежи хвостовик приподнимается с помощью ножной педали и выходит из зацепления с диском.
Дежа укреплена на трехколесной тележке. Тележка имеет два больших колеса и одно вращающееся малое, благодаря чему тележка легко поворачивается в любую сторону при передвижении по полу.
Рабочим органом машины служит месильный рычаг— стержень, изогнутый под углом 118° и имеющий на конце лопасть. Месильный рычаг совершает сложное качательное движение вверх и вниз. Для перевода месильного рычага в верхнее положение в корпусе машины установлен маховичок, доступ к которому осуществляется через имеющуюся на корпусе дверку с кнопками управления.
Над дежой укреплена дуга с ограждающими щитками для предотвращения выбрасывания теста и защиты рабочего. Дуга соединена с корпусом машины и имеет рукоятку для подъема и опускания щитков.
Машина имеет блокировку, отключающую электродвигатель при поднятии щитков.
Приводной механизм машины состоит из электродвигателя, двух червячных редукторов и цепной передачи. Движение от электродвигателя через один червячный редуктор передается деже, а через другой червячный редуктор и цепную передачу — месильному рычагу с лопастью.
Принцип действия. Загруженные в дежу продукты благодаря движениям месильного рычага и одновременному вращению дежи вокруг своей оси интенсивно перемешиваются, образуя однородную насыщенную воздухом массу.
Тестомесильная машина МТМ-15. Машина устанавливается на специализированных предприятиях общественного питания и предназначена для замешивания крутого теста, используемого для приготовления пельменей, вареников, чебуреков и домашней лапши.
Машина (рис. 4.3, б) состоит из платформы, съемного резервуара, двух Z-образных лопастей, редуктора и электродвигателя.
Рабочей камерой машины служит резервуар, в котором горизонтально расположены две месильные лопасти. Валы редуктора имеют на концах шипы для установки месильных лопастей.
Электродвигатель, а также приборы включения и блокировки расположны на крышке редуктора.
Резервуар устанавливается на опоры платформы и фиксируется стопорными винтами от осевого смещения. Сверху он закрыт решетчатой крышкой с электроблокировкой. Крышка на резервуаре крепится крючком-фиксатором.
Принцип действия. Вращение от электродвигателя через червячную и зубчато-цилиндрическую передачи передается лопастям. Продукт, находящийся в резервуаре, перемешивается лопастями и насыщается воздухом. Загрузка продуктов в резервуар производится через решетку крышки в процессе работы машины.
Тестомесильная машина МТИ-100. Машина предназначена для интенсивного замеса дрожжевого и пресного теста. Машина устанавливается в крупных цехах производительностью 20—50 тыс. изделий в день.
Машина состоит из станины, приводной головки с рабочими органами, кронштейна с баком, механизма подъема, тележки, пульта управления.
Станина, закрепленная на литом основании, имеет направляющие для перемещения приводной головки и кронштейна с баком.
Приводная головка представляет собой корпус, в котором заключены зубчатая передача и планетарный редуктор, клиноременная передача и электродвигатель. На валу электродвигателя установлены шкив клиноременной передачи и шкив электромагнитного тормоза. При включении электродвигателя в электрическую цепь создается эффект растормажи-вания.
Рабочими органами в машине служат: месильный крюк (для замеса дрожжевого, пресного и слоеного теста), месильный шнек (для замеса песочного теста) и четырехлопастный месильный инструмент (для подготовки полуфабрикатов песочного теста). Шнек крепится к центральной части планетарного редуктора, остальные — к валу сателлита.
Рабочую камеру (бак) устанавливают на тележку, которая представляет собой кольцо с тремя поворотными самоустанавливающимнея опорами. Бак имеет днище с подъемом в центре во избежание образования «мертвой зоны». Корпус приводной головки и кронштейн, на котором крепится бак, автономно перемещаются по вертикальным направляющим, получая движение от индивидуального привода.
Защитный зонт ограждает рабочие органы и предотвращает разбрызгивание продуктов. В нем имеется загрузочный люк с откидной крышкой.
На пульте управления помещены четыре пусковые кнопки, тумблер для включения освещения бака и сигнальная лампа, показывающая подачу напряжения.
Принцип действия. Машину включают, и на пульте загорается сигнальная лампочка. Затем включают механизм подъема, в результате чего кронштейн, двигаясь вверх, подхватывает бак за цапфы и снимает его с тележки. Одновременно приводная головка с месильным рычагом опускаются вниз и отключаются электродвигатель и электромагнит тормоза.
Вращение от электродвигателя через поликлиновую и зубчато-цилиндрическую передачу передается планетарному редуктору, а затем одному из месильных рычагов. Шнекообразную лопасть крепят к центру водила, поэтому она получает вращательное движение.
Правила эксплуатации. Перед началом работы машины ТММ-1М проверяют надежность крепления дежи к фундаментной плите и опробывают работу машины на холостом ходу. Затем в дежу загружают продукты, предназначенные для замеса теста. При замесе жидкого теста дежу загружают на 80—90 %, при замесе крутого теста — на 50 % вместимости. Несоблюдение этих требований приводит к быстрому износу машины. Далее опускают щитки и включают машину.
При замесе дрожжевого теста в дежу загружают дрожжи, сахар, соль, яйца, молоко или воду. После получения однородной массы машину выключают, добавляют муку и продолжают замес теста. Продолжительность замеса в среднем составляет 7—20 мин и зависит от вида теста.
После окончания замеса теста выключают электродвигатель, при этом месильный рычаг должен находиться в верхнем положении — вне дежи. Если рычаг мешает скатыванию дежи, его можно поднять с помощью маховичка. Далее поднимают ограждающие щитки и, нажав ногой на педаль, скатывают дежу с фундаментной плиты.
В машине МТМ-15 лопасти закрепляют в шипах редуктора, а резервуар фиксируют стопорным винтом. Затем заливают в резервуар жидкие компоненты, опускают крышку-решетку, включают машину и засыпают муку через решетку. После окончания замеса выключают электродвигатель, снимают крышку и выгружают тесто.
В машине МТИ-100 бак подкатывают на тележке, закрепляют на кронштейне и устанавливают необходимый рабочий орган. Затем с помощью механизма подъема производится перемещение приводной головки и кронштейна с баком: при подъеме бака головка опускается и рабочий орган входит в бак. При опускании бака происходит все наоборот. При необходимости разгрузки бака непосредственно на машине тележку откатывают, опускают бак и снимают месильный рычаг. Бак поворачивают на цапфах и выгружают тесто в подставленную тару.
При работе необходимо соблюдать правила безопасности: во время замеса не следует наклоняться над дежой, брать пробу теста, а также откатывать дежу или снимать резервуар при включенном электродвигателе.
После окончания работы рабочую камеру и месильные лопасти тщательно промывают и насухо вытирают, а корпус очищают от мучной пыли и протирают влажной тканью.
Сравнительная характеристика тестомесильных машин
Вопрос 47. Производственная ситуация. Машина ММУ – 2000 при нажатии на кнопку «Пуск» не выключается, горит аварийная лампочка, причина? Способ устранения
В данной ситуации автоматика машины сигнализирует о серьезной неисправности. Необходимо немедленно отключить машину от источника электрического тока. Затем произвести осмотр с целью проверки всех рабочих частей машины, датчиков, а также наличия уровня воды и моющих жидкостей. В случае если невозможно определить неисправность при осмотре необходимо вызвать специалиста по ремонту машин данного типа. До его приходы и выявления причины не исправности самостоятельно пытаться запустить машину в работу категорически запрещено.
Литература
1. М.А. Богданова, З.М. Смирнова, Г.А. Богданов «Оборудование предприятий общественного питания» из. 2-е, Москва 1986 г.
2. М.А. Богданова, З.М. Смирнова, Г.А. Богданов «Оборудование предприятий общественного питания» из. 3-е, Москва 1991 г.
3. В.П. Золин «Технологическое оборудование общественного питания» 2-е изд. Москва 2000 г.
Классификация автомобилей
По назначению автомобили разделяются на транспортные, специальные и гоночные.
Транспортные автомобили служат для перевозки грузов и пассажировПассажир — тот, кто совершает поездку в транспортном средстве. Специальные автомобили имеют постоянно смонтированное оборудование или установки и применяются для различных целей (пожарные и коммунальные автомобили, автолавки, автокраны и т. п.). Гоночные автомобили предназначаются для спортивных соревнований, в том числе для установления рекордов скорости (рекордно-гоночные автомобили).
Транспортные автомобили в свою очередь делятся на легковые, грузовые и автобусыАвтобус (от Автомобиль и Омнибус) — автомобиль общественного пользования, рассчитанный на поездку 9 и более пассажиров. Первые автобусы появились в начале 20 века. Сравнительно широко распространились уже к началу 1-й мировой войны..
Легковые автомобили имеют вместимость от 2 до 8 человек. Они выпускаются с закрытыми (седанСедан (происхождение термина неизвестно, обычно связывают с названием французского города Седан) — название кузова легкового автомобиля, имеющего 4 двери и не менее двух рядов сидений без перегородки между ними. и лимузинЛимузин (французское limousine, от названия исторической области Лимузен) — название кузова легкового автомобиля, имеющего жёсткую остеклённую перегородку, отделяющую переднее сиденье от остальной части пассажирского помещения. Кузова типа лимузин применяются только на больших автомобилях высокого класса.), открытыми (фаэтонФаэтон (французское phaeton, от имени греческого мифологического героя Фаэтона —
1) конная коляска с открывающимся верхом.
2) Кузов легкового автомобиля с убирающимся верхом и съёмными верхними боковинами. Фаэтон может быть 2-или 4-дверным, с 2–3 рядами сидений. Убирающийся верх из мягкого материала (брезент, синтетическая ткань) натягивается на складывающийся каркас.) и открывающимися (кабриолетКабриолет — кузов легкового автомобиля с откидывающимся мягким тентом; имеет разновидности: кабриолет-купе с двумя боковыми дверями и 4-дверный кабриолет-седан.) кузовами. Грузовые автомобили оборудованы кузовом для перевозки груза, грузоподъёмностьГрузоподъёмност транспортного средства (подъемного крана, автомобиля и т. д.) — максимальная масса груза, которую оно способно в определенных условиях в один прием поднять, переместить или перевезти. их от 0,25 до 100 тонн. Грузовые автомобили без кузова или с небольшим кузовом, предназначенным для балласта, приспособленные для буксировки прицепных систем, называются авто-тягачами, они бывают седельные (для полуприцепов) и буксирные (для прицепов). Автомобиль или авто-тягач вместе с прицепной системой (прицепПрицеп — безмоторное колёсное транспортное средство, буксируемое тягачом (автомобиль, трактор). Обычный прцеп оборудуется закрытым кузовом или бортовой платформой; на специализированный прцеп устанавливают кузов для перевозки определённых грузов., полуприцеп, прицеп-роспуск, прицеп-тяжеловоз) образуют автомобильный поезд.
Автобусы, имеющие кузов вместимостью более 8 человек, подразделяются на городские, пригородные, междугородные (туристские), местного сообщения и др.
По проходимости автомобили разделяются на дорожные, внедорожные (карьерные) и автомобили повышенной и высокой проходимости. Дорожные предназначены для эксплуатации по общей сети автомобильных дорог. Внедорожные, имеющие увеличенные габаритные размеры и осевые нагрузки, могут использоваться только на специальных дорогах, например в карьерах. Автомобили повышенной и высокой проходимости рассчитаны на работу в тяжёлых дорожных условиях и по бездорожью. Основной вид таких автомобилей — колёсные полноприводные (т. е. имеющие приводПривод — устройство для приведения в действие машин. Состоит из двигателя, силовой передачи и системы управления. Различают приводы групповой (для нескольких машин или рабочих органов) и индивидуальный (для отдельной машины или для каждого рабочего органа). ко всем колёсам).
Кроме колёсных, различают ещё следующие автомобили высокой проходимости: колёсно-гусеничные со сменными гусеничными движителями или колёсами; полугусеничные, имеющие одновременно гусеничные движители и колёса; снегоходы с движителями в виде широких гусениц или шнеков; автомобили на пневмокатках; амфибииАмфибия — автомобиль, способный передвигаться по суше и воде, с водонепроницаемым кузовом, гребным винтом или водометным движителем, водным рулем. — колёсные автомобили с водонепроницаемым кузовом и дополнительным движителем в виде гребного винтаВинт (польское gwint, от немецкого Gewinde — нарезка, резьба):
1) крепежная деталь — стержень с головкой (обычно имеет шлиц под отвертку) и резьбой.
2) Винт ходовой — ведущее звено в винтовой передаче.
3) Винт лопастной (воздушный, гребной) — вал с винтовыми лопастями, обеспечивающий движение самолета, вертолета, судна.; автомобили на воздушной подушке, приводимые в движение тяговым воздушным винтом или реакцией направляемой назад струи воздуха от компрессораКомпрессор — устройство для сжатия и подачи какого-либо газа под давлением не ниже 115 кПа. По принципу действия компрессоры аналогичны соответствующим насосам (напр., центробежный компрессор).; шагающие автомобили, передвигающиеся с помощью перемещающихся лыж.
Проходимость обычных дорожных автомобилей может быть существенно улучшена установкой на их задние ведущие колёса арочных шин с очень широким профилем и высокими грунтозацепами.
4 типа классификационных задач в машинном обучении
Последнее обновление 19 августа 2020 г.
Машинное обучение — это область исследований, которая занимается алгоритмами, которые учатся на примерах.
Классификация — это задача, которая требует использования алгоритмов машинного обучения, которые учатся назначать метку класса примерам из предметной области. Простой для понимания пример — это классификация писем как « спам » или « не спам ».
Существует множество различных типов задач классификации, с которыми вы можете столкнуться в машинном обучении, и специальные подходы к моделированию, которые можно использовать для каждой из них.
В этом руководстве вы познакомитесь с различными типами прогнозного моделирования классификации в машинном обучении.
После прохождения этого руководства вы будете знать:
- Классификационное прогнозирующее моделирование включает присвоение метки класса входным примерам.
- Двоичная классификация относится к предсказанию одного из двух классов, а мультиклассовая классификация предполагает предсказание одного из более чем двух классов.
- Классификация с несколькими метками включает в себя прогнозирование одного или нескольких классов для каждого примера, а несбалансированная классификация относится к задачам классификации, в которых распределение примеров по классам неодинаково.
Начните свой проект с моей новой книги «Мастерство машинного обучения с Python», включая пошаговых руководств и файлов исходного кода Python для всех примеров.
Приступим.
Типы классификации в машинном обучении
Фото Рэйчел, некоторые права защищены.
Обзор учебного пособия
Это руководство разделено на пять частей; их:
- Классификация Прогнозное моделирование
- Двоичная классификация
- Мультиклассовая классификация
- Классификация по нескольким этикеткам
- Несбалансированная классификация
Классификация Прогнозное моделирование
В машинном обучении классификация относится к задаче прогнозного моделирования, когда метка класса прогнозируется для данного примера входных данных.
Примеры проблем классификации:
- Рассмотрим пример, классифицируйте, является это спам или нет.
- Дан рукописный символ, классифицируйте его как один из известных символов.
- С учетом недавнего поведения пользователей, классифицировать как отток или нет.
С точки зрения моделирования для классификации требуется обучающий набор данных с множеством примеров входных и выходных данных, из которых можно учиться.
Модель будет использовать обучающий набор данных и вычислить, как лучше всего сопоставить примеры входных данных с конкретными метками классов.Таким образом, обучающий набор данных должен быть достаточно репрезентативным для проблемы и иметь много примеров каждой метки класса.
Метки классов часто представляют собой строковые значения, например « спам », « не спам » и должны быть сопоставлены с числовыми значениями перед предоставлением алгоритму моделирования. Это часто называют кодированием метки, когда каждой метке класса присваивается уникальное целое число, например « спам » = 0, « без спама » = 1.
Существует множество различных типов алгоритмов классификации для моделирования задач прогнозного моделирования классификации.
Нет хорошей теории о том, как отображать алгоритмы на типы задач; вместо этого, как правило, рекомендуется, чтобы практикующий проводил контролируемые эксперименты и выяснял, какой алгоритм и его конфигурация дают наилучшие результаты для данной задачи классификации.
Алгоритмы прогнозного моделирования классификации оцениваются на основе их результатов. Точность классификации — это популярный показатель, используемый для оценки производительности модели на основе предсказанных меток классов.Точность классификации не идеальна, но это хорошая отправная точка для многих задач классификации.
Вместо меток классов для некоторых задач может потребоваться прогнозирование вероятности членства в классе для каждого примера. Это обеспечивает дополнительную неопределенность в прогнозе, который затем может интерпретировать приложение или пользователь. Популярной диагностикой для оценки предсказанных вероятностей является кривая ROC.
Есть, пожалуй, четыре основных типа задач классификации, с которыми вы можете столкнуться; их:
- Двоичная классификация
- Мультиклассовая классификация
- Классификация по нескольким этикеткам
- Несбалансированная классификация
Давайте рассмотрим каждый по очереди.
Бинарная классификация
Двоичная классификация относится к тем задачам классификации, которые имеют две метки класса.
Примеры включают:
- Обнаружение спама в электронной почте (спам или нет).
- Прогноз оттока (отток или нет).
- Прогноз конверсии (покупать или нет).
Обычно задачи двоичной классификации включают один класс, который является нормальным состоянием, и другой класс, который является ненормальным состоянием.
Например, « не спам, » — нормальное состояние, а « спам » — ненормальное состояние.Другой пример: « рак не обнаружен » — это нормальное состояние задачи, которая включает медицинский тест, а « рак обнаружен » — ненормальное состояние.
Классу для нормального состояния присваивается метка класса 0, а классу с ненормальным состоянием назначается метка класса 1.
Обычно для моделирования задачи двоичной классификации используется модель, которая предсказывает распределение вероятностей Бернулли для каждого примера.
Распределение Бернулли — это дискретное распределение вероятностей, которое охватывает случай, когда событие будет иметь двоичный исход как 0 или 1.Для классификации это означает, что модель предсказывает вероятность принадлежности примера к классу 1 или ненормальному состоянию.
Популярные алгоритмы, которые можно использовать для двоичной классификации, включают:
- Логистическая регрессия
- k-Ближайшие соседи
- Деревья решений
- Машина опорных векторов
- Наивный Байес
Некоторые алгоритмы специально разработаны для двоичной классификации и изначально не поддерживают более двух классов; примеры включают логистическую регрессию и машины опорных векторов.
Далее, давайте внимательнее рассмотрим набор данных, чтобы развить интуицию при решении задач двоичной классификации.
Мы можем использовать функцию make_blobs () для создания набора данных синтетической двоичной классификации.
В приведенном ниже примере создается набор данных из 1000 примеров, которые принадлежат одному из двух классов, каждый с двумя входными объектами.
# пример задачи бинарной классификации из импорта numpy, где из коллекций счетчик импорта из склеарна.наборы данных импортируют make_blobs из matplotlib import pyplot # определить набор данных X, y = make_blobs (n_samples = 1000, центры = 2, random_state = 1) # суммировать фигуру набора данных печать (X.shape, y.shape) # суммировать наблюдения по меткам класса counter = Counter (y) печать (счетчик) # подвести итоги первых нескольких примеров для i в диапазоне (10): print (X [i], y [i]) # рисуем набор данных и раскрашиваем метку по классам для метки _ в counter.items (): row_ix = where (y == label) [0] пиплот.разброс (X [row_ix, 0], X [row_ix, 1], label = str (label)) pyplot.legend () pyplot.show ()
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 18 19 20 21 | # пример задачи двоичной классификации из импорта numpy, где из импорта коллекций Counter из sklearn.datasets import make_blobs from matplotlib import pyplot # define dataset X, y = make_blobs (n_samples = 1000, center = 2, random_state = 1) # summarize dataset shape print (X.shape). shape) # суммировать наблюдения по метке класса counter = Counter (y) print (counter) # суммировать первые несколько примеров для i в диапазоне (10): print (X [i], y [i]) # построить набор данных и раскрасить метку по классам для метки, _ в счетчике.items (): row_ix = where (y == label) [0] pyplot.scatter (X [row_ix, 0], X [row_ix, 1], label = str (label)) pyplot.legend () pyplot.show () |
При выполнении примера сначала суммируется созданный набор данных, показывающий 1000 примеров, разделенных на входные ( X ) и выходные ( y ) элементы.
Затем суммируется распределение меток классов, показывая, что экземпляры принадлежат либо классу 0, либо классу 1, и что в каждом классе имеется 500 примеров.
Затем суммируются первые 10 примеров в наборе данных, показывая, что входные значения являются числовыми, а целевые значения — целыми числами, которые представляют членство в классе.
(1000, 2) (1000,) Счетчик ({0: 500, 1: 500}) [-3,05837272 4,48825769] 0 [-8.60973869 -3.72714879] 1 [1.37129721 5.23107449] 0 [-9,333 -2,9544469] 1 [-11,57178593 -3,85275513] 1 [-11,42257341 -4,85679127] 1 [-10,44518578 -3,76476563] 1 [-10.44603561 -3,26065964] 1 [-0,61947075 3,48804983] 0 [-10.
591 -4.5772537] 1
(1000, 2) (1000,) Счетчик ({0: 500, 1: 500}) [-3.05837272 4.48825769] 0 [-8.60973869 -3.72714879] 123 1 [1.3 5,23107449] 0 [-9,333 -2,9544469] 1 [-11,57178593 -3,85275513] 1 [-11,42257341 -4,85679127] 1 [-10.44518578 -3.76476563] 1 [-10.44603561 -3.26065964] 1 [-0.61947075 3.48804983] 0 [-10. 591 -4.5772537] 1 |
Наконец, для входных переменных в наборе данных создается диаграмма рассеяния, и точки окрашиваются в соответствии со значением их класса.
Мы видим два различных кластера, которые, как мы могли ожидать, легко различить.
Точечная диаграмма набора данных двоичной классификации
Мультиклассовая классификация
Мультиклассовая классификация относится к тем задачам классификации, которые имеют более двух меток классов.
Примеры включают:
- Классификация лиц.
- Классификация видов растений.
- Оптическое распознавание символов.
В отличие от бинарной классификации, мультиклассовая классификация не имеет понятия нормальных и аномальных результатов. Вместо этого примеры классифицируются как принадлежащие к одному из ряда известных классов.
Для некоторых задач количество меток классов может быть очень большим. Например, модель может предсказать фотографию как принадлежащую одному из тысяч или десятков тысяч лиц в системе распознавания лиц.
Задачи, связанные с предсказанием последовательности слов, например модели перевода текста, также могут считаться особым типом мультиклассовой классификации. Каждое слово в последовательности слов, которые должны быть предсказаны, включает в себя классификацию на несколько классов, где размер словаря определяет количество возможных классов, которые могут быть предсказаны, и может составлять десятки или сотни тысяч слов.
Обычно для моделирования задачи классификации нескольких классов используется модель, которая предсказывает распределение вероятностей Мультинулли для каждого примера.
Распределение Мультинулли — это дискретное распределение вероятностей, которое охватывает случай, когда событие будет иметь категориальный исход, например K в {1, 2, 3,…, K }. Для классификации это означает, что модель предсказывает вероятность принадлежности примера к каждой метке класса.
Многие алгоритмы, используемые для двоичной классификации, могут использоваться для классификации нескольких классов.
Популярные алгоритмы, которые можно использовать для мультиклассовой классификации, включают:
- к-ближайшие соседи.
- Деревья решений.
- Наивный Байес.
- Случайный лес.
- Повышение градиента.
Алгоритмы, разработанные для двоичной классификации, могут быть адаптированы для использования в мультиклассовых задачах.
Это включает в себя использование стратегии подбора нескольких моделей бинарной классификации для каждого класса по сравнению со всеми другими классами (называемых «один против остальных») или одной модели для каждой пары классов (называемой «один против одного»).
- Один против остальных : Подобрать одну бинарную модель классификации для каждого класса vs.все остальные классы.
- Один против одного : Подберите одну модель бинарной классификации для каждой пары классов.
Алгоритмы двоичной классификации, которые могут использовать эти стратегии для мультиклассовой классификации, включают:
- Логистическая регрессия.
- Машина опорных векторов.
Далее давайте более подробно рассмотрим набор данных, чтобы развить интуицию для решения задач классификации нескольких классов.
Мы можем использовать функцию make_blobs () для создания синтетического набора данных классификации нескольких классов.
В приведенном ниже примере создается набор данных из 1000 примеров, которые принадлежат одному из трех классов, каждый с двумя входными объектами.
# пример задачи мультиклассовой классификации из импорта numpy, где из коллекций счетчик импорта из sklearn.datasets импортировать make_blobs из matplotlib import pyplot # определить набор данных X, y = make_blobs (n_samples = 1000, центры = 3, random_state = 1) # суммировать фигуру набора данных print (X.shape, y.форма) # суммировать наблюдения по меткам класса counter = Counter (y) печать (счетчик) # подвести итоги первых нескольких примеров для i в диапазоне (10): print (X [i], y [i]) # рисуем набор данных и раскрашиваем метку по классам для метки _ в counter.items (): row_ix = where (y == label) [0] pyplot.scatter (X [row_ix, 0], X [row_ix, 1], label = str (label)) pyplot.legend () pyplot.show ()
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 18 19 20 21 | # пример задачи классификации нескольких классов из импорта numpy, где из импорта коллекций Counter из sklearn.datasets import make_blobs from matplotlib import pyplot # define dataset X, y = make_blobs (n_samples = 1000, center = 3, random_state = 1) # summarize dataset shape print (X.shape). shape) # суммировать наблюдения по метке класса counter = Counter (y) print (counter) # суммировать первые несколько примеров для i в диапазоне (10): print (X [i], y [i]) # построить набор данных и раскрасить метку по классам для метки, _ в счетчике.items (): row_ix = where (y == label) [0] pyplot.scatter (X [row_ix, 0], X [row_ix, 1], label = str (label)) pyplot.legend () pyplot.show () |
При выполнении примера сначала суммируется созданный набор данных, показывающий 1000 примеров, разделенных на входные ( X ) и выходные ( y ) элементы.
Затем суммируется распределение меток классов, показывающее, что экземпляры принадлежат классу 0, классу 1 или классу 2 и что в каждом классе имеется примерно 333 примера.
Затем суммируются первые 10 примеров в наборе данных, показывающие, что входные значения являются числовыми, а целевые значения — целыми числами, которые представляют членство в классе.
(1000, 2) (1000,) Счетчик ({0: 334, 1: 333, 2: 333}) [-3,05837272 4,48825769] 0 [-8.60973869 -3.72714879] 1 [1.37129721 5.23107449] 0 [-9,333 -2,9544469] 1 [-8,63895561 -8,05263469] 2 [-8,48974309 -9,05667083] 2 [-7,51235546 -7,96464519] 2 [-7.51320529 -7,46053919] 2 [-0,61947075 3,48804983] 0 [-10.
591 -4.5772537] 1
(1000, 2) (1000,) Счетчик ({0: 334, 1: 333, 2: 333}) [-3.05837272 4.48825769] 0 [-8.60973869 -3.72714879] 1 [1,37129721 5,23107449] 0 [-9,333 -2,9544469] 1 [-8,63895561 -8,05263469] 2 [-8,48974309 -9,05667083] 2 [-7.51235546 -7,96464519] 2 [-7,51320529 -7,46053919] 2 [-0,61947075 3,48804983] 0 [-10, 591 -4,5772537] 1 |
Наконец, для входных переменных в наборе данных создается диаграмма рассеяния, и точки окрашиваются в соответствии со значением их класса.
Мы видим три отдельных кластера, которые, как мы могли ожидать, будет легко различить.
Точечная диаграмма набора данных мультиклассовой классификации
Классификация нескольких этикеток
Классификация с несколькими метками относится к тем задачам классификации, которые имеют две или более меток классов, где одна или несколько меток классов могут быть предсказаны для каждого примера.
Рассмотрим пример классификации фотографий, где данная фотография может иметь несколько объектов в сцене, а модель может предсказать присутствие нескольких известных объектов на фотографии, например « велосипед », « яблоко », «». человек и др.
В этом отличие от бинарной классификации и мультиклассовой классификации, где для каждого примера прогнозируется одна метка класса.
Распространено моделирование задач классификации с несколькими метками с помощью модели, которая прогнозирует несколько выходных данных, причем для каждого выхода прогнозируется как распределение вероятностей Бернулли.По сути, это модель, которая делает несколько прогнозов двоичной классификации для каждого примера.
Алгоритмы классификации, используемые для двоичной или мультиклассовой классификации, не могут использоваться напрямую для классификации по нескольким меткам. Могут использоваться специализированные версии стандартных алгоритмов классификации, так называемые версии алгоритмов с несколькими метками, в том числе:
- Дерево принятия решений с несколькими метками
- Случайные леса с несколькими метками
- Повышение градиента с несколькими этикетками
Другой подход — использовать отдельный алгоритм классификации для прогнозирования меток для каждого класса.
Далее, давайте более подробно рассмотрим набор данных, чтобы развить интуицию для задач классификации с несколькими метками.
Мы можем использовать функцию make_multilabel_classification () для создания синтетического набора данных классификации с несколькими метками.
В приведенном ниже примере создается набор данных из 1000 примеров, каждый с двумя входными объектами. Есть три класса, каждый из которых может иметь одну из двух меток (0 или 1).
# пример задачи классификации с несколькими метками из склеарна.наборы данных импорт make_multilabel_classification # определить набор данных X, y = make_multilabel_classification (n_samples = 1000, n_features = 2, n_classes = 3, n_labels = 2, random_state = 1) # суммировать фигуру набора данных печать (X.shape, y.shape) # подвести итоги первых нескольких примеров для i в диапазоне (10): print (X [i], y [i])
# пример задачи классификации с несколькими ярлыками из sklearn.datasets import make_multilabel_classification # define dataset X, y = make_multilabel_classification (n_samples = 1000, n_features = 2, n_ random_classes = 3 1) # форма суммирования набора данных print (X.shape, y.shape) # резюмируем первые несколько примеров для i в диапазоне (10): print (X [i], y [i]) |
При выполнении примера сначала суммируется созданный набор данных, показывающий 1000 примеров, разделенных на входные ( X ) и выходные ( y ) элементы.
Затем суммируются первые 10 примеров в наборе данных, показывающие, что входные значения являются числовыми, а целевые значения — целыми числами, которые представляют принадлежность к метке класса.
(1000, 2) (1000, 3) [18. 35.] [1 1 1] [22. 33.] [1 1 1] [26. 36.] [1 1 1] [24. 28.] [1 1 0] [23. 27.] [1 1 0] [15. 31.] [0 1 0] [20. 37.] [0 1 0] [18. 31.] [1 1 1] [29. 27.] [1 0 0] [29. 28.] [1 1 0]
(1000, 2) (1000, 3) [18. 35.] [1 1 1] [22. 33.] [1 1 1] [26. 36.] [1 1 1] [24.28.] [1 1 0] [23. 27.] [1 1 0] [15. 31.] [0 1 0] [20. 37.] [0 1 0] [18. 31.] [1 1 1] [29. 27.] [1 0 0] [29. 28.] [1 1 0] |
Несбалансированная классификация
Несбалансированная классификация относится к задачам классификации, в которых количество примеров в каждом классе распределяется неравномерно.
Обычно задачи несбалансированной классификации представляют собой задачи двоичной классификации, в которых большинство примеров в обучающем наборе данных относятся к нормальному классу, а меньшая часть примеров относится к ненормальному классу.
Примеры включают:
- Обнаружение мошенничества.
- Обнаружение выбросов.
- Медицинские диагностические тесты.
Эти проблемы моделируются как задачи двоичной классификации, хотя могут потребовать специальных методов.
Специализированные методы могут использоваться для изменения состава выборок в наборе обучающих данных путем недостаточной выборки класса большинства или передискретизации класса меньшинства.
Примеры включают:
Могут использоваться специализированные алгоритмы моделирования, которые уделяют больше внимания классу меньшинства при подгонке модели к набору обучающих данных, например, чувствительные к стоимости алгоритмы машинного обучения.
Примеры включают:
Наконец, могут потребоваться альтернативные показатели производительности, поскольку сообщение о точности классификации может вводить в заблуждение.
Примеры включают:
- Точность.
- Напомним.
- F-Мера.
Далее давайте более подробно рассмотрим набор данных, чтобы развить интуицию в отношении несбалансированных проблем классификации.
Мы можем использовать функцию make_classification () для создания набора данных синтетической несбалансированной двоичной классификации.
В приведенном ниже примере создается набор данных из 1000 примеров, которые принадлежат одному из двух классов, каждый с двумя входными объектами.
# пример задачи несбалансированной двоичной классификации из импорта numpy, где из коллекций счетчик импорта из sklearn.datasets импортировать make_classification из matplotlib import pyplot # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 2, n_informative = 2, n_redundant = 0, n_classes = 2, n_clusters_per_class = 1, weights = [0.99,0.01], random_state = 1) # суммировать фигуру набора данных печать (X.shape, y.shape) # суммировать наблюдения по меткам класса counter = Counter (y) печать (счетчик) # подвести итоги первых нескольких примеров для i в диапазоне (10): print (X [i], y [i]) # рисуем набор данных и раскрашиваем метку по классам для метки _ в counter.items (): row_ix = where (y == label) [0] pyplot.scatter (X [row_ix, 0], X [row_ix, 1], label = str (label)) pyplot.legend () pyplot.show ()
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 18 19 20 21 | # пример задачи несбалансированной двоичной классификации из импорта numpy, где из импорта коллекций Counter из sklearn.наборы данных import make_classification из matplotlib import pyplot # define dataset X, y = make_classification (n_samples = 1000, n_features = 2, n_informative = 2, n_redundant = 0, n_classes = 2_, n_clights_clights, n_classes_ , 0,01], random_state = 1) # суммировать фигуру набора данных print (X.shape, y.shape) # суммировать наблюдения по метке класса counter = Counter (y) print (counter) # суммировать первые несколько примеров для i в диапазоне (10): print (X [i], y [i]) # построить набор данных и раскрасить метку по классам для метки, _ в счетчике.items (): row_ix = where (y == label) [0] pyplot.scatter (X [row_ix, 0], X [row_ix, 1], label = str (label)) pyplot.legend () pyplot.show () |
При выполнении примера сначала суммируется созданный набор данных, показывающий 1000 примеров, разделенных на входные ( X ) и выходные ( y ) элементы.
Затем суммируется распределение меток классов, показывающее серьезный дисбаланс классов с примерно 980 примерами, принадлежащими классу 0, и примерно 20 примерами, принадлежащими классу 1.
Затем суммируются первые 10 примеров в наборе данных, показывающие, что входные значения являются числовыми, а целевые значения — целыми числами, которые представляют членство в классе. В этом случае мы видим, что большинство примеров относятся к классу 0, как и ожидалось.
(1000, 2) (1000,) Счетчик ({0: 983, 1: 17}) [0,865 1,18613612] 0 [1,55110839 1,81032905] 0 [1.29361936 1.01094607] 0 [1.11988947 1.63251786] 0 [1.04235568 1.12152929] 0 [1.18114858 0,607] 0 [1.1365562 1.17652556] 0 [0,462
- 0,728] 0
[0,18315826 1,07141766] 0
[0,32411648 0,53515376] 0
- Классификационное прогнозирующее моделирование включает присвоение метки класса входным примерам.
- Двоичная классификация относится к предсказанию одного из двух классов, а мультиклассовая классификация предполагает предсказание одного из более чем двух классов.
- Классификация с несколькими метками включает в себя прогнозирование одного или нескольких классов для каждого примера, а несбалансированная классификация относится к задачам классификации, в которых распределение примеров по классам неодинаково.
Классификатор — это алгоритм, который используется для сопоставления входных данных с определенной категорией.
Модель классификации — Модель предсказывает или делает вывод о входных данных, предоставленных для обучения, она предсказывает класс или категорию данных.
Признак — Признак — это индивидуальное измеримое свойство наблюдаемого явления.
Двоичная классификация — это тип классификации с двумя результатами, например, истинным или ложным.
Мультиклассовая классификация — Классификация с более чем двумя классами, в мультиклассовой классификации каждый образец присваивается одной и только одной метке или цели.
Классификация по нескольким меткам — это тип классификации, при котором каждый образец назначается набору меток или целей.
Инициализировать — Назначить классификатор, который будет использоваться для
Обучить классификатор — Каждый классификатор в научном наборе использует метод соответствия (X, y), чтобы соответствовать модели для обучаем поезд X и обучаем метку y.
Прогнозировать цель — для немаркированного наблюдения X метод прогнозирования (X) возвращает прогнозируемую метку y.
Оценить — Это в основном означает оценку модели i.отчет о классификации, оценка точности и т. д.
Ленивые учащиеся — Ленивые учащиеся просто сохраняют данные обучения и ждут, пока не появятся данные тестирования. Классификация выполняется с использованием наиболее связанных данных в сохраненных обучающих данных. У них больше времени на предсказания, чем у активных учеников. Например, k-ближайший сосед, рассуждение на основе случая.
Активные ученики — Активные ученики создают модель классификации на основе заданных обучающих данных перед получением данных для прогнозов.Он должен иметь возможность придерживаться единственной гипотезы, которая будет работать для всего пространства. Из-за этого они тратят много времени на обучение и меньше времени на прогнозы. Например, дерево решений, наивный байесовский метод, искусственные нейронные сети.
Прогнозы заболеваний
Классификация документов
Фильтры спама
Анализ тональности
Промышленные приложения, такие как определение того, относится ли соискатель кредита к группе высокого или низкого риска
Для прогнозирования выхода из строя механических частей автомобильных двигателей
Прогнозирование оценок в социальных сетях
Показатели производительности
Анализ почерка
Раскрашивание черно-белых изображений
Процессы компьютерного зрения
Подписание фотографий на основе черт лица
Точность
Точность — это отношение правильно спрогнозированного наблюдения к общему количеству наблюдений
Истинно положительное: количество правильных прогнозов о том, что возникновение является положительным.
Истинно отрицательное: количество правильных прогнозов о том, что возникновение отрицательное.
F1- Оценка
- Точность и отзыв
- Точность — это доля релевантных экземпляров среди извлеченных экземпляров, а отзыв — это доля соответствующих экземпляров, которые были извлечены из общего числа экземпляры.В основном они используются как мера релевантности.
Прочитать данные
Создать зависимые и независимые данные наборы на основе наших зависимых и независимых функций
Разделение данных на наборы для обучения и тестирования
Обучите модель, используя различные алгоритмы, такие как KNN, дерево решений, SVM и т. д.
Оцените классификатор
Выберите классификатор с максимальной точностью.
(1000, 2) (1000,) Счетчик ({0: 983, 1: 17}) [0,865 1,18613612] 0 [1,55110839 1,81032905] 0 [1,29361936] 1,0 [1.11988947 1.63251786] 0 [1.04235568 1.12152929] 0 [1.18114858 0,607] 0 [1,1365562 1,17652556] 0 [0,462
[0,18315826 1,07141766] 0 [0,32411648 0,53515376] 0 |
Наконец, для входных переменных в наборе данных создается диаграмма рассеяния, и точки окрашиваются в соответствии со значением их класса.
Мы можем видеть один главный кластер для примеров, которые принадлежат классу 0, и несколько разрозненных примеров, которые принадлежат классу 1. Интуиция подсказывает, что наборы данных с этим свойством несбалансированных меток классов сложнее моделировать.
Точечная диаграмма набора данных несбалансированной двоичной классификации
Дополнительная литература
Этот раздел предоставляет дополнительные ресурсы по теме, если вы хотите углубиться.
Сводка
В этом руководстве вы открыли для себя различные типы прогнозного моделирования классификации в машинном обучении.
В частности, вы выучили:
Есть вопросы?
Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Откройте для себя быстрое машинное обучение на Python!
Разрабатывайте свои собственные модели за считанные минуты
… всего несколько строк кода scikit-learn
Узнайте, как это сделать, в моей новой электронной книге:
Мастерство машинного обучения с Python
Охватывает руководств для самостоятельного изучения и сквозных проектов , например:
Загрузка данных , визуализация , моделирование , настройка и многое другое…
Наконец-то доведите машинное обучение до
Ваши собственные проекты
Пропустить академики. Только результаты.
Посмотрите, что внутри Классификацияв машинном обучении | Алгоритмы классификации
Классификация в машинном обучении и статистике — это подход к обучению с учителем, при котором компьютерная программа учится на предоставленных ей данных и делает новые наблюдения или классификации. В этой статье мы подробно узнаем о классификации в машинном обучении.В этом блоге рассматриваются следующие темы:
Что такое классификация в машинном обученииКлассификация — это процесс категоризации заданного набора данных по классам. Он может выполняться как для структурированных, так и для неструктурированных данных. Процесс начинается с прогнозирования класса заданных точек данных. Классы часто называют целевыми, метками или категориями.
Классификационное прогнозирующее моделирование — это задача аппроксимации функции отображения входных переменных в дискретные выходные переменные.Основная цель — определить, в какой класс / категорию попадут новые данные.
Попробуем разобраться в этом на простом примере.
Обнаружение болезней сердца может быть определено как проблема классификации, это бинарная классификация, поскольку может быть только два класса, то есть с сердечным заболеванием или без сердечного заболевания. Классификатору в этом случае нужны обучающие данные, чтобы понять, как заданные входные переменные связаны с классом. И как только классификатор будет правильно обучен, его можно будет использовать для определения наличия сердечного заболевания у конкретного пациента.
Поскольку классификация — это тип обучения с учителем, даже целевые объекты также получают входные данные. Познакомимся с классификацией в терминологии машинного обучения.
Классификационные термины в машинном обученииТипы учащихся в классификации
Постройте карьеру в области искусственного интеллекта с нашим дипломом аспиранта по курсам AI ML.
Алгоритмы классификацииВ машинном обучении классификация — это концепция контролируемого обучения, которая в основном разбивает набор данных на классы.Наиболее распространенные проблемы классификации — это распознавание речи, распознавание лиц, распознавание рукописного ввода, классификация документов и т. Д. Это может быть либо проблема двоичной классификации, либо проблема нескольких классов. Существует множество алгоритмов машинного обучения для классификации в машинном обучении. Давайте посмотрим на эти алгоритмы классификации в машинном обучении.
Логистическая регрессияЭто алгоритм классификации в машинном обучении, который использует одну или несколько независимых переменных для определения результата.Результат измеряется дихотомической переменной, означающей , у него будет только два возможных результата .
Цель логистической регрессии — найти наиболее подходящую взаимосвязь между зависимой переменной и набором независимых переменных. Он лучше, чем другие алгоритмы двоичной классификации, такие как ближайший сосед, поскольку количественно объясняет факторы, приводящие к классификации.
Преимущества и недостатки
Логистическая регрессия специально предназначена для классификации, она полезна для понимания того, как набор независимых переменных влияет на результат зависимой переменной.
Основным недостатком алгоритма логистической регрессии является то, что он работает только тогда, когда прогнозируемая переменная является двоичной, он предполагает, что данные не содержат пропущенных значений, и предполагает, что предикторы независимы друг от друга.
Примеры использования
Узнайте больше о логистической регрессии с помощью Python здесь.
Наивный байесовский классификаторЭто алгоритм классификации, основанный на теореме Байеса , которая дает предположение о независимости предсказателей.Проще говоря, наивный байесовский классификатор предполагает, что наличие определенной функции в классе не связано с наличием какой-либо другой функции.
Даже если признаки зависят друг от друга, все эти свойства независимо вносят вклад в вероятность. Наивную байесовскую модель легко создать, и она особенно полезна для сравнительно больших наборов данных. Известно, что даже при упрощенном подходе наивный байесовский метод превосходит большинство методов классификации в машинном обучении. Ниже приводится теорема Байеса для реализации наивной теоремы Байеса.
Преимущества и недостатки
Наивный байесовский классификатор требует небольшого количества обучающих данных для оценки параметров, необходимых для получения результатов. По своей природе они чрезвычайно быстры по сравнению с другими классификаторами.
Единственный недостаток — это плохая оценка.
Примеры использования
Узнайте больше о наивном байесовском классификаторе здесь.
Стохастический градиентный спускЭто очень эффективный и простой подход для подбора линейных моделей. Стохастический градиентный спуск особенно полезен, когда образец данных находится в большом количестве . Он поддерживает различные функции потерь и штрафы за классификацию.
Стохастический градиентный спуск относится к вычислению производной из каждого экземпляра обучающих данных и немедленному вычислению обновления.
Преимущества и недостатки
Единственным преимуществом является простота реализации и эффективность, тогда как основной недостаток стохастического градиентного спуска заключается в том, что он требует ряда гиперпараметров и чувствителен к масштабированию функций.
Сценарии использования
K-ближайший соседЭто алгоритм ленивого обучения, который хранит все экземпляры, соответствующие обучающим данным, в n-мерном пространстве . Это алгоритм ленивого обучения , поскольку он не фокусируется на построении общей внутренней модели, вместо этого он работает на хранении экземпляров обучающих данных.
Классификация вычисляется простым большинством голосов k ближайших соседей каждой точки.Он контролируется и берет набор помеченных точек и использует их для маркировки других точек. Чтобы пометить новую точку, он смотрит на помеченные точки, ближайшие к этой новой точке, также известные как ее ближайшие соседи. В нем голосуют эти соседи, поэтому какой бы ярлык ни было у большинства соседей, это будет ярлык для новой точки. «K» — это количество проверяемых соседей.
Преимущества и недостатки
Этот алгоритм довольно прост в реализации и устойчив к зашумленным обучающим данным.Даже если обучающие данные большие, это довольно эффективно. Единственный недостаток алгоритма KNN заключается в том, что нет необходимости определять значение K, а стоимость вычислений довольно высока по сравнению с другими алгоритмами.
Варианты использования
Узнайте больше об алгоритме ближайшего соседа по K здесь
Дерево решенийАлгоритм дерева решений строит модель классификации в виде древовидной структуры . В нем используются правила «если-то», которые являются в равной степени исчерпывающими и взаимоисключающими с точки зрения классификации.Процесс продолжается с разбиением данных на более мелкие структуры и, в конечном итоге, связывает их с инкрементным деревом решений. Окончательная структура выглядит как дерево с узлами и листьями. Правила изучаются последовательно с использованием обучающих данных по одному. Каждый раз при изучении правила кортежи, покрывающие правила, удаляются. Процесс продолжается на обучающей выборке до тех пор, пока не будет достигнута точка завершения.
Дерево строится с использованием нисходящего рекурсивного подхода «разделяй и властвуй».Узел решения будет иметь две или более ветвей, а лист представляет классификацию или решение. Самый верхний узел в дереве решений, который соответствует лучшему предиктору, называется корневым узлом, и самое лучшее в дереве решений — то, что оно может обрабатывать как категориальные, так и числовые данные.
Преимущества и недостатки
Дерево решений дает преимущество простоты для понимания и визуализации, а также требует очень небольшой подготовки данных. Недостаток, который следует за деревом решений, заключается в том, что оно может создавать сложные деревья, которые бот может эффективно классифицировать.Они могут быть довольно нестабильными, потому что даже простое изменение данных может помешать всей структуре дерева решений.
Примеры использования
Узнайте больше об алгоритме дерева решений здесь
Случайный лесСлучайные деревья решений или случайный лес — это метод обучения ансамбля для классификации, регрессии и т. Д. множество деревьев решений во время обучения и выводит класс, который является режимом классов или классификации или среднего прогноза (регрессии) отдельных деревьев.
Случайный лес — это метаоценка, которая помещает несколько деревьев в различные подвыборки наборов данных, а затем использует среднее значение для повышения точности предсказательной природы модели. Размер подвыборки всегда такой же, как и у исходного размера входных данных, но выборки часто рисуются с заменами.
Преимущества и недостатки
Преимущество случайного леса состоит в том, что он более точен, чем деревья решений, из-за уменьшения чрезмерной подгонки.Единственный недостаток классификаторов случайных лесов заключается в том, что они довольно сложны в реализации и работают довольно медленно при прогнозировании в реальном времени.
Сценарии использования
Узнайте больше об алгоритме случайного леса здесь.
Искусственные нейронные сетиНейронная сеть состоит из нейронов, расположенных в слоях , они принимают некоторый входной вектор и преобразуют его в выходной. В этом процессе каждый нейрон принимает входные данные и применяет к нему функцию, которая часто является нелинейной, а затем передает выходные данные на следующий уровень.
В общем, предполагается, что сеть имеет прямую связь, что означает, что блок или нейрон подает выходной сигнал на следующий уровень, но никакой обратной связи с предыдущим уровнем не происходит.
Взвешивание применяется к сигналам, проходящим от одного уровня к другому, и эти взвешивания настраиваются на этапе обучения для адаптации нейронной сети к любой постановке задачи.
Преимущества и недостатки
Он имеет высокую устойчивость к зашумленным данным и способен классифицировать необученные шаблоны, он лучше работает с непрерывными входами и выходами. Недостатком искусственных нейронных сетей является то, что они плохо интерпретируются по сравнению с другими моделями.
Сценарии использования
Подробнее об искусственных нейронных сетях
Машина опорных векторовМашина опорных векторов — это классификатор, который представляет обучающие данные в виде точек в пространстве , разделенных на категории максимально широким промежутком.Затем новые точки добавляются в пространство, предсказывая, в какую категорию они попадают и к какому пространству они будут принадлежать.
Преимущества и недостатки
Он использует подмножество обучающих точек в функции принятия решения, что делает его эффективным с точки зрения памяти и высокоэффективным в пространствах большой размерности. Единственным недостатком машины опорных векторов является то, что алгоритм не дает напрямую оценок вероятности.
Сценарии использования
Узнайте больше о машине поддержки векторов в python здесь
Оценка классификатораСамая важная часть после завершения любого классификатора — оценка для проверки его точности и эффективности.Есть много способов оценить классификатор. Давайте посмотрим на эти методы, перечисленные ниже.
Метод удержания
Это наиболее распространенный метод оценки классификатора. В этом методе данный набор данных делится на две части: тестовый и обучающий набор 20% и 80% соответственно.
Набор поездов используется для обучения данных, а невидимый набор тестов используется для проверки его предсказательной способности.
Перекрестная проверка
Избыточная подгонка — наиболее распространенная проблема, распространенная в большинстве моделей машинного обучения.K-кратная перекрестная проверка может быть проведена, чтобы убедиться, что модель вообще не переоборудована.
В этом методе набор данных случайным образом разбивается на k взаимоисключающих подмножеств, каждый из которых имеет одинаковый размер. Из них один остается для тестирования, а другие используются для обучения модели. Такой же процесс происходит для всех k складок.
Отчет о классификации
Отчет о классификации даст следующие результаты: это образец отчета о классификации классификатора SVM, использующего набор данных Cance_data.
Кривая ROC
Рабочие характеристики приемника или кривая ROC используется для визуального сравнения моделей классификации, которые показывают взаимосвязь между показателем истинных положительных и ложноположительных результатов. Площадь под кривой ROC является мерой точности модели.
Выбор алгоритма
Помимо описанного выше подхода, мы можем выполнить следующие шаги, чтобы использовать лучший алгоритм для модели
Хотя выбор оптимального алгоритма, подходящего для вашей модели, может занять больше времени, чем необходимо, точность — лучший способ сделать вашу модель эффективной.
Давайте взглянем на набор данных MNIST и воспользуемся двумя разными алгоритмами, чтобы проверить, какой из них лучше всего подходит для модели.
Пример использованияЧто такое MNIST?
Это набор из 70 000 маленьких рукописных изображений, помеченных соответствующей цифрой, которую они представляют.Каждое изображение имеет почти 784 функции, одна функция просто представляет плотность пикселей, а каждое изображение имеет размер 28 × 28 пикселей.
Мы сделаем предсказатель цифр, используя набор данных MNIST с помощью различных классификаторов.
Загрузка набора данных MNIST
from sklearn.datasets import fetch_openml
mnist = fetch_openml ('mnist_784')
печать (мнист)
Выход:
Изучение набора данных
импортировать matplotlib import matplotlib.pyplot как plt X, y = mnist ['данные'], mnist ['цель'] random_digit = X [4800] random_digit_image = random_digit.reshape (28,28) plt.imshow (random_digit_image, cmap = matplotlib.cm.binary, interpolation = "ближайший")
Вывод:
Разделение данных
Мы используем первые 6000 записей в качестве обучающих данных, размер набора данных составляет 70000 записей. Вы можете проверить, используя форму X и y. Итак, чтобы сделать память нашей модели эффективной, мы взяли только 6000 записей в качестве обучающего набора и 1000 записей в качестве тестового набора.
x_train, x_test = X [: 6000], X [6000: 7000] y_train, y_test = y [: 6000], y [6000: 7000]
Перемешивание данных
Чтобы избежать нежелательных ошибок, мы перемешали данные, используя массив numpy. Это в основном повышает эффективность модели.
импортировать numpy как np shuffle_index = np.random.permutation (6000) x_train, y_train = x_train [shuffle_index], y_train [shuffle_index]
Создание предиктора цифр с использованием логистической регрессии
y_train = y_train.astype (np.int8) y_test = y_test.astype (np.int8) y_train_2 = (y_train == 2) y_test_2 = (y_test == 2) печать (y_test_2)
Выход:
из sklearn.linear_model import LogisticRegression clf = логистическая регрессия (tol = 0,1) clf.fit (x_train, y_train_2) clf.predict ([random_digit])
Выход:
Перекрестная проверка
из sklearn.model_selection импорт cross_val_score a = cross_val_score (clf, x_train, y_train_2, cv = 3, scoring = "точность") а.иметь в виду()
Выход:
Создание предиктора с помощью машины опорных векторов
из sklearn import svm cls = svm.SVC () cls.fit (x_train, y_train_2) cls.predict ([random_digit])
Выход:
Перекрестная проверка
a = cross_val_score (cls, x_train, y_train_2, cv = 3, scoring = "точность") a.mean ()
Вывод:
В приведенном выше примере мы смогли создать предсказатель цифр.Поскольку мы прогнозировали, будет ли цифра 2 из всех записей в данных, мы получили ложь в обоих классификаторах, но перекрестная проверка показывает гораздо лучшую точность с классификатором логистической регрессии вместо машинного классификатора опорных векторов.
На этом мы подошли к концу статьи, в которой мы узнали о классификации в машинном обучении. Я надеюсь, что вы понимаете все, о чем вам рассказали в этом уроке.
Если вы нашли эту статью «Классификация в машинном обучении» релевантной, ознакомьтесь с лучшим курсом по машинному обучению от Edureka, надежной компании онлайн-обучения с сетью из более чем 250 000 довольных учеников по всему миру.
Мы здесь, чтобы помочь вам на каждом этапе вашего пути и составить учебную программу, предназначенную для студентов и профессионалов, которые хотят стать разработчиками Python. Курс разработан, чтобы дать вам фору в программировании на Python и обучить вас как основным, так и продвинутым концепциям Python, а также различным фреймворкам Python, таким как Django.
Если у вас возникнут какие-либо вопросы, не стесняйтесь задавать все свои вопросы в разделе комментариев «Классификация в машинном обучении», и наша команда будет рада ответить.
Классификация в машинном обучении | Лучшие классификационные модели
Обычная задача алгоритмов машинного обучения — распознавать объекты и иметь возможность разделить их на категории. Этот процесс называется классификацией, и он помогает нам разделить огромные объемы данных на дискретные значения, например: различные, такие как 0/1, Истина / Ложь или заранее определенный класс выходной метки.
Что такое контролируемое обучение?
Прежде чем мы углубимся в классификацию, давайте посмотрим, что такое контролируемое обучение.Предположим, вы пытаетесь изучить новую математическую концепцию и после решения проблемы можете обратиться к решениям, чтобы узнать, правы вы или нет. Как только вы будете уверены в своей способности решить конкретный тип проблемы, вы перестанете ссылаться на ответы и самостоятельно решите поставленные перед вами вопросы.
БЕСПЛАТНЫЙ курс по машинному обучению
Сделайте первый шаг к успеху в машинном обученииИменно так работает контролируемое обучение с моделями машинного обучения.При обучении с учителем модель учится на примере. Наряду с нашей входной переменной мы также даем нашей модели соответствующие правильные метки. Во время обучения модель смотрит, какая метка соответствует нашим данным, и, следовательно, может находить закономерности между нашими данными и этими метками.
Вот некоторые примеры контролируемого обучения:
- Классифицирует обнаружение спама, обучая модели того, какая почта является спамом, а не спамом.
- Распознавание речи: вы обучаете машину распознавать ваш голос.
- Распознавание объекта: машина показывает, как выглядит объект, и заставляет его выбирать этот объект среди других объектов.
Мы можем дополнительно разделить контролируемое обучение на следующие:
Рисунок 1: Подразделения контролируемого обучения
Что такое классификация?
Классификация определяется как процесс распознавания, понимания и группировки объектов и идей по заранее заданным категориям, также известным как «субпопуляции». С помощью этих предварительно категоризированных наборов данных для обучения классификация в программах машинного обучения использует широкий спектр алгоритмов для классификации будущих наборов данных по соответствующим категориям.
Алгоритмы классификации, используемые в машинном обучении, используют входные обучающие данные с целью прогнозирования вероятности того, что последующие данные попадут в одну из заранее определенных категорий. Одним из наиболее распространенных применений классификации является фильтрация электронных писем на «спам» или «не спам», как это используют ведущие современные поставщики услуг электронной почты.
Короче говоря, классификация — это форма «распознавания образов». Здесь алгоритмы классификации, применяемые к обучающим данным, находят тот же образец (аналогичные числовые последовательности, слова или настроения и т.п.) в будущих наборах данных.
Мы подробно рассмотрим алгоритмы классификации и узнаем, как программное обеспечение для анализа текста может выполнять такие действия, как анализ тональности, используемый для категоризации неструктурированного текста по полярности мнения (положительное, отрицательное, нейтральное и т. Д.).
Рисунок 2: Классификация овощей и бакалейных товаров
Классификация моделей
- Наивный байесовский алгоритм: Наивный байесовский алгоритм — это алгоритм классификации, который предполагает, что предикторы в наборе данных независимы.Это означает, что предполагается, что функции не связаны друг с другом. Например, если дан банан, классификатор увидит, что плод желтого цвета, имеет продолговатую форму, длинный и заостренный. Все эти особенности независимо друг от друга влияют на вероятность того, что это банан. Наивный Байес основан на теореме Байеса, которая имеет следующий вид:
Рисунок 3: Теорема Байеса
Где:
P (A | B) = как часто происходит, учитывая, что происходит B
P (A) = насколько вероятно, что произойдет A
P (B) = какова вероятность того, что произойдет B
P (B | A) = как часто происходит B, учитывая, что происходит A
- Деревья решений: Дерево решений — это алгоритм, который используется для визуального представления процесса принятия решений.Дерево решений можно составить, задав вопрос «да / нет» и разделив ответ, чтобы привести к другому решению. Вопрос находится в узле, и он помещает итоговые решения ниже на листьях. Изображенное ниже дерево используется, чтобы решить, можем ли мы играть в теннис.
Рисунок 4: Дерево решений
На приведенном выше рисунке, в зависимости от погодных условий, влажности и ветра, мы можем систематически решать, играть нам в теннис или нет.В деревьях решений все утверждения False лежат слева от дерева, а утверждения True разветвляются вправо. Зная это, мы можем составить дерево, которое имеет особенности в узлах и результирующие классы на листьях.
- K-Nearest Neighbour: K-Nearest Neighbor — это алгоритм классификации и прогнозирования, который используется для разделения данных на классы в зависимости от расстояния между точками данных. K-Nearest Neighbor предполагает, что точки данных, которые находятся рядом друг с другом, должны быть похожими, и, следовательно, точка данных, которая должна быть классифицирована, будет сгруппирована с ближайшим кластером.
Рисунок 5: Данные, подлежащие классификации
Рисунок 6: Классификация с использованием K-ближайших соседей
Оценка классификаторов
Чтобы оценить точность нашей модели классификатора, нам нужны некоторые меры точности. Чтобы узнать, насколько хорошо наши классификаторы предсказывают, используются следующие методы:
- Метод удержания: это один из наиболее распространенных методов оценки точности наших классификаторов.В этом методе мы разделяем данные на два набора: обучающий набор и тестовый набор. Обучающий набор показан нашей модели, и модель учится на данных в ней. Данные в наборе тестирования скрываются от модели, и после обучения модели набор тестирования используется для проверки ее точности. Обучающий набор будет иметь как функции, так и соответствующую метку, но тестовый набор будет иметь только функции, и модель должна будет предсказать соответствующую метку.
Прогнозируемые метки затем сравниваются с фактическими метками, и выясняется точность, видя, сколько меток получилось правильной.
- Смещение и отклонение: смещение — это разница между нашими фактическими и прогнозируемыми значениями. Предвзятость — это простые предположения, которые наша модель делает в отношении наших данных, чтобы иметь возможность прогнозировать новые данные. Это напрямую соответствует шаблонам, найденным в наших данных. Когда смещение велико, допущения, сделанные нашей моделью, слишком просты, модель не может уловить важные особенности наших данных, это называется недостаточным соответствием.
Рисунок 7: Смещение
Мы можем определить дисперсию как чувствительность модели к колебаниям данных.Наша модель может учиться на шуме. Это заставит нашу модель рассматривать тривиальные функции как важные. Когда дисперсия высока, наша модель захватит все особенности предоставленных ей данных, настроится на данные и очень хорошо прогнозирует их, но новые данные могут не иметь точно таких же характеристик, и модель не будет умеет очень хорошо предсказывать по нему. Мы называем это переоснащением.
Рисунок 8: Пример отклонения
- Точность и отзыв: точность используется для расчета способности модели правильно классифицировать значения.Он дается путем деления количества правильно классифицированных точек данных на общее количество классифицированных точек данных для этой метки класса.
Где:
TP = True Positives, когда наша модель правильно классифицирует точку данных по классу, к которому она принадлежит.
FP = Ложные срабатывания, когда модель ложно классифицирует точку данных.
Отзыв используется для расчета способности режима предсказывать положительные значения.Но: «Как часто модель предсказывает правильные положительные значения?». Он рассчитывается как отношение истинных положительных значений к общему количеству фактических положительных значений.
Ускорьте свою карьеру в области искусственного интеллекта и машинного обучения с помощью программы последипломного образования в области искусственного интеллекта и машинного обучения в Университете Пердью в сотрудничестве с IBM.
Заключение
В этой статье — все, что вам нужно знать о классификации в машинном обучении, мы рассмотрели, что такое контролируемое обучение и его подветвленную классификацию, а также узнали о некоторых обычно используемых классификационных моделях и о том, как спрогнозируйте точность этих моделей и посмотрите, идеально ли они обучены.Надеюсь, теперь вы знаете все, что вам нужно о классификации!
Была ли вам полезна эта статья по классификации? У вас есть к нам какие-либо сомнения или вопросы? Упомяните их в разделе комментариев к этой статье, и наши специалисты ответят на них как можно скорее!
Хотите стать инженером по машинному обучению? Пройдите курс машинного обучения Simplilearn и получите сертификат уже сегодня!
Полное руководство по классификации в машинном обучении
Введение
Машинное обучение связано с областью образования, связанной с алгоритмами, которая постоянно учится на различных примерах и затем применяет их к реальным задачам.Классификация — это задача машинного обучения, которая присваивает значение метки определенному классу, а затем может идентифицировать тот или иной конкретный тип. Самым простым примером может быть система фильтрации почтового спама, где можно классифицировать почту как «спам» или «не спам». Вы столкнетесь с несколькими типами задач классификации, и существуют некоторые конкретные подходы к типу модели, которые можно использовать для каждой задачи.
Классификация прогнозирующего моделирования в машинном обучении
Классификация обычно относится к любому типу проблемы, когда конкретный тип метки класса является результатом, который должен быть предсказан на основе заданного поля ввода данных.Вот некоторые типы классификационных испытаний:
- Отнесение писем к спаму или нет
- Классифицирует данный рукописный символ как известный или нет
- Классифицировать недавнее поведение пользователя как отток или нет
Для любой модели вам потребуется обучающий набор данных с множеством примеров входных и выходных данных, на основе которых модель будет обучаться сама. Данные обучения должны включать все возможные сценарии проблемы и иметь достаточно данных для каждой метки для правильного обучения модели.Метки классов часто возвращаются в виде строковых значений и, следовательно, должны быть закодированы в целое число, например, представляющее 0 для «спама» и 1 для «без спама».
Изображение 1
Не существует общей теории для лучшей модели, но ожидается, что нужно будет поэкспериментировать и выяснить, какой алгоритм и конфигурация приведут к наилучшей производительности для конкретной задачи. При классификационном прогнозном моделировании различные алгоритмы сравниваются с их результатами.Точность классификации — интересный показатель для оценки производительности любой модели на основе различных предсказанных меток классов. Точность классификации может быть не лучшим параметром, но это хорошая отправная точка для большинства задач классификации.
Вместо метки класса некоторые могут дать нам прогноз вероятности принадлежности к классу конкретного входа, и в таких случаях кривая ROC может быть полезным индикатором того, насколько точна одна модель. В основном существует 4 различных типа задач классификации, с которыми вы можете столкнуться в повседневных задачах.Как правило, различные типы прогнозных моделей в машинном обучении следующие:
- Двоичная классификация
- Классификация по нескольким этикеткам
- Мультиклассовая классификация
- Несбалансированная классификация
Мы рассмотрим их по очереди.
Бинарная классификация для машинного обучения
Бинарная классификация относится к тем задачам, которые могут выдавать любую из двух меток класса в качестве выходных данных.Как правило, одно считается нормальным состоянием, а другое — ненормальным. Следующие примеры помогут вам лучше их понять.
- Обнаружение спама в электронной почте: нормальное состояние — не спам, ненормальное состояние — спам
- Прогноз преобразования: нормальное состояние — не отток, ненормальное состояние — отток
- Прогноз конверсии: нормальное состояние — предмет куплен, ненормальное состояние — предмет не куплен
Вы также можете добавить пример того, что «Рак не обнаружен» как нормальное состояние, а «Рак обнаружен» — как ненормальное состояние.Обычно используется обозначение, что нормальному состоянию присваивается значение 0, а классу с ненормальным состоянием присваивается значение 1. Для каждого примера можно также создать модель, которая прогнозирует вероятность Бернулли для выходных данных. Вы можете узнать больше о вероятности здесь. Короче говоря, он возвращает дискретное значение, которое охватывает все случаи и дает результат, так как либо результат будет иметь значение 1, либо 0. Следовательно, после ассоциации с двумя разными состояниями модель может выдавать выходные данные для любого из значений. настоящее время.
Наиболее популярные алгоритмы, которые используются для двоичной классификации:
- K-Ближайшие соседи
- Логистическая регрессия
- Машина опорных векторов
- Деревья решений
- Наивный Байес
Из упомянутых алгоритмов некоторые алгоритмы были специально разработаны для целей двоичной классификации и изначально не поддерживают более двух типов классов. Некоторыми примерами таких алгоритмов являются машины опорных векторов и логистическая регрессия.Теперь мы создадим собственный набор данных и будем использовать для него двоичную классификацию. Мы будем использовать функцию make_blob () модуля scikit-learn для создания набора данных двоичной классификации. В приведенном ниже примере используется набор данных с 1000 примерами, которые принадлежат любому из двух классов, представленных с двумя входными функциями.
Код:
из импорта numpy, где из коллекций счетчик импорта из sklearn.datasets импортировать make_blobs из matplotlib import pyplot X, y = make_blobs (n_samples = 5000, центры = 2, random_state = 1) печать (X.shape, y.shape) counter = Counter (y) печать (счетчик) для i в диапазоне (10): print (X [i], y [i]) для метки _ в counter.items (): row_ix = where (y == label) [0] pyplot.scatter (X [row_ix, 0], X [row_ix, 1], label = str (label)) pyplot.legend () pyplot.show ()
Выход:
(5000, 2) (5000,)
Счетчик ({1: 2500, 0: 2500})
[-11,5739555 -3,2062213] 1
[0,05752883 3,60221288] 0
[-1.03619773 3.97153319] 0
[-8.22983437 -3.54309524] 1
[-10.436 -4.70600004] 1
[-10.74348914 -5.07] 1
[-3.20386867 4.51629714] 0
[-1.98063705 4.9672959] 0
[-8,61268072 -3,6579652] 1
[-10,54840697 -2,
705] 1
В приведенном выше примере создается набор данных из 5000 выборок и делится их на входные «X» и выходные «Y» элементы. Распределение показывает нам, что любой экземпляр может принадлежать либо к классу 0, либо к классу 1, и в каждом из них примерно 50%.
Первые 10 примеров в наборе данных показаны с входными значениями, которые являются числовыми, а целевое значение — целым числом, которое представляет членство в классе.
Затем для входных переменных создается диаграмма рассеяния, в которой результирующие точки имеют цветовую кодировку на основе значения класса. Мы легко можем увидеть два разных кластера, которые мы можем различить.
Мультиклассовая классификация
Эти типы задач классификации не имеют двух фиксированных меток, но могут иметь любое количество меток. Некоторые популярные примеры мультиклассовой классификации:
- Классификация видов растений
- Классификация лиц
- Оптическое распознавание символов
Здесь нет понятия нормального или ненормального результата, но результат будет принадлежать к одной из многих среди ряда переменных известных классов.Также может быть огромное количество меток, таких как предсказание изображения относительно того, насколько близко оно может принадлежать одному из десятков тысяч лиц системы распознавания.
Другой тип задач, когда вам нужно предсказать следующее слово в последовательности, например, модель перевода для текста, также может рассматриваться как мультиклассовая классификация. В этом конкретном сценарии все слова словаря определяют все возможное количество классов, которое может исчисляться миллионами.
Эти типы моделей обычно создаются с использованием категориального распределения, в отличие от бинарной классификации Бернулли.В категориальном распределении событие может иметь несколько конечных точек или результатов, и, следовательно, модель предсказывает вероятность ввода относительно каждой из выходных меток.
Наиболее распространенные алгоритмы, которые используются для мультиклассовой классификации:
- K-Ближайшие соседи
- Наивный Байес
- Деревья решений
- Повышение градиента
- Случайный лес
Здесь вы также можете использовать алгоритмы двоичной классификации на основе либо одного класса по сравнению со всеми другими классами, также известного как one-vs-rest, либо одной модели для пары классов в модели, которая также известна как один на один.
One Vs Rest — Основная задача здесь — подобрать одну модель для каждого класса, которая будет отличаться от всех остальных классов
One Vs One — Основная задача здесь — определить бинарную модель для каждой пары классов.
Мы снова возьмем пример мультиклассовой классификации, используя функцию make_blobs () модуля scikit learn. Следующий код демонстрирует это.
Код:
из импорта numpy, где из коллекций счетчик импорта из склеарна.наборы данных импортируют make_blobs из matplotlib import pyplot X, y = make_blobs (n_samples = 1000, центры = 4, random_state = 1) печать (X.shape, y.shape) counter = Counter (y) печать (счетчик) для i в диапазоне (10): print (X [i], y [i]) для метки _ в counter.items (): row_ix = where (y == label) [0] pyplot.scatter (X [row_ix, 0], X [row_ix, 1], label = str (label)) pyplot.legend () pyplot.show ()
Выход:
(1000, 2) (1000,)
Счетчик ({1: 250, 2: 250, 0: 250, 3: 250})
[-10.45765533 -3,30899488] 1
[-5.043 -7.80717036] 2
[-1,00497975 4,35530142] 0
[-6,63784922 -4,52085249] 3
[-6,3466658 -8,89940182] 2
[-4,67047183 -3,35527602] 3
[-5,62742066 -1,70195987] 3
[-6.247 -2.83731201] 3
[-1.764 5.03668554] 0
[-8,70416288 -4,3
21] 1 Здесь мы видим, что существует более двух типов классов, и мы можем классифицировать их по отдельности на разные типы.
Классификация с несколькими метками для машинного обучения
В классификации с несколькими метками мы имеем в виду те конкретные задачи классификации, в которых нам нужно назначить две или более конкретных меток класса, которые можно предсказать для каждого примера.Базовым примером может быть классификация фотографий, когда на одной фотографии может быть несколько объектов, таких как собака, яблоко и т. Д. Основное отличие заключается в возможности прогнозирования нескольких меток, а не только одной.
Вы не можете использовать модель двоичной классификации или модель классификации нескольких классов для классификации с несколькими метками, и вы должны использовать модифицированную версию алгоритма, чтобы включить несколько классов, которые могут быть возможны, а затем искать их все. Это становится сложнее, чем простое утверждение «да» или «нет».Здесь используются следующие общие алгоритмы:
- Случайные леса с несколькими метками
- Дерево принятия решений с несколькими метками
- Повышение градиента с несколькими этикетками
Еще один подход — использовать отдельный алгоритм классификации для предсказания меток для каждого типа класса. Мы будем использовать библиотеку из scikit-learn, чтобы с нуля сгенерировать наш набор данных классификации с несколькими метками. Следующий код создает и показывает рабочий пример многокомпонентной классификации 1000 образцов и 4 типов классов.
Код:
.из sklearn.datasets import make_multilabel_classification X, y = make_multilabel_classification (n_samples = 1000, n_features = 3, n_classes = 4, n_labels = 4, random_state = 1) печать (X.shape, y.shape) для i в диапазоне (10): print (X [i], y [i])
Выход:
(1000, 3) (1000, 4) [8. 11. 13.] [1 1 0 1] [5. 15. 21.] [1 1 0 1] [15. 30. 14.] [1 0 0 0] [3. 15. 40.] [0 1 0 0] [7. 22.14.] [1 0 0 1] [12. 28. 15.] [1 0 0 0] [7. 30. 24.] [1 1 0 1] [15. 30. 14.] [1 1 1 1] [10. 23. 21.] [1 1 1 1] [10. 19. 16.] [1 1 0 1]
Несбалансированная классификация машинного обучения
Несбалансированная классификация относится к тем задачам, в которых количество примеров в каждом из классов распределено неравномерно. Как правило, задачи несбалансированной классификации — это задания двоичной классификации, где основная часть обучающего набора данных относится к типу нормального класса, а меньшая часть из них принадлежит к ненормальному классу.
Наиболее важные примеры этих вариантов использования:
- Обнаружение мошенничества
- Обнаружение выбросов
- Медицинский диагностический тест
Задачи трансформируются в задачи бинарной классификации с помощью некоторых специализированных методов. Вы можете использовать либо недостаточную выборку для классов большинства, либо передискретизацию для классов меньшинства. Наиболее известные примеры:
- Случайная недодискретизация
- SMOTE передискретизация
Можно использовать специальные алгоритмы моделирования, чтобы уделить больше внимания классу меньшинств, когда модель адаптируется к набору обучающих данных, который включает экономичные модели машинного обучения.Специально для таких случаев, как:
- Экономическая логистическая регрессия
- Дерево принятия решений с учетом затрат
- Экономичные машины опорных векторов
Итак, после выбора модели нам нужно получить доступ к модели и оценить ее, для чего мы можем использовать Precision , Recall или F-Measure score. Теперь мы рассмотрим, как разработать набор данных для проблемы несбалансированной классификации. Мы будем использовать функцию классификации scikit-learn для создания полностью синтетического и несбалансированного набора данных двоичной классификации из 1000 образцов
Код:
из импорта numpy, где из коллекций счетчик импорта из склеарна.наборы данных импорт make_classification из matplotlib import pyplot X, y = make_classification (n_samples = 1000, n_features = 2, n_informative = 2, n_redundant = 0, n_classes = 2, n_clusters_per_class = 1, weights = [0.99,0.01], random_state = 1) печать (X.shape, y.shape) counter = Counter (y) печать (счетчик) для i в диапазоне (10): print (X [i], y [i]) для метки _ в counter.items (): row_ix = where (y == label) [0] pyplot.scatter (X [row_ix, 0], X [row_ix, 1], label = str (label)) пиплот.легенда () pyplot.show ()
Выход:
(1000, 2) (1000,)
Счетчик ({0: 983, 1: 17})
[0,865 1,18613612] 0
[1,55110839 1,81032905] 0
[1.29361936 1.01094607] 0
[1.11988947 1.63251786] 0
[1.04235568 1.12152929] 0
[1,18114858 0,607] 0
[1.1365562 1.17652556] 0
[0,462- 0,728] 0
[0,18315826 1,07141766] 0
[0,32411648 0,53515376] 0
- Ссылка на совместный документ: https: // colab.research.google.com/drive/1EiGZCGypDIHFNuzm71QN16NJxas41vE3?usp=sharing
- Арнаб Мондал — инженер по обработке данных | Python, C / C ++, разработчик AWS | Технический писатель-фрилансер
- Изображение 1 — https://unsplash.com/photos/n6B49lTx7NM
- Линейная SVM — это та, которую мы обсуждали ранее.
- В ядре полинома должна быть указана степень полинома. Это позволяет использовать изогнутые линии во входном пространстве.
- В ядре радиальной базисной функции (RBF) он используется для нелинейно разделимых переменных. Для расстояния используется метрический квадрат евклидова расстояния. Использование типичного значения параметра может привести к переобучению наших данных. Он используется по умолчанию в sklearn.
- Сигмовидное ядро, аналогичное логистической регрессии, используется для двоичной классификации.
- P (класс | данные) — апостериорная вероятность класса ( цель ) для данного предиктора ( атрибут ). Вероятность наличия у точки данных любого класса для данной точки данных. Это значение, которое мы хотим вычислить.
- P (класс) — априорная вероятность класса .
- P (данные | класс) — это вероятность, которая представляет собой вероятность предиктора с учетом класса .
- P (данные) — априорная вероятность предиктора или предельная вероятность .
- Инициализировать прогнозы с помощью простого дерева решений.
- Вычислить остаточное (фактическое прогнозируемое) значение.
- Постройте еще одно неглубокое дерево решений, которое прогнозирует остаток на основе всех независимых значений.
- Обновите исходный прогноз, добавив новый прогноз, умноженный на скорость обучения.
- Повторите шаги со второго по четвертый для определенного количества итераций (количество итераций будет количеством деревьев).
- Классификатор: Алгоритм, который сопоставляет входные данные с определенной категорией.
- Модель классификации: Модель классификации пытается сделать некоторые выводы из входных значений, данных для обучения. Он предскажет метки / категории классов для новых данных.
- Характеристика: Характеристика — это индивидуальное измеримое свойство наблюдаемого явления.
- Бинарная классификация: Задание классификации с двумя возможными результатами. Например: половая принадлежность (мужской / женский)
- Мультиклассовая классификация: Классификация с более чем двумя классами.При многоклассовой классификации каждому образцу присваивается одна и только одна целевая метка. Например: животное может быть кошкой или собакой, но не одновременно
- Классификация с несколькими метками: Задача классификации, в которой каждый образец сопоставляется с набором целевых меток (более одного класса). Например: новостная статья может быть о спорте, человеке и месте одновременно.
- Инициализировать классификатор, который будет использоваться.
- Обучить классификатор: Все классификаторы в scikit-learn используют метод соответствия (X, y), чтобы соответствовать модели (обучению) для заданных данных поезда X и метки поезда y.
- Предсказать цель: Для немаркированного наблюдения X, прогноз (X) возвращает прогнозируемую метку y.
- Оценить модель классификатора
- классов: 2 («> 50K» и «<= 50K»)
- атрибутов (столбцов): 7
- экземпляров (рядов): 48842
- Точность: (истинно положительный + истинно отрицательный) / общая популяция
- Точность — это отношение правильно спрогнозированных наблюдений к общему количеству наблюдений. Точность — это наиболее интуитивно понятный показатель производительности.
- Истинно-положительное: количество правильных прогнозов о том, что возникновение является положительным
- Истинно отрицательное число: количество правильных прогнозов о том, что возникновение отрицательное.
- F1-Оценка: (2 x точность x отзыв) / (точность + отзыв)
- F1-Score — это средневзвешенное значение точности и отзыва, используемое во всех типах алгоритмов классификации.Таким образом, эта оценка учитывает как ложные срабатывания, так и ложные отрицательные результаты. F1-Score обычно более полезен, чем точность, особенно если у вас неравномерное распределение классов.
- Точность: Когда прогнозируется положительное значение, как часто прогноз оказывается правильным?
- Напомним: когда фактическое значение положительное, как часто прогноз верен?
Здесь мы можем видеть распределение меток, и мы видим серьезный дисбаланс классов, где 983 элемента принадлежат к одному типу и только 17 относятся к другому типу.Как и ожидалось, мы видим большинство типов 0 или 0. Эти типы наборов данных труднее идентифицировать, но они имеют более общий и практический вариант использования.
ЗаключениеСпасибо, что дочитали статью до конца, и если вы сочтете ее полезной, не забудьте поделиться ею со своей сетью. Если вы хотите прочитать некоторые из других моих статей, вы можете щелкнуть здесь и не стесняйтесь связаться со мной в LinkedIn или Github.
Список литературы
Источники изображений
Носители, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению автора.
СвязанныеКлассификация контролируемого машинного обучения: подробное руководство
Машинное обучение — это наука (и искусство) программирования компьютеров, чтобы они могли учиться на данных.
[Машинное обучение — это] область обучения, которая дает компьютерам возможность учиться без явного программирования. — Артур Сэмюэл, 1959,
.
Лучшее определение:
Считается, что компьютерная программа учится на опыте E в отношении некоторой задачи T и некоторого показателя производительности P, если ее производительность на T, измеренная с помощью P, улучшается с опытом E. — Tom Mitchell, 1997
Например, ваш спам-фильтр — это программа машинного обучения, которая может научиться отмечать спам после того, как ему будут предоставлены примеры спам-писем, помеченных пользователями, и примеры обычных писем, не связанных со спамом (также называемых «ветчиной»).Примеры, которые система использует для изучения, называются обучающей выборкой. В этом случае задача ( T ) состоит в том, чтобы пометить спам для новых писем, опыт ( E ) — это данные обучения, и необходимо определить показатель производительности ( P ). Например, вы можете использовать соотношение правильно классифицированных писем как P . Этот конкретный показатель эффективности называется точностью и часто используется в задачах классификации, поскольку это подход к обучению с учителем.
Dive Deeper Введение в машинное обучение для начинающих
Обучение с учителем
При обучении с учителем алгоритмы обучаются на основе размеченных данных.После понимания данных алгоритм определяет, какая метка должна быть присвоена новым данным, связывая шаблоны с немаркированными новыми данными.
Обучение с учителем можно разделить на две категории: классификация и регрессия.
Классификация предсказывает категорию, к которой принадлежат данные.Некоторые примеры классификации включают обнаружение спама, прогнозирование оттока, анализ настроений, определение породы собак и так далее.
Регрессия предсказывает числовое значение на основе ранее наблюдаемых данных.Некоторые примеры регрессии включают прогноз цен на жилье, прогноз цен на акции, прогнозирование роста и веса и так далее.
Dive Deeper Экскурсия по 10 лучшим алгоритмам для новичков в машинном обучении
Классификация
Классификация — это метод определения того, к какому классу принадлежит зависимый, на основе одной или нескольких независимых переменных.
Классификация используется для предсказания дискретных ответов.
1.Логистическая регрессия
Логистическая регрессия похожа на линейную регрессию, но используется, когда зависимой переменной является не число, а что-то еще (например, ответ «да / нет»). Это называется регрессией, но выполняет классификацию на основе регрессии и классифицирует зависимую переменную по любому из классов.
Логистическая регрессия используется для прогнозирования двоичных результатов, как указано выше. Например, если компания, выпускающая кредитные карты, строит модель, чтобы решить, выдавать ли кредитную карту клиенту, она будет моделировать, будет ли клиент «по умолчанию» или «не по умолчанию» использовать свою карту.
Линейная регрессияВо-первых, линейная регрессия выполняется на взаимосвязи между переменными, чтобы получить модель. Предполагается, что пороговое значение для линии классификации составляет 0,5.
Логистическая сигмоидальная функцияЛогистическая функция применяется к регрессии, чтобы получить вероятности ее принадлежности к любому классу.
Приводит журнал вероятности возникновения события к журналу вероятности того, что оно не произойдет. В конце концов, он классифицирует переменную на основе более высокой вероятности того или иного класса.
2. Ближайшие соседи (K-NN)
АлгоритмK-NN — это один из простейших алгоритмов классификации, который используется для идентификации точек данных, которые разделены на несколько классов, для прогнозирования классификации новой точки выборки. K-NN — это непараметрический алгоритм ленивого обучения , . Он классифицирует новые случаи на основе меры сходства (т. Е. Функций расстояния).
K-NN хорошо работает с небольшим количеством входных переменных ( p ), но не справляется, когда количество входов очень велико.
3. Машина опорных векторов (SVM)
Опорный вектор используется как для регрессии, так и для классификации. Он основан на концепции плоскостей решений, определяющих границы принятия решений. Плоскость принятия решения (гиперплоскость) — это плоскость, которая разделяет набор объектов, имеющих различную принадлежность к классам.
Он выполняет классификацию, находя гиперплоскость, которая максимизирует разницу между двумя классами с помощью опорных векторов.
Изучение гиперплоскости в SVM выполняется путем преобразования задачи с использованием некоторой линейной алгебры (т.е., приведенный выше пример представляет собой линейное ядро, которое имеет линейную разделимость между каждой переменной).
Для данных более высокой размерности другие ядра используются как точки и не могут быть легко классифицированы. Они указаны в следующем разделе.
Ядро SVM
Kernel SVM принимает функцию ядра в алгоритме SVM и преобразует ее в требуемую форму, которая отображает данные в более высоком измерении, которое является разделяемым.
Типы функций ядра: :
Тип функций ядраУловка с ядром использует функцию ядра для преобразования данных в пространство признаков более высокой размерности и позволяет выполнять линейное разделение для классификации.
Ядро радиальной базовой функции (RBF)
Область решения SVM ядра RBF фактически также является областью линейного решения. На самом деле SVM ядра RBF создает нелинейные комбинации функций для поднятия выборок в пространство функций более высоких измерений, где для разделения классов можно использовать границу линейного решения.
Итак, практическое правило: используйте линейные SVM для линейных задач и нелинейные ядра, такие как ядро RBF, для нелинейных задач.
4. Наивный байесовский
Наивный классификатор Байеса основан на теореме Байеса с предположениями о независимости между предикторами (т. Е. Предполагает, что наличие признака в классе не связано с каким-либо другим признаком). Даже если эти функции зависят друг от друга или от существования других функций, все эти свойства независимо друг от друга.Таким образом, название наивный Байес.
Основанный на наивном Байесе, Гауссовский наивный Байес используется для классификации, основанной на биномиальном (нормальном) распределении данных.
Ступени
1. Вычислить априорную вероятность
P (класс) = Количество точек данных в классе / Общее количество наблюдений
P (желтый) = 10/17
P (зеленый) = 7/17
2.Расчет предельного правдоподобия
P (данные) = Количество точек данных, аналогичных наблюдению / Общее количество наблюдений
П (?) = 4/17
Значение присутствует при проверке обеих вероятностей.
3. Вычислить вероятность
P (данные / класс) = Количество подобных наблюдений для класса / Общее количество очков в классе.
P (? / Желтый) = 1/7
P (? / Зеленый) = 3/10
4.Апостериорная вероятность для каждого класса
5. Классификация
Чем выше вероятность, тем выше класс принадлежит к этой категории, так как с вероятностью выше 75% точка принадлежит классу зеленый.
Полиномиальная, наивная по Бернулли байесовская модель — это другие модели, используемые при вычислении вероятностей. Таким образом, наивную байесовскую модель легко построить без сложной итеративной оценки параметров, что делает ее особенно полезной для очень больших наборов данных.
5. Древовидная классификация решений
Дерево решений строит модели классификации или регрессии в виде древовидной структуры. Он разбивает набор данных на все меньшие и меньшие подмножества, в то же время постепенно разрабатывается связанное дерево решений. Конечным результатом является дерево с узлами решений и листовыми узлами. Он следует структуре алгоритма Iterative Dichotomiser 3 (ID3) для определения разделения.
Энтропия и получение информации используются для построения дерева решений.
Энтропия
Энтропия — это степень или величина неопределенности случайности элементов. Другими словами, это мера примеси .
Интуитивно он говорит нам о предсказуемости определенного события. Энтропия рассчитывает однородность образца. Если образец полностью однороден, энтропия равна нулю, а если образец разделен поровну, он имеет энтропию, равную единице.
Прирост информации
Прирост информации измеряет относительное изменение энтропии по отношению к независимому атрибуту.Он пытается оценить информацию, содержащуюся в каждом атрибуте. Построение дерева решений — это поиск атрибута, который возвращает наибольший информационный выигрыш (т. Е. Наиболее однородные ветви).
Где Gain (T, X) — это получение информации за счет применения признака X . Энтропия (T) — это энтропия всего набора, а второй член вычисляет энтропию после применения признака X .
Прирост информации ранжирует атрибуты для фильтрации в заданном узле дерева.Рейтинг основан на наивысшей энтропии прироста информации в каждом разбиении.
Недостатком модели дерева решений является переоснащение, поскольку она пытается соответствовать модели, углубляясь в обучающий набор и тем самым снижая точность теста.
Переобучение в деревьях решений может быть минимизировано за счет сокращения узлов.
Ансамблевые методы классификации
Модель ансамбля — это бригада моделей . Технически ансамблевые модели состоят из нескольких моделей обучения с учителем, которые обучаются индивидуально, а результаты объединяются различными способами для достижения окончательного прогноза.Этот результат имеет более высокую предсказательную силу, чем результаты любого из составляющих его алгоритмов обучения независимо.
1. Классификация случайных лесов
Классификатор случайных лесов — это ансамблевой алгоритм, основанный на упаковке, то есть агрегации начальной загрузки. Методы ансамбля объединяет несколько алгоритмов одного и того же или разных типов для классификации объектов (например, ансамбль SVM, наивных байесовских деревьев или деревьев решений).
Общая идея состоит в том, что комбинация моделей обучения увеличивает общий выбранный результат.
Глубокие деревья решений могут страдать от переобучения, но случайные леса предотвращают переобучение, создавая деревья на случайных подмножествах. Основная причина в том, что для этого используется среднее значение всех прогнозов, что исключает смещения.
Случайный лес добавляет модели дополнительную случайность при выращивании деревьев. Вместо того, чтобы искать наиболее важную функцию при разделении узла, она ищет лучшую функцию среди случайного подмножества функций. Это приводит к большому разнообразию, что обычно приводит к лучшей модели.
2. Классификация усиления градиента
Классификатор градиентного повышения — это метод усиления на основе ансамбля. Повышение квалификации — это способ объединить (объединить) слабых учеников, в первую очередь, для уменьшения систематической ошибки прогнозов. Вместо создания пула предикторов, как в случае с упаковкой, при ускорении создается их каскад, где каждый выход является входом для следующего учащегося. Обычно в алгоритме упаковки деревья выращиваются параллельно, чтобы получить средний прогноз по всем деревьям, где каждое дерево построено на выборке исходных данных.Повышение градиента, с другой стороны, использует последовательный подход к получению прогнозов вместо распараллеливания процесса построения дерева. При повышении градиента каждое дерево решений предсказывает ошибку предыдущего дерева решений — таким образом, увеличивает (улучшая) ошибку (градиент).
Работа повышения градиента
Оформить заказ: Повышение градиента с нуля
Классификационная модельХарактеристики
1. Матрица неточностей
Матрица неточностей — это таблица, которая часто используется для описания производительности модели классификации на наборе тестовых данных, для которых известны истинные значения.Это таблица с четырьмя различными комбинациями прогнозируемых и фактических значений для двоичного классификатора.
Матрица неточностей для задачи классификации нескольких классов может помочь вам определить шаблоны ошибок.
Для двоичного классификатора:
Истинно положительный результат — это результат, при котором модель правильно предсказывает положительный класс . Точно так же истинно отрицательный результат — это результат, когда модель правильно предсказывает отрицательный класс.
Ложноположительный и ложноотрицательный
Термины «ложноположительный» и «ложноотрицательный» используются для определения того, насколько хорошо модель прогнозирует в отношении классификации.Ложноположительный результат — это результат, когда модель неверно предсказывает положительный класс . А ложноотрицательный результат — это результат, когда модель неверно предсказывает отрицательный класс . Чем больше значений на главной диагонали, тем лучше модель, тогда как другая диагональ дает худший результат для классификации.
Ложноположительный
Пример, в котором модель ошибочно предсказала положительный класс. Например, модель сделала вывод, что конкретное сообщение электронной почты было спамом (положительный класс), но это сообщение электронной почты на самом деле не было спамом.Это как предупреждающий знак о том, что ошибку следует исправить, поскольку это не такая уж серьезная проблема по сравнению с ложноотрицательным результатом.
Ложноположительный (ошибка типа I) — при отклонении истинной нулевой гипотезы
Ложноотрицательный
Пример, в котором модель ошибочно предсказала отрицательный класс . Например, модель сделала вывод, что конкретное сообщение электронной почты не было спамом (отрицательный класс), но это сообщение электронной почты на самом деле было спамом.Это как знак опасности, что ошибку следует исправить как можно раньше, поскольку она более серьезна, чем ложное срабатывание.
Ложноотрицательный (ошибка типа II) — , если вы принимаете ложную нулевую гипотезу.
Эта картинка прекрасно иллюстрирует вышеуказанные показатели. Результаты анализов мужчины ложноположительны, так как мужчина не может быть беременным. Результаты анализов женщины являются ложноотрицательными, поскольку она явно беременна.
Из матрицы неточностей мы можем вывести точность, точность, отзывчивость и оценку F-1.
Точность
Точность — это доля правильных прогнозов, которые наша модель сделала.
Точность также можно записать как
.Точность сама по себе не дает полной картины при работе с несбалансированным по классам набором данных, когда существует значительная разница между количеством положительных и отрицательных меток. Точность и отзыв являются лучшими показателями для оценки проблем с несбалансированными классами.
Точность
Из всех классов точность — это то, насколько мы правильно предсказали.
Точность должна быть как можно более высокой.
Отзыв
Вспомните, сколько из всех положительных классов мы предсказали правильно. Его также называют чувствительностью или истинно положительным показателем (TPR).
Отзыв должен быть максимально высоким.
Оценка F-1
Часто бывает удобно объединить точность и отзыв в единую метрику, называемую оценкой F-1, особенно если вам нужен простой способ сравнения двух классификаторов.Оценка F-1 — это среднее гармоническое значение точности и запоминания.
Обычное среднее обрабатывает все значения одинаково, в то время как гармоническое среднее придает гораздо больший вес низким значениям, тем самым более наказывая экстремальные значения. В результате классификатор получит высокий балл F-1 только в том случае, если и отзыв, и точность высоки.
3. Кривая оператора приемника (ROC) и площадь под кривой (AUC)
КриваяROC — важный показатель оценки классификации. Это говорит нам, насколько хорошо модель предсказала.Кривая ROC показывает чувствительность классификатора путем нанесения соотношения истинных положительных результатов на частоту ложных срабатываний. Если классификатор выдающийся, истинно положительный показатель увеличится, а площадь под кривой будет близка к единице. Если классификатор похож на случайное угадывание, частота истинных положительных результатов будет линейно увеличиваться с частотой ложных срабатываний. Чем лучше показатель AUC, тем лучше модель.
4. Кривая профиля совокупной точности
CAP модели представляет совокупное количество положительных результатов по оси y по сравнению с соответствующим совокупным количеством параметров классификации по оси x .CAP отличается от рабочей характеристики приемника (ROC), которая отображает соотношение истинно-положительных результатов и ложноположительных. Кривая CAP используется редко по сравнению с кривой ROC.
Рассмотрим модель, которая предсказывает, купит ли покупатель продукт. Если покупатель выбран случайным образом, вероятность того, что он купит товар, составляет 50%. Совокупное количество элементов, для которых покупает покупатель, будет линейно расти до максимального значения, соответствующего общему количеству покупателей.Это распределение называется «случайным» CAP. Это синяя линия на диаграмме выше. С другой стороны, точный прогноз определяет, какой именно клиент купит продукт, так что максимальный покупатель, покупающий недвижимость, будет достигнут при минимальном количестве клиентов, выбранных среди элементов. В результате на кривой CAP образуется крутая линия, которая остается плоской после достижения максимума, что является «идеальной» CAP. Ее также называют «идеальной» линией, она обозначена серой линией на рисунке выше.
В конце концов, модель должна предсказать, где она максимизирует правильные прогнозы и приближается к идеальному модельному ряду.
Ссылки : Оценка классификатора с кривой CAP в Python
Реализация классификации: Github Repo.
Подробнее о Бадрише Шетти:
Подробное руководство по работе рекомендательных систем
Проклятие размерности
СвязанныеПодробнее о Data Science
7 типов алгоритмов классификации
Целью этого исследования является объединение 7 наиболее распространенных типов алгоритмов классификации вместе с кодом Python: логистическая регрессия, наивный байесовский метод, стохастический градиентный спуск, K-ближайшие соседи, дерево решений, случайный лес и машина опорных векторов.
1 Введение
1.1 Классификация структурированных данных
Классификация может выполняться как для структурированных, так и для неструктурированных данных. Классификация — это метод, при котором мы разделяем данные на определенное количество классов. Основная цель проблемы классификации — определить категорию / класс, к которому будут относиться новые данные.
Несколько терминологий, встречающихся в машинном обучении — классификация:
Ниже приведены этапы построения классификационной модели:
1.2 Источник и содержимое набора данных
Набор данных содержит зарплаты. Ниже приводится описание нашего набора данных:
Эти данные были взяты из базы данных бюро переписи населения по адресу:
http: // www.census.gov/ftp/pub/DES/www/welcome.html
1.3 Исследовательский анализ данных
2 типа алгоритмов классификации (Python)
2.1 Логистическая регрессия
Определение: Логистическая регрессия — это алгоритм машинного обучения для классификации. В этом алгоритме вероятности, описывающие возможные результаты одного испытания, моделируются с использованием логистической функции.
Преимущества: Логистическая регрессия предназначена для этой цели (классификации) и наиболее полезна для понимания влияния нескольких независимых переменных на одну переменную результата.
Недостатки: Работает только тогда, когда прогнозируемая переменная является двоичной, предполагает, что все предикторы независимы друг от друга, и предполагает, что данные не содержат пропущенных значений.
2.2 Наивный байесовский
Определение: Наивный алгоритм Байеса, основанный на теореме Байеса с предположением независимости между каждой парой функций. Наивные байесовские классификаторы хорошо работают во многих реальных ситуациях, таких как классификация документов и фильтрация спама.
Преимущества: Этот алгоритм требует небольшого количества обучающих данных для оценки необходимых параметров. Наивные байесовские классификаторы чрезвычайно быстры по сравнению с более сложными методами.
Недостатки: Известно, что наивный байесовский метод плохой оценки.
2.3 Стохастический градиентный спуск
Определение: Стохастический градиентный спуск — это простой и очень эффективный подход для подбора линейных моделей. Это особенно полезно, когда количество образцов очень велико.Он поддерживает различные функции потерь и штрафы за классификацию.
Достоинства: Оперативность и простота внедрения.
Недостатки: Требуется ряд гиперпараметров и чувствительно к масштабированию функций.
2,4 K-ближайшие соседи
Определение: Классификация на основе соседей — это тип ленивого обучения, поскольку он не пытается построить общую внутреннюю модель, а просто сохраняет экземпляры обучающих данных.Классификация вычисляется простым большинством голосов k ближайших соседей каждой точки.
Преимущества: Этот алгоритм прост в реализации, устойчив к зашумленным обучающим данным и эффективен, если обучающие данные велики.
Недостатки: Необходимо определить значение K, а затраты на вычисления высоки, так как необходимо вычислить расстояние каждого экземпляра до всех обучающих выборок.
2.5 Дерево решений
Определение: Учитывая данные атрибутов вместе с их классами, дерево решений создает последовательность правил, которые могут использоваться для классификации данных.
Преимущества: Дерево решений просто для понимания и визуализации, требует небольшой подготовки данных и может обрабатывать как числовые, так и категориальные данные.
Смотрите такжеНедостатки: Дерево решений может создавать сложные деревья, которые плохо обобщаются, а деревья решений могут быть нестабильными, поскольку небольшие изменения в данных могут привести к созданию совершенно другого дерева.
2.6 Случайный лес
Определение: Классификатор случайных лесов — это метаоценка, которая подбирает несколько деревьев решений для различных подвыборок наборов данных и использует среднее значение для повышения точности прогноза модели и контролирует чрезмерную подгонку.Размер подвыборки всегда совпадает с размером исходной входной выборки, но выборки отбираются с заменой.
Преимущества: Сокращение избыточного подгонки и случайного классификатора лесов в большинстве случаев является более точным, чем деревья решений.
Недостатки: Медленное прогнозирование в реальном времени, сложный в реализации и сложный алгоритм.
2.7 Машина опорных векторов
Определение: Машина опорных векторов — это представление обучающих данных в виде точек в пространстве, разделенных на категории четким промежутком, который является как можно более широким.Затем новые примеры отображаются в том же пространстве и предсказываются как принадлежащие к категории, в зависимости от того, на какую сторону пропасти они попадают.
Преимущества: Эффективен в пространствах большой размерности и использует подмножество обучающих точек в функции принятия решения, поэтому он также эффективен с точки зрения памяти.
Недостатки: Алгоритм не дает напрямую оценок вероятностей, они вычисляются с использованием дорогостоящей пятикратной перекрестной проверки.
3 Заключение
3.1 Сравнительная матрица
| Алгоритмы классификации | Точность | F1-Оценка |
| Логистическая регрессия | 84.60% | 0,6337 |
| Наивный Байес | 80,11% | 0,6005 |
| Стохастический градиентный спуск | 82,20% | 0,5780 |
| K-Nearest Neighbours | 83,56% | 0,5924 |
| Дерево принятия решений | 84,23% | 0,6308 |
| Случайный лес | 84,33% | 0,6275 |
| Машина опорных векторов | 84.09% | 0,6145 |
Расположение кода: https://github.com/f2005636/Classification
3.2 Выбор алгоритма
(Типы алгоритмов классификации)
Подпишитесь на нашу рассылку новостей
Получайте последние обновления и актуальные предложения, поделившись своей электронной почтой.Присоединяйтесь к нашей группе Telegram. Станьте частью интересного сообществаРохит Гарг
Рохит Гарг имеет почти 7-летний опыт работы в области анализа данных и машинного обучения.Он много работал в области прогнозного моделирования, анализа временных рядов и методов сегментации. Рохит имеет BE от BITS Pilani и PGDM от IIM Raipur.