что это такое, принцип работы, плюсы и минусы
ASR: что это такое в автомобиле
В комплектации современного автомобиля можно встретить множество систем, принцип работы которых не совсем понятен владельцу. Одним из таких дополнений является ASR – Automatic Slip Regulation. Это антипробуксовочная система, которая позволяет водителю проще проехать по скользкой поверхности, получить более высокий уровень общей безопасности эксплуатации машины, особенно в условиях быстрой поездки на трассе.
Существует множество разновидностей данного комплекта оборудования. Принцип работы устройства в разных автомобилях и даже в различных поколениях одного транспорта может сильно отличаться. В современных условиях постоянного развития автомобильных технологий это уже не удивляет. Давайте более подробно рассмотрим основные особенности данного дополнения.
ASR – что это такое в автомобиле, и как это работает?
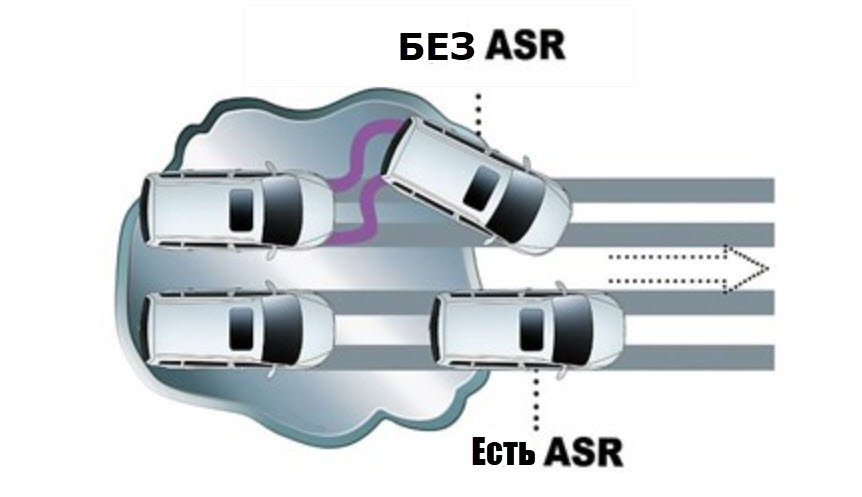
Такое оснащение относят к активным системам безопасности. Главная задача системы полностью или насколько это возможно предотвратить возможность пробуксовки колес при прохождении зимней дороги, а также при поездке по грязевым проселочным дорогам. Именно пробуксовка часто становится причиной того, что водитель самостоятельно не может выехать, приходится обращаться к помощи трактора или водителей попутных авто.
Главная задача системы полностью или насколько это возможно предотвратить возможность пробуксовки колес при прохождении зимней дороги, а также при поездке по грязевым проселочным дорогам. Именно пробуксовка часто становится причиной того, что водитель самостоятельно не может выехать, приходится обращаться к помощи трактора или водителей попутных авто.
Существует два основных принципа работы антипробуксовочной системы ASR:
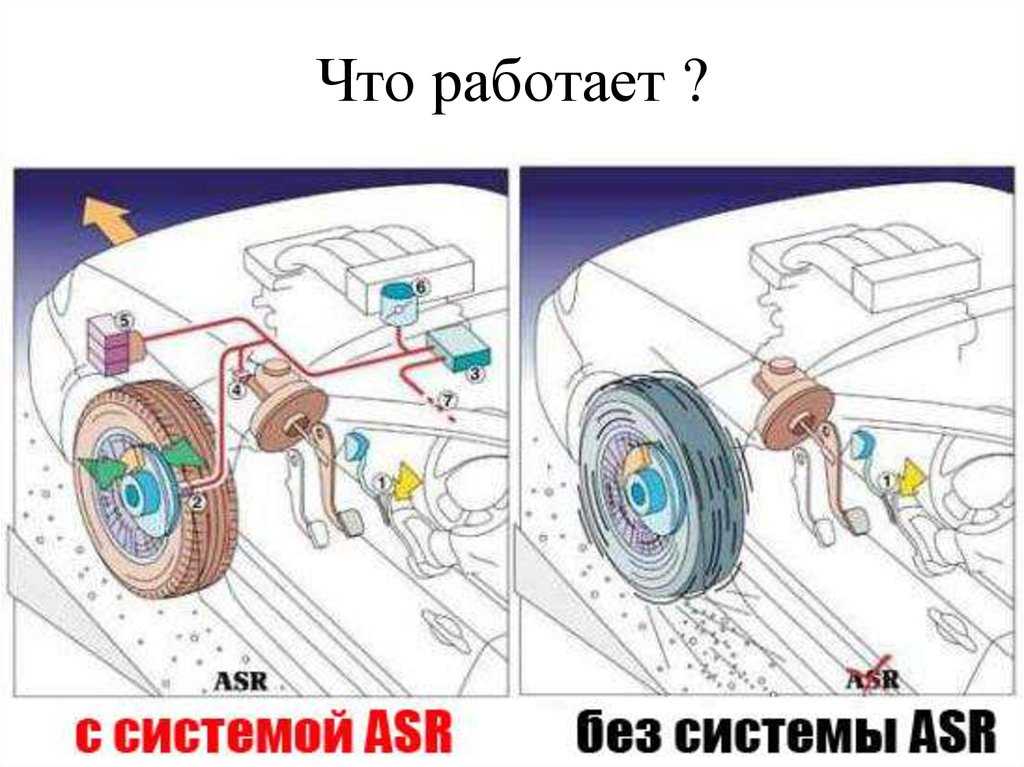
- Первый сценарий запускается, если машина движется со скоростью до 60 км/ч. В этом случае подключенный к датчикам АСР насос с тормозной жидкостью быстро создает давление и притормаживает колесо, которое сорвалось в пробуксовку.
- Второй вариант работы включается при скорости выше 60 км/ч. В этой ситуации торможение может быть опасным, поэтому ASR подает сигналы через ЭБУ на двигатель и снижает крутящий момент. Это не всегда на 100% эффективно, но очень безопасно для водителя.
Бытует мнение, что разделение на два сценария произошло, чтобы сохранить колодки, которые могут перегреваться и даже выгорать на высокой скорости.
Система управляется датчиками, которые установлены на каждом ведущем колесе. На автомобилях с полным приводом оборудование АСР гораздо дороже и сложнее, здесь оно вносит свои преимущества в проходимость и безопасность поездки по бездорожью.
ASR лучше или хуже традиционной системы ESP?
Проблема обозначений – это один из дьяволов современного автомобилестроения. Водители автомобилей Toyota могли с ухмылкой читать первую часть публикации, так как они знают, что антипробуксовочная система называется TRC (Traction Control), а другие автомобилисты даже нашли в документации к своей машине другие обозначения – TCS (Traction Control System), ETS, ASC и прочие аббревиатуры. В целом это обозначения одной и той же системы.
ESP – это не просто антипробуксовочное оборудование. Это целый комплекс средств поддержания курсовой устойчивости, который включает такое оборудование:
Это целый комплекс средств поддержания курсовой устойчивости, который включает такое оборудование:
- ASR или любой другой вид антипробуксовки из указанных выше вариантов названий;
- ABS – антиблокировочная система, которая снижает риски блокировки колес при торможении авто;
- MSR – также антиблокировочное оборудование, которое предотвращает блокировку колес при торможении двигателем;
- EBV – система для распределения тормозных усилий между всеми колесами вашего автомобиля.
В элитных авто можно найти еще десяток аббревиатур, которые называют системы безопасности и повышения контроля. Так что отличия ASR от ESP невозможно найти – это названия совершенно разных явлений в вашей машине. АСР является лишь частью комплекса ESP, обеспечивая один из факторов снижения риска заноса или закапывания в грязевой и снежной яме.
Есть ли явные преимущества от системы ASR?
Преимущества заключаются в том, что при поездке на рыбалку по проселочной грязной дороге вам не придется выходить из авто и толкать его, измазывая всю одежду. Как только колесо начинает прокручиваться, система включается в действие и практически блокирует его, позволяя другому ведущему колесу с более качественным сцеплением с поверхностью дороги вытащить машину.
Как только колесо начинает прокручиваться, система включается в действие и практически блокирует его, позволяя другому ведущему колесу с более качественным сцеплением с поверхностью дороги вытащить машину.
Антипробуксовочная система ASR в недорогих автомобилях практически не устанавливается. Чаще всего это привилегия авто классом выше или более дорогой комплектации. Если у вас есть выбор, устанавливать ли АСР в машину, но за это нужно доплатить деньги, стоит выбирать вариант с установкой данного комплекса. Это повышение вашей уверенности и безопасности в эксплуатации. Уже первая зима на машине покажет, что вы приняли совершенно правильное решение.
Многие автомобилисты с опытом посмотрят, как работает система ASR, поймут ее примитивность и скажут, что смысла от нее никакого нет. Это справедливо только отчасти. Если вы опытный водитель с 20 годами стажа поездки по сложным дорогам, то и без такой помощи вряд ли застрянете в снежном плену. Но для владельцев авто с менее ярким опытом такие комплексы все же будут полезны.
Из недостатков стоит выделить лишь несколько особенностей:
- достаточно высокая стоимость, если на ваш автомобиль можно поставить такую систему опционально при заказе машины в салоне;
- не всегда эффективное срабатывание, очень часто АСР инициирует торможение слишком поздно, когда машина уже закопалась;
- неоднозначная работа на высоких скоростях, так как здесь это оборудование бессильно сделать что-либо эффективное;
- невозможность отключить на некоторых авто, которые не позволяют деактивировать весь модуль ESP;
- быстрый износ колодок, если вы постоянно ездите по сколькой или грязной дороге с риском срывания колес в пробуксовку.
ASR не будет оценивать, насколько опасная или безопасная пробуксовка на вашей машине. Она будет срабатывать в любой ситуации, когда датчики показывают буксующее колесо. Конечно, без отключения такой системы вы не сможете продемонстрировать навыки спортивной поездки, полицейских разворотов и красивого контролируемого заноса на снегу. АСР включится в самый ответственный момент и испортит ваш вираж.
АСР включится в самый ответственный момент и испортит ваш вираж.
Итоги: как можно оценить работу ASR на автомобиле?
Сложно дать однозначную оценку данному комплексу систем безопасности. В составе ESP этот блок хорошо справляется с определенными нюансами на небольшой скорости. А вот при поездке по трассе АСР может даже помешать водителю своими силами исправить ситуацию. Неоднозначной является и польза подтормаживания колеса в процессе пробуксовки.
К сожалению, ASR – это не замена хорошей механической блокировке, так как электроника не может столь же эффективно распределить крутящий момент по всем ведущим колесам. Тем не менее, это выход для тех автомобилей, в которых никакой блокировки и быть не может. Если у вас есть выбор опциональной установки такой системы, то стоит воспользоваться таким предложением.
Если материал был для вас интересен или полезен, опубликуйте его на своей странице в социальной сети:
Добавить комментарий
В начало страницы
Система ASR что это такое в автомобиле
Содержание
- Расшифровываем аббревиатуры
- Основа работы ASR
- На что реагирует ASR
- Основные режимы работы ASR
- Видео про стабилизирующие системы ASR, ESP
- Вопросы и ответы:
В списке технических характеристик современных автомобилей встречается масса не вполне понятных аббревиатур, упоминание которых почему-то считается хорошим маркетинговым ходом.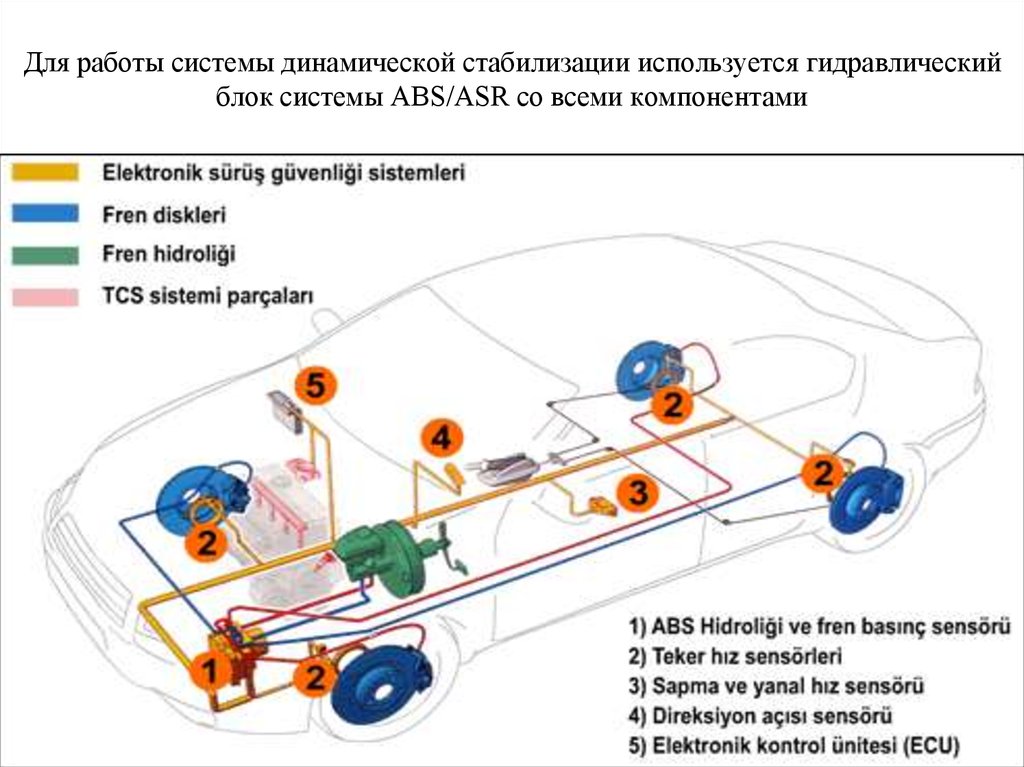 Один бренд козыряет системой ASR, у другого упоминается ETS, у третьего – DSA. Что же, на самом деле, они обозначают и какое влияние оказывают на поведение машины на дороге?
Один бренд козыряет системой ASR, у другого упоминается ETS, у третьего – DSA. Что же, на самом деле, они обозначают и какое влияние оказывают на поведение машины на дороге?
Расшифровываем аббревиатуры
О чем хочет сказать владелец бренда, указывая на то, что его автомобили оснащены системой ASR? Если эту аббревиатуру расшифровать, то получится Automatic Slip Regulation, а в переводе – автоматическая антипробуксовочная система. И это одно из наиболее распространенных конструкторских решений, без использования которых современные автомобили вообще не строятся.
Однако каждому производителю хочется показать, что его машина самая крутая и особенная, поэтому он для своей антипробуксовочной системы придумывает собственную аббревиатуру.
- BMW – ASC или DTS, и у баварских автомобилестроителей это две разные системы.
- Toyota – A-TRAC и TRC.
- Chevrolet & Opel – DSA.
- Mercedes – ETS.
- Volvo – STS.
- Range Rover – ETC.
Вряд ли есть смысл продолжать список обозначений того, что имеет одинаковый алгоритм работы, а отличается лишь в деталях – то есть, в способе его реализации.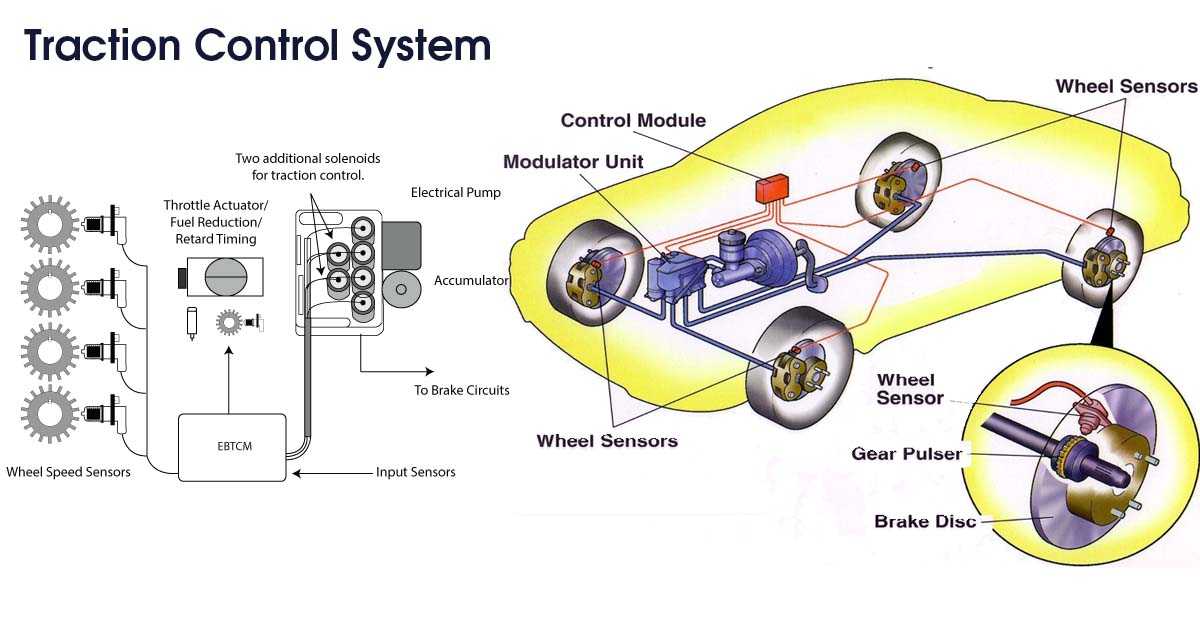 Поэтому давайте попробуем понять то, на чем основан принцип работы системы, предотвращающей пробуксовку колес.
Поэтому давайте попробуем понять то, на чем основан принцип работы системы, предотвращающей пробуксовку колес.
Основа работы ASR
Пробуксовка – это увеличение количества оборотов одного из ведущих колес из-за отсутствия сцепления шины с дорогой. Чтобы колесо замедлить, требуется подключение тормозной системы, поэтому ASR всегда работает в паре с ABS – устройством, предотвращающим блокирование колес при торможении. Конструктивно это реализовано размещением электромагнитных клапанов ASR внутри блоков ABS.
Однако размещение в одном корпусе не означает, что эти системы дублируют друг друга. У ASR другие задачи.
- Выравнивание угловых скоростей обоих ведущих колес путем блокировки дифференциала.
- Регулировка крутящего момента. Эффект восстановления сцепления с дорогой после сброса газа известен большинству автолюбителей. Это же делает и ASR, но в автоматическом режиме.
На что реагирует ASR
Чтобы выполнять свои обязанности, антипробуксовочная система оснащена набором датчиков, учитывающих технические параметры и поведение автомобиля.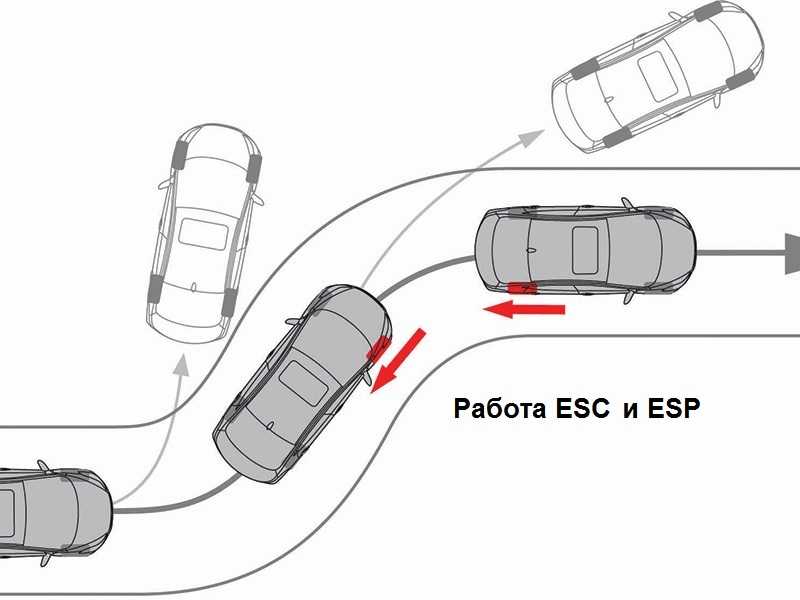
- Определяют разницу угловых скоростей вращения ведущих колес.
- Распознают курсовое рысканье машины.
- Реагируют на замедление движения при увеличении угловой скорости вращения ведущих колес.
- Учитывают скорость движения.
Основные режимы работы ASR
Притормаживание колес происходит, если автомобиль двигается со скоростью меньшей, чем 60 км/час. Существует два типа реакции системы.
- В момент, когда одно из ведущих колес начинает пробуксовывать – его угловая скорость вращения увеличивается, срабатывает электромагнитный клапан, блокирующий дифференциал. Притормаживание происходит за счет разницы в силе трения под колесами.
- Если датчики линейного перемещения не фиксируют движения или отмечают его замедление, а ведущие колеса при этом увеличивают скорость вращения, то подается команда на активацию тормозной системы. Колеса замедляются физическим удержанием, за счет силы трения тормозных колодок.
Если скорость автомобиля более 60 км/час, то регулируется вращающий момент двигателя. В этом случае учитываются показания всех датчиков, в том числе и определяющих разницу угловых скоростей различных точек кузова. Например, если задний бампер начинает «оббегать» передний. Это позволяет уменьшить курсовое рысканье машины и занос, причем реакция на такое поведение машины происходит во много раз быстрее, чем при ручном управлении. Действие ASR заключается в кратковременном торможении двигателем. После возвращения всех параметров движения в равновесное состояние он плавно набирает обороты.
В этом случае учитываются показания всех датчиков, в том числе и определяющих разницу угловых скоростей различных точек кузова. Например, если задний бампер начинает «оббегать» передний. Это позволяет уменьшить курсовое рысканье машины и занос, причем реакция на такое поведение машины происходит во много раз быстрее, чем при ручном управлении. Действие ASR заключается в кратковременном торможении двигателем. После возвращения всех параметров движения в равновесное состояние он плавно набирает обороты.
Видео про стабилизирующие системы ASR, ESP
Как работает ESP,ABS,ASR
Смотрите это видео на YouTube
Вопросы и ответы:
Что такое ESP и ASR? ESP – электронная система стабилизации, которая предотвращает занос автомобиля в поворотах на скорости. ASR – это часть системы ESP (в процессе разгона автомобиля система предотвращает пробуксовку ведущих колес).
Для чего нужна кнопка ASR? Так как эта система не дает ведущим колесам буксовать, естественно, она не даст водителю выполнить управляемый занос с дрифтованием.
Отключение этой системы облегчает задачу.
Главная » Без Категории » Система ASR что это такое в автомобиле
2022-05-26
By: Александр Фальченко
On:
In: Без Категории
Антипробуксовочная система (ASR, ESP, TCS, DTC) – принцип работы.
Дата публикации: 12.04.2018 13:00
Антипробуксовочная система (ASR, ESP, TCS, DTC) – принцип работы.
В конце XX-го века автомобили начали оснащать широким спектром различных систем безопасности, призванных увеличить комфорт водителя и безопасность на дороге. Так появилась антипробуксовочная система, которая была создана для того, чтобы предотвратить проскальзывание и попадание автомобиля в занос из-за увеличения оборотов двигателя.
Эта проблема касается, прежде всего, мощных автомобилей, где часто проявляется проблема превышения выдаваемой мощности над необходимой, что выливается в частую пробуксовку колёс при старте с места. Стоит отметить, что подобное поведение наблюдается не только в начале движения, но и во время изменения передачи и быстром ускорении. Антипробуксовочная система призвана устранить этот недостаток, не дать автомобилю уйти в занос, избежать проскальзывания колёс и, тем самым, значительно повысить уровень безопасности водителя, пассажиров и окружающих людей.
Стоит отметить, что подобное поведение наблюдается не только в начале движения, но и во время изменения передачи и быстром ускорении. Антипробуксовочная система призвана устранить этот недостаток, не дать автомобилю уйти в занос, избежать проскальзывания колёс и, тем самым, значительно повысить уровень безопасности водителя, пассажиров и окружающих людей.
«Глазами» многих современных систем различного назначения являются датчики. В современных антипробуксовочных системах таких датчиков масса. Однако, антипробуксовочная система не является переусложнённым и ненадёжным элементом автомобиля. Конструкция отличается простотой и состоит из малого числа элементов. Из чего же состоит она состоит?
Она включает в себя:
- Датчики оборотов колеса;
- Блок управления;
- Модуляторы;
- Высокоскоростная шина для передачи данных и обмена ими.
Информация от датчиков передаётся по шине в электронный блок управления, который через соответствующие модуляторы распределяет крутящий момент.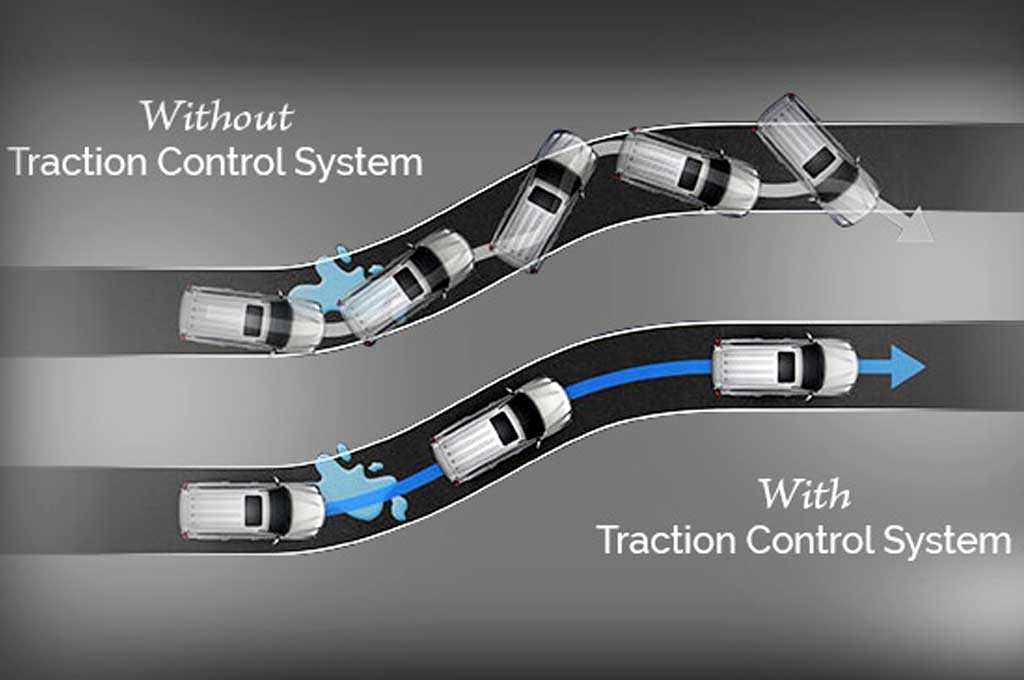
В целом, всё происходит по простой схеме: блок управления получает различные данные о скорости вращения колёс, сравнивает их с нормальными параметрами и, если выявляется превышение, то двигателю даётся сигнал на снижение мощности. Именно таким образом и обеспечивается работа антипробуксовочной системы.
Более продвинутые антипробуксовочные системы одновременно управляют и тормозной системой. Это позволяет не только изменить мощность двигателя, но и вовремя притормаживать колёса. Так обеспечивается отсутствие пробуксовки и правильный быстрый разгон вашего автомобиля.
Отметим, что антипробуксовочный блок управления связан с ABS, что значительно расширяет функциональные возможности автомобиля. Тут одновременно регулируется давление в тормозной системе и мощность вашего мотора, что полностью исключает возможность пробуксовки и заноса.
Тут всё просто — при выявлении использования избыточной мощности, одновременно начинают притормаживаться колёса и снижается выходная мощность двигателя.
Блок управления типичной антипробуксовочной системы способен обрабатывать одновременно большое количество данных. Именно поэтому система может оперативно оценивать необходимость корректировки мощности двигателя, полностью освобождая водителя от контроля «на глаз». В данном случае электроника всецело отвечает за параметры ускорения и скорости вашего автомобиля.
Важно знать, что хоть большинство современных автопроизводителей и оснащает свои автомобили подобными системами, но никто не запрещает отключать их по мере необходимости. В этом случае мощность двигателя будет использоваться без вмешательства антипробуксовочной системы и водителю придётся самому контролировать параметры разгона и скорости, исключая пробуксовку и заносы.
В целом, антипробуксовочная система – крайне важное звено в обеспечении безопасной эксплуатации автомобиля, поэтому крайне важно следить за её работоспособностью и незамедлительно прибегнуть к ремонту в случае необходимости.
Справиться с такой задачей может только опытный автоэлектрик-диагност, у которого имеются все необходимые инструменты, тестеры и иные электронные устройства. Вмешательство водителя в ремонт данной системы исключён полностью, ибо без знаний в области автомобильного ремонта и электротехники, можно повредить все электронные системы автомобиля, сделав его дальнейшее использование невозможным. Сами понимаете, что самодеятельность может вылиться в крайне длительный и дорогой ремонт.
Если неполадки всё же настигли вас и требуется ремонт антипробуксовочной системы, мы рекомендуем вам обратиться в наш автосервис. Опытный электрик-диагност с десятилетним стажем поможет решить вашу проблему.
Кому в первую очередь необходима антипробуксовочная система и в каких ситуациях она вам поможет?
Антипробуксовочная система будет вам особенно полезной на скользких или мокрых дорогах. Вдобавок, наличие такой системы будет очень полезно молодым водителям, которые не имеют достаточного опыта, чтобы правильно и оперативно контролировать мощность мотора, что приводит к постоянным пробуксовкам и заносам.
Вдобавок, наличие такой системы будет очень полезно молодым водителям, которые не имеют достаточного опыта, чтобы правильно и оперативно контролировать мощность мотора, что приводит к постоянным пробуксовкам и заносам.
Отметим, что антипробуксовочная система увеличивает расход топлива, т.к. определённая часть мощности двигателя просто отсекается электроникой. Именно поэтому многие опытные водители полностью отключают антипробуксовочную систему, дабы снизить расход топлива.
Выводы.
Антипробуксовочная система – прекрасное современное решение, увеличивающее безопасность автомобиля для водителя и окружающих. Однако, она требует тщательного контроля и своевременного ремонта, особенно, если вы молодой водитель с небольшим опытом.
Теги автоэлектрик невский район антипробуксовочная система ремонт антипробуксовочной системы ремонт блока ABS ремонт электронных блоков управления
Программное обеспечение для автоматического распознавания речи (ASR) — введение по-человечески».

Но во многих отношениях мы неуклонно продвигаемся к этому будущему сценарию удивительно быстрыми темпами благодаря продолжающемуся развитию так называемой технологии автоматического распознавания речи. И, по крайней мере, пока что он обещает действительно полезные инновации в пользовательском опыте для всех видов приложений.
Автоматическое распознавание речи или ASR — это технология, которая позволяет людям использовать свой голос для общения с компьютерным интерфейсом таким образом, который в самых сложных вариациях напоминает обычный человеческий разговор. .
Самая продвинутая версия разработанных в настоящее время технологий ASR вращается вокруг того, что называется Обработка естественного языка , или сокращенно NLP . Этот вариант ASR наиболее близок к реальному общению между людьми и машинным интеллектом, и хотя ему еще предстоит пройти долгий путь, прежде чем он достигнет вершины развития, мы уже видим некоторые замечательные результаты в виде интеллектуальных интерфейсов для смартфонов, таких как программа Siri на iPhone и других системах, используемых в бизнесе и передовых технологиях.
Однако, даже эти программы НЛП, несмотря на «точность» примерно 96–99 %, могут достичь таких результатов только в идеальных условиях, в которых вопросы, заданные им людьми, относятся к простому типу «да» или «нет» или имеют только ограниченное количество возможных вариантов ответа на основе выбранных ключевых слов (подробнее об этом чуть позже).
Теперь, когда мы рассказали о чудесных перспективах технологии ASR, давайте посмотрим, как эти системы работают сегодня, поскольку мы их уже используем.
Большая часть информации, которую мы собираемся осветить, также объяснена со значительными, очень наглядными деталями дополнительной инфографикой, созданной профессионалами программного обеспечения ASR в West Interactive. Вы действительно должны также взглянуть на их сообщение здесь.
Основное руководство по работе автоматического распознавания речи
Основная последовательность событий, которая заставляет любое программное обеспечение автоматического распознавания речи, независимо от его сложности, подбирать и разбирать ваши слова для анализа и ответа, выглядит следующим образом:
- Вы говорите с программой через аудиопоток
- Устройство, с которым вы разговариваете, создает волновой файл ваших слов
- Волновой файл очищается путем удаления фонового шума и нормализации громкости
- Полученная отфильтрованная форма волны затем разбивается на так называемые фонемы.
 (Фонемы являются основными строительными блоками звуков языка и слов. В английском языке их 44, состоящих из звуковых блоков, таких как «wh», «th», «ka» и «t».
(Фонемы являются основными строительными блоками звуков языка и слов. В английском языке их 44, состоящих из звуковых блоков, таких как «wh», «th», «ka» и «t». - Каждая фонема подобна звену цепи, и анализируя их последовательно, начиная с первой фонемы, программное обеспечение ASR использует статистический вероятностный анализ для вывода целых слов, а затем полных предложений
- Ваш ASR, теперь «понявший» ваши слова, может осмысленно ответить вам.
Некоторые ключевые примеры вариантов автоматического распознавания речи
Двумя основными типами вариантов программного обеспечения для автоматического распознавания речи являются направленные диалоги и разговоры на естественном языке (то же самое, что и обработка естественного языка, о которой мы упоминали выше).
Направленный диалог Разговоры представляют собой гораздо более простую версию ASR в действии и состоят из машинных интерфейсов, которые устно говорят вам ответить определенным словом из ограниченного списка вариантов, тем самым формируя свой ответ на ваш узко определенный запрос.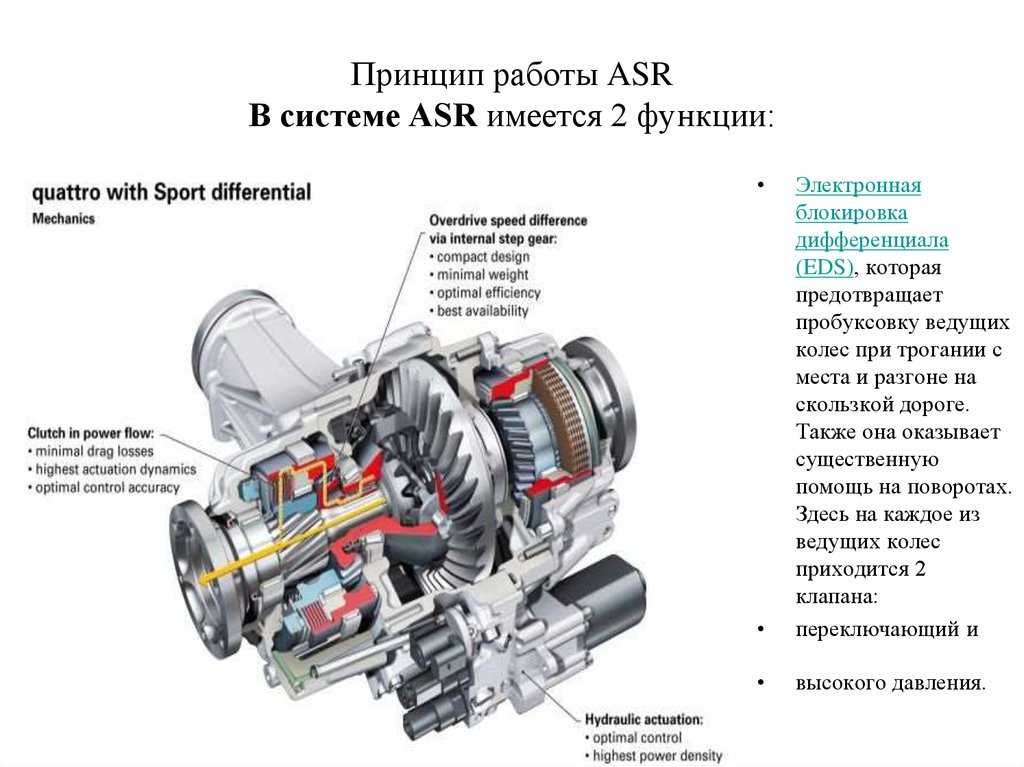 Автоматизированный банкинг по телефону и другие интерфейсы обслуживания клиентов обычно используют программное обеспечение ASR для направленного диалога.
Автоматизированный банкинг по телефону и другие интерфейсы обслуживания клиентов обычно используют программное обеспечение ASR для направленного диалога.
Разговоры на естественном языке (НЛП, о котором мы рассказывали во введении) — это гораздо более сложные варианты ASR, и вместо сильно ограниченного меню слов, которые вы можете использовать, они пытаются имитировать реальный разговор, позволяя вам использовать открытые диалоги. формат чата с ними. Интерфейс Siri на iPhone — очень продвинутый пример таких систем.
Как работает обработка естественного языка?
Учитывая важность НЛП как будущего направления технологии РАС, оно гораздо важнее, чем направленный диалог, при разработке систем распознавания речи.
Он работает таким образом, чтобы в общих чертах имитировать то, как люди сами понимают речь и реагируют соответственно.
Типичный словарный запас системы НЛП ASR состоит из 60 или более тысяч слов. Теперь это означает более 215 триллионов возможных комбинаций слов, если вы скажете всего три слова подряд!
Тогда очевидно, что для системы НЛП ASR было бы крайне непрактично сканировать весь свой словарь на наличие каждого слова и обрабатывать их по отдельности. Вместо этого система естественного языка предназначена для реагирования на гораздо меньший список выбранных «помеченных» ключевых слов, которые дают контекст для более длинных запросов.
Вместо этого система естественного языка предназначена для реагирования на гораздо меньший список выбранных «помеченных» ключевых слов, которые дают контекст для более длинных запросов.
Таким образом, используя эти контекстуальные подсказки, система может намного быстрее определить, что именно вы ей говорите, и узнать, какие слова используются, чтобы она могла адекватно ответить.
Например, если вы произносите такие фразы, как «прогноз погоды», «проверьте мой баланс» и «я хочу оплатить свои счета», помеченные ключевые слова, на которых фокусируется система НЛП, могут быть «прогноз», «баланс» и «счета». Затем он будет использовать эти слова, чтобы найти контекст других слов, которые вы использовали, и не совершать ошибок, таких как путаница «погода» с «будь то».
Настройка
Тест : Как ASR «учится» у людей Обучение систем ASR, будь то НЛП или системы направленного диалога, работает на двух основных механизмах. Первый и более простой из них называется «Настройка человека», а второй, гораздо более продвинутый вариант называется «Активное обучение».
Настройка человека: Это относительно простое средство обучения ASR. В нем программисты-люди просматривают журналы разговоров данного программного интерфейса ASR и просматривают часто используемые слова, которые он должен был услышать, но которых нет в его предварительно запрограммированном словаре. Затем эти слова добавляются в программу, чтобы она могла расширить свое понимание речи.
Активное обучение: Активное обучение — это гораздо более сложный вариант ASR, и его особенно испытывают с версиями технологии распознавания речи NLP. При активном обучении само программное обеспечение запрограммировано на автономное изучение, сохранение и усвоение новых слов, таким образом постоянно расширяя свой словарный запас по мере того, как оно подвергается воздействию новых способов говорить и говорить.
Это, по крайней мере теоретически, позволяет программе улавливать более конкретные речевые привычки конкретных пользователей, чтобы лучше общаться с ними.
Так, например, если определенный пользователь-человек продолжает отрицать автозамену определенного слова, программное обеспечение НЛП в конечном итоге научится распознавать другое использование этого конкретного человека этого слова как «правильную» версию.
Инфографика об автоматическом распознавании речи (ASR) от West InteractiveХотите узнать больше?
Хотите получить признанный в отрасли сертификат о прохождении курсов по UX-дизайну, дизайн-мышлению, дизайну пользовательского интерфейса или другим смежным темам дизайна? Онлайн-курсы по UX от Interaction Design Foundation могут дать вам отраслевые навыки для продвижения вашей карьеры в области UX. Например, «Дизайн-мышление», «Стань UX-дизайнером с нуля», «Проведение юзабилити-тестирования» или «Исследование пользователей — методы и лучшие практики» — одни из самых популярных курсов. Удачи на вашем пути обучения!
(Главное изображение: Depositphotos)
Сравнение систем автоматического распознавания речи (ASR) | по науке | Sciforce
Системы автоматического распознавания речи (ASR) становятся все более важной частью взаимодействия человека и машины. В то же время они все еще слишком дороги для разработки с нуля. Компаниям необходимо выбирать между использованием облачного API для системы ASR, разработанной технологическими гигантами, или игрой с решениями с открытым исходным кодом.
В то же время они все еще слишком дороги для разработки с нуля. Компаниям необходимо выбирать между использованием облачного API для системы ASR, разработанной технологическими гигантами, или игрой с решениями с открытым исходным кодом.
В этом посте мы сравниваем восемь самых популярных систем ASR, чтобы облегчить выбор в соответствии с потребностями вашего проекта и навыками команды. Мы провели наши тесты, чтобы определить коэффициент ошибок слов (WER) для некоторых перечисленных систем ASR. Мы обещаем обновлять и добавлять любую новую информацию, когда это возможно. Давайте погрузимся прямо в него.
Автоматическое распознавание речи (ASR) — это технология идентификации и обработки человеческого голоса с помощью компьютерного оборудования и программных средств. Вы можете использовать его, чтобы определить произносимые слова или подтвердить личность человека. В последние годы ASR стал популярен в различных отраслях в отделах обслуживания клиентов.
Базовые системы ASR распознают ввод отдельных слов, таких как ответы «да» или «нет» и произнесенные цифры.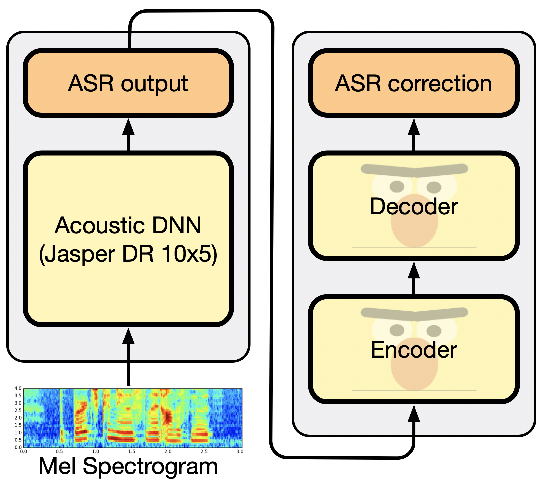 Однако более сложные системы ASR поддерживают непрерывную речь и позволяют вводить прямые запросы или ответы, такие как запрос направления движения или номер телефона определенного контакта. Современные системы ASR распознают полностью спонтанную речь, которая является естественной, не отрепетированной и содержит незначительные ошибки или маркеры нерешительности.
Однако более сложные системы ASR поддерживают непрерывную речь и позволяют вводить прямые запросы или ответы, такие как запрос направления движения или номер телефона определенного контакта. Современные системы ASR распознают полностью спонтанную речь, которая является естественной, не отрепетированной и содержит незначительные ошибки или маркеры нерешительности.
Однако коммерческие системы предлагают ограниченный доступ к подробным выходным данным модели, включая матрицы внимания, вероятности отдельных слов или символов или выходные данные промежуточных слоев, и ограниченную интеграцию с другим программным обеспечением.
Следовательно, системы ASR, такие как AT&T Watson, Microsoft Azure Speech Service, Google Speech API и Nuance Recognizer (купленные Microsoft в апреле 2021 года), не так уж гибки.
В ответ на эти ограничения появляется больше систем и сред ASR с открытым исходным кодом. Однако растущее количество таких систем усложняет понимание того, какая из них лучше всего соответствует потребностям проекта, что предлагает полный контроль над процессом, что можно использовать без особых усилий и глубоких знаний в области машинного и глубокого обучения.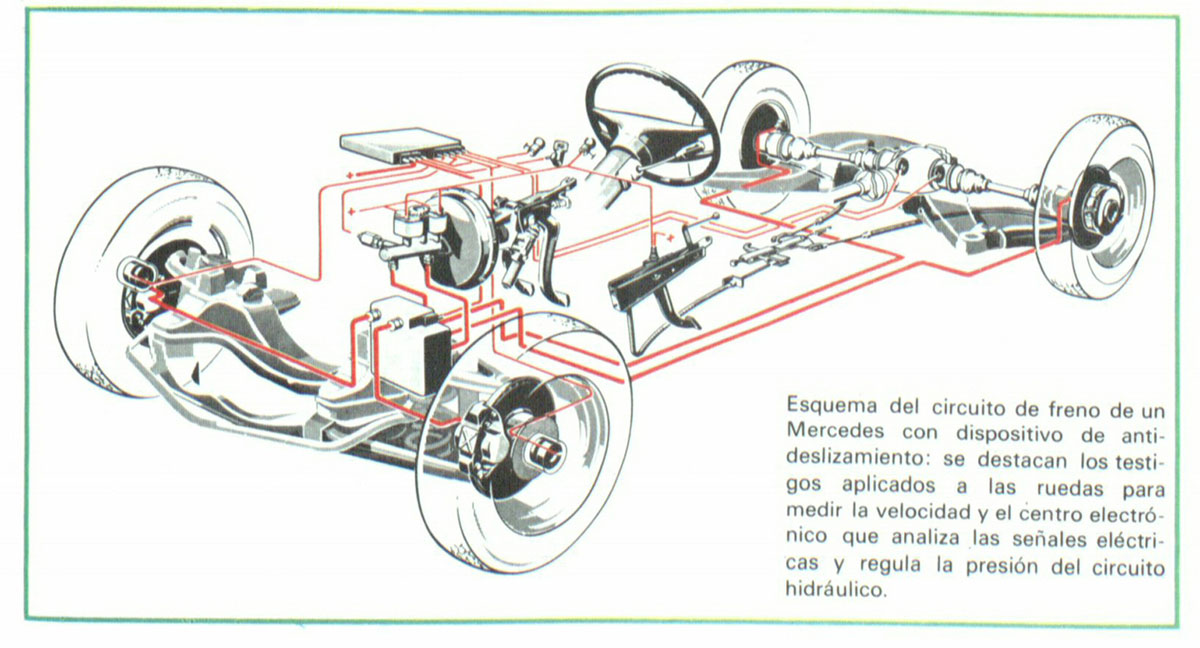 Итак, давайте раскроем все гайки и болты.
Итак, давайте раскроем все гайки и болты.
Конечно, коммерческие системы ASR, разработанные такими технологическими гигантами, как Google или Microsoft, обеспечивают наилучшую точность распознавания речи. С другой стороны, они редко предоставляют разработчикам большой контроль над системой, обычно позволяя им расширять словарный запас или произношение, но оставляя алгоритмы нетронутыми.
Google Cloud Speech-to-Text — это служба, основанная на нейронных сетях глубокого обучения и предназначенная для приложений голосового поиска или транскрипции речи. В настоящее время он является явным лидером среди других сервисов ASR с точки зрения точности и поддерживаемых языков.
Языковая поддержка
В настоящее время система распознает 137 языков и их вариантов с обширным словарным запасом в моделях распознавания по умолчанию, общих и поисковых системах. Вы можете использовать модель по умолчанию для расшифровки аудио любого типа, а поисковые и командные — только для коротких аудиоклипов.
Ввод
Можно напрямую передавать звуковые файлы продолжительностью менее минуты для выполнения так называемого синхронного распознавания речи, когда вы разговариваете со своим телефоном и получаете текст в ответ. Правильный способ сделать это — загрузить его в Google Storage и использовать асинхронный API для более длинных файлов.
Поддерживаемые аудиокодировки: MP3, FLAC, LINEAR16, MULAW, AMR, AMR_WB, OGG_OPUS, SPEEX_WITH_HEADER_BYTE, WEBM_OPUS.
Цены
Google предоставляет один бесплатный час обработки звука и 1,44 доллара США за час аудио.
Цены на Google Cloud Speech-to-Text. (Изображение предоставлено Google)Модели
Google предлагает четыре готовые модели: по умолчанию, голосовые команды и поиск, телефонные звонки и расшифровка видео. Модель «Стандарт» лучше всего подходит для общего использования, например, для длинного аудио с одним динамиком, а модель «Видео» лучше подходит для расшифровки нескольких динамиков (и видео). На самом деле, самая новая и более дорогая модель Video работает лучше во всех настройках.
На самом деле, самая новая и более дорогая модель Video работает лучше во всех настройках.
Настройка
Пользователь может настроить количество гипотез, возвращаемых ASR, указать язык аудиофайла и включить фильтр для удаления ненормативной лексики из выходного текста. Кроме того, распознавание речи можно настроить в соответствии с конкретным контекстом, добавив так называемые подсказки — набор слов и фраз, которые, вероятно, будут произнесены, например пользовательские слова и имена, в словарь и в случаях использования голосового управления.
Точность
Франк Дернонкур сообщил, что WER Google составляет 12,1% (чистый набор данных LibriSpeech). Мы также протестировали Google Cloud Speech на образце набора данных LibriSpeech и получили WER для мужского и женского чистого голоса 17,8% и 18,8% соответственно, а также 32,5% и 25,3% для шумной среды соответственно.
Облачный API-интерфейс Microsoft Azure Speech Services помогает создавать в приложениях функции с поддержкой речи, такие как управление голосовыми командами, пользовательский диалог с использованием естественной речи, транскрипция и диктовка речи. Speech API является частью Cognitive Services (ранее Project Oxford). В своей базовой модели REST API он не поддерживает промежуточные результаты при распознавании.
Языковая поддержка
Служба преобразования речи в текст Microsoft поддерживает 95 языков и региональных вариантов, служба преобразования текста в речь поддерживает 137 языков. Службы преобразования речи в речь и речи в текст поддерживают 71 язык. Распознавание говорящего, служба, которая проверяет и идентифицирует говорящего по характеристикам голоса, доступна на 13 языках. Речевой SDK. Для более длинных аудиофайлов следует использовать пакет SDK для службы «Речь» или REST API версии 3.0 для преобразования речи в текст.
При использовании Speech SDK следует учитывать, что формат потокового аудио по умолчанию — WAV (16 кГц или 8 кГц, 16 бит), GStreamer также поддерживает другие форматы: MP3, OPUS/OGG, FLAC, ALAW в контейнере wav, MULAW в контейнере wav, ЛЮБОЙ (используется для сценария с неизвестным форматом носителя).
Цены
Преобразование речи в текст — 1 доллар США в час
Преобразование речи в текст с пользовательской моделью речи — 1,40 доллара США в час
Существует бесплатная версия для одного параллельного запроса с порогом 5 часов в месяц. Для получения более подробных планов посетите страницу с ценами здесь.
Интерфейсы
Корпорация Майкрософт предоставляет разработчикам два способа добавления Speech Services API в свои приложения:
- REST API: разработчики используют HTTP-вызовы из приложений непосредственно в службу для распознавания речи.
- Клиентские библиотеки: в качестве опции разработчики могут загрузить клиентские библиотеки Microsoft Speech и связать их со своими приложениями, чтобы получить доступ к расширенным функциям. Клиентские библиотеки используют протокол на основе Websocket и доступны на различных платформах (Windows, Android, iOS) с использованием разных языков (C#, Java, JavaScript, Objective-C).

Настройка
Служба распознавания речи позволяет пользователям адаптировать базовые модели на основе своих акустических и языковых данных, настраивая свой словарный запас, акустические модели и произношение.
На схеме представлены функции Custom Speech от Azure. Источник
Точность
Франк Дернонкур сообщил, что WER Azure составляет 18,8% (чистый набор данных LibriSpeech). Мы также протестировали службу преобразования речи в текст Microsoft на образце набора данных LibriSpeech и получили WER для мужского и женского чистого голоса 11,7% и 13,5% соответственно, а также 26% и 21,3% для шумной среды соответственно.
Amazon Transcribe — это система автоматического распознавания речи, которая, прежде всего, по умолчанию добавляет пунктуацию и форматирование, чтобы вывод был более разборчивым, и вы могли использовать его без дальнейшего редактирования.
Языковая поддержка
В настоящее время Amazon Transcribe поддерживает 31 язык, включая региональные варианты английского и французского языков.
Ввод
Amazon Transcribe поддерживает аудиопотоки 16 кГц и 8 кГц и множественное кодирование аудио, включая WAV, MP3, MP4 и FLAC с отметками времени для каждого слова, так что это возможно, как утверждает Amazon на своем веб-сайте, чтобы «легко найти аудио в исходном источнике, выполнив поиск по тексту». Вызовы службы ограничены двумя часами на вызов API.
Цены
Цены Amazon основаны на ежемесячной плате за расшифровку аудио, начиная с 0,0004 долларов США в секунду за первые 250 000 минут.
Уровень бесплатного пользования доступен в течение 12 месяцев с ограничением 60 минут в месяц.
Все подробности о ценах доступны на странице Amazon.Точность
Имея ограниченный набор языков и доступную только одну базовую модель, Amazon Transcribe показывает WER 22 %.
Служба Watson Speech to Text — это система ASR, предоставляющая услуги автоматической транскрипции.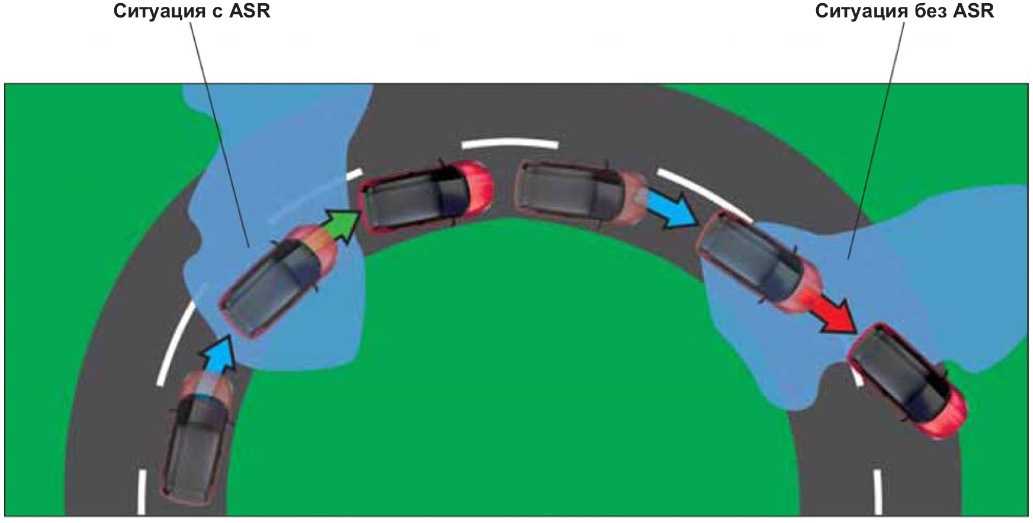 Система использует машинный интеллект для объединения информации о грамматике и структуре языка со знаниями о составе звукового сигнала для точной расшифровки человеческого голоса. По мере того, как слышится больше речи, система задним числом обновляет транскрипцию.
Система использует машинный интеллект для объединения информации о грамматике и структуре языка со знаниями о составе звукового сигнала для точной расшифровки человеческого голоса. По мере того, как слышится больше речи, система задним числом обновляет транскрипцию.
Языковая поддержка
Служба IBM Watson Speech to Text поддерживает 19 языков и вариантов.
Вход
Система поддерживает аудиопотоки 16 кГц и 8 кГц в форматах MP3, MPEG, WAV, FLAC, OUPS и других.
Цены
IBM предоставляет вам бесплатный тарифный план до 500 минут в месяц (индивидуальная настройка недоступна). Пользователи могут выполнять до 100 одновременных транскрипций за 0,02 доллара США в минуту в течение 1–9 часов.99 999 минут в месяц на тарифе Plus. Подробная информация о других планах доступна по запросу.
Интерфейсы
Служба преобразования речи в текст Watson предлагает три интерфейса:
- Интерфейс WebSocket для постоянных, полнодуплексных соединений с малой задержкой со службой.
- Синхронный HTTP-интерфейс для базовых HTTP-вызовов службы.
- Асинхронный HTTP-интерфейс для неблокирующих вызовов службы.
Настройка
Для ограниченного набора языков служба IBM Watson Speech to Text предлагает интерфейс настройки, который позволяет разработчикам расширять свои возможности распознавания речи. Вы можете повысить точность запросов на распознавание речи, настроив базовую модель для таких областей, как медицина, юриспруденция, информационные технологии и другие. Система позволяет настраивать язык и акустические модели.
Точность
Франк Дернонкур сообщил, что WER Azure равен 9,8% (чистый набор данных LibriSpeech). Мы также протестировали службу преобразования речи в текст Microsoft на образце набора данных LibriSpeech и получили WER для мужского и женского чистого голоса 17,4% и 19,6% соответственно, а 37,5% и 27,4% для шумной среды. соответственно.
SpeechMatics, как облачная, так и локальная служба со штаб-квартирой в Великобритании, использует рекуррентные нейронные сети и статистическое языковое моделирование. Сервис, предназначенный для предприятий, предлагает бесплатные и платные функции, такие как транскрипция в реальном времени и загрузка аудиофайлов.
Сервис, предназначенный для предприятий, предлагает бесплатные и платные функции, такие как транскрипция в реальном времени и загрузка аудиофайлов.
Языковая поддержка
Они охватывают 31 язык. SpeechMatics обещает справиться с такими проблемами, как шумная обстановка, разные акценты и диалекты.
Вход
Аудио- и видеоформаты, которые поддерживает данная система ASR: WAV, MP3, AAC, OGG, FLAC, WMA, MPEG, AMR, CAF, MP4, MOV, WMV, MPEG, M4V, FLV, MKV . Компания утверждает, что другие форматы также могут поддерживаться, но после дополнительного пользовательского приемочного теста.
Ценообразование
Как и большинство компаний, ориентированных на предприятия, SpeechMatics предоставляет планы и информацию о ценах по запросу. Компания использует стратегию, основанную на объемах, и предоставляет 14-дневную бесплатную пробную версию.
Индивидуальная настройка
Эта система легко настраивается — вы можете создать свой пользовательский интерфейс в соответствии с вашими потребностями.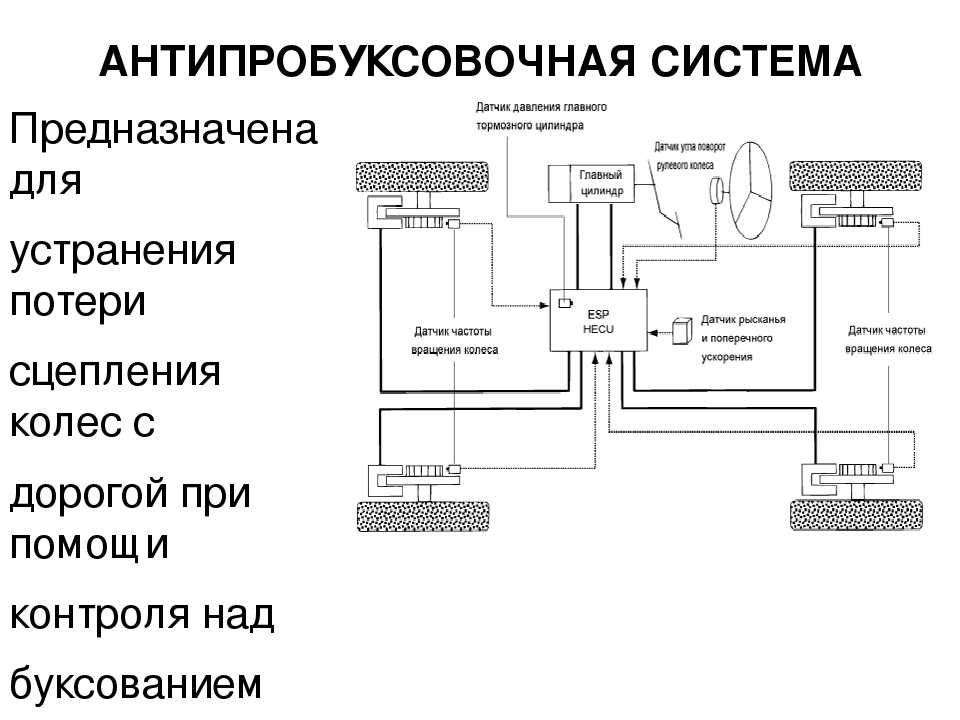 Пользовательский интерфейс по умолчанию не предоставляется, но при необходимости вы можете получить его через одного партнера. Вы можете добавить в словарь свои собственные слова и научить движок их распознавать. Вы также можете настроить систему, чтобы исключить конфиденциальную информацию или профанацию. SpeechMatics также поддерживает субтитры в реальном времени.
Пользовательский интерфейс по умолчанию не предоставляется, но при необходимости вы можете получить его через одного партнера. Вы можете добавить в словарь свои собственные слова и научить движок их распознавать. Вы также можете настроить систему, чтобы исключить конфиденциальную информацию или профанацию. SpeechMatics также поддерживает субтитры в реальном времени.
Точность
Франк Дернонкур протестировал SpeechMatics на наборе чистых тестовых данных LibriSpeech (английский) — WER 7,3%, что довольно хорошо по сравнению с другими коммерческими системами ASR.
Разнообразие систем ASR с открытым исходным кодом затрудняет поиск тех, которые сочетают гибкость с приемлемым уровнем ошибок в словах. В этом посте мы выбрали Kaldi и HTK как популярные на платформах сообщества.
Калди изначально создавался для исследователей, но быстро сделал себе имя. Kaldi — это инструментарий Университета Джона Хопкинса для распознавания речи, написанный на C++ и распространяемый под лицензией Apache License v2. 0. Известный своими результатами, которые могут конкурировать с Google и даже превзойти его, Kaldi, тем не менее, сложен в освоении и настройке для правильной работы, требуя обширной настройки и обучения на вашем корпусе.
0. Известный своими результатами, которые могут конкурировать с Google и даже превзойти его, Kaldi, тем не менее, сложен в освоении и настройке для правильной работы, требуя обширной настройки и обучения на вашем корпусе.
Поддержка языков
Kaldi не предоставляет лингвистических ресурсов, необходимых для создания распознавателя на языке, но у него есть рецепт для его создания самостоятельно. Когда вы предоставите достаточно данных, вы сможете обучить свою модель с помощью Kaldi. Вы также можете использовать некоторые готовые модели на странице Kaldi.
Ввод
Аудиофайлы принимаются в формате WAV.
Персонализация
Kaldi — это набор инструментов для создания языковых и акустических моделей для самостоятельного создания систем ASR. Он поддерживает линейные преобразования, дискриминативное обучение в пространстве признаков, глубокие нейронные сети, MMI, усиленное MMI и дискриминативное обучение MCE.
Точность
Мы протестировали Kaldi на образце набора данных LibriSpeech и получили WER для мужского и женского чистого голоса около 28%% и 28,1% соответственно, а около 46,7% и 40,2% для шумного голоса. среды соответственно.
HTK, или набор инструментов для скрытой марковской модели, написанный на языке программирования C, был разработан инженерным факультетом Кембриджского университета для работы с HMM. HTK фокусируется на распознавании речи, но вы также можете использовать его для задач преобразования текста в речь и даже для секвенирования ДНК.
Сегодня Microsoft получила авторские права на исходный код HTK, но по-прежнему поощряет внесение изменений в исходный код. Интересно, что будучи одним из старейших проектов, он до сих пор широко используется и имеет новые версии. Кроме того, у HTK есть содержательная и подробная книга под названием «HTKBook», в которой описываются как математические основы распознавания речи, так и то, как выполнять определенные действия в HTK.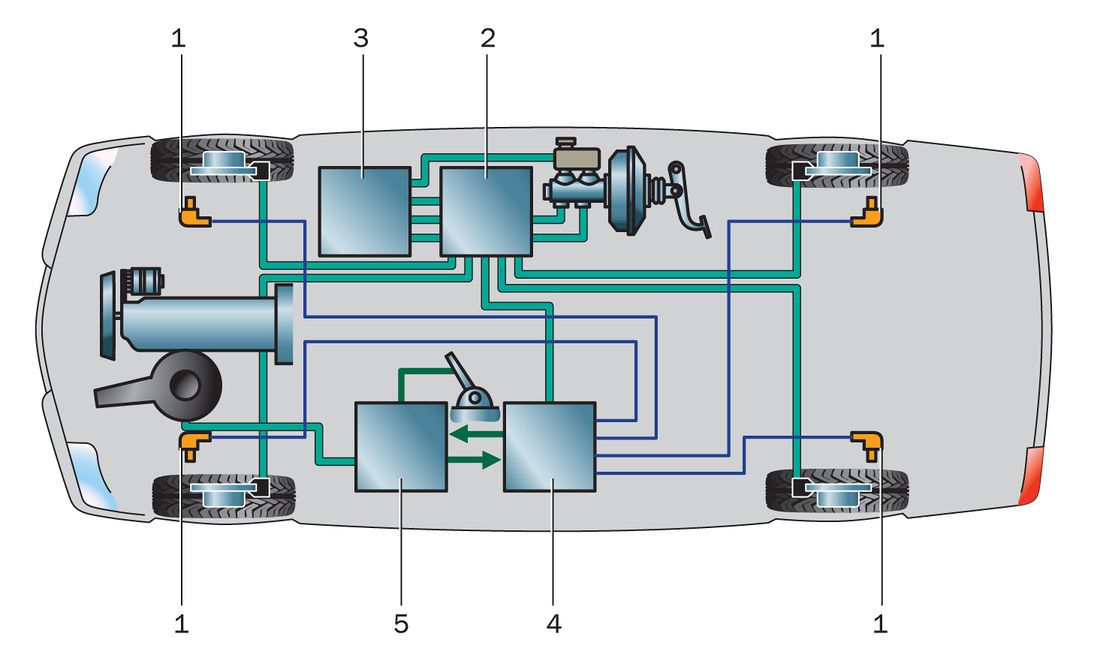
Языковая поддержка
Подобно Kaldi, HTK не зависит от языка и позволяет построить модель для каждого языка.
Ввод
По умолчанию формат речевого файла — HTK, но набор инструментов также поддерживает различные форматы. Вы можете установить параметр конфигурации SOURCEFORMAT для других форматов.
Настройка
Полностью настраиваемый, HTK предлагает обучающие инструменты для оценки параметров набора HMM с использованием обучающих высказываний и связанных с ними транскрипций и инструментов распознавания для расшифровки неизвестных высказываний.
Точность
Инструментарий был оценен с использованием известной базы данных WSJ за ноябрь 1992 года. Результат был впечатляющим: 3,2% WER при использовании модели языка триграмм на корпусе из 5000 слов. Однако в реальной жизни WER достигает 25–30%.
Используя любой набор инструментов ASR с открытым исходным кодом, оптимальным способом быстрой разработки распознавателя ASR будет использование открытого исходного кода для документов, которые имеют самые высокие результаты в известных корпусах (набор инструментов автоматического распознавания речи Facebook AI Research , реализация Tensorflow модели LAS или библиотека моделей глубокого обучения и наборов данных Tensorflow, и это лишь некоторые из них).
Технология автоматического распознавания речи существует уже некоторое время. Хотя системы совершенствуются, проблемы все еще существуют. Например, система ASR не всегда может правильно распознать ввод от человека, который говорит с сильным акцентом или диалектом или говорит на нескольких языках.
Существуют различные инструменты, как коммерческие, так и с открытым исходным кодом, для интеграции ASR в приложения компании. При выборе между ними ключевым моментом является поиск правильного баланса между обычно более высоким качеством проприетарных систем и гибкостью наборов инструментов с открытым исходным кодом.
Компании должны понимать свои ресурсы, а также потребности своего бизнеса. Если ASR используется в обычных и хорошо изученных условиях и не требует слишком много дополнительной информации, то наиболее оптимальным решением является готовая к использованию система. Наоборот, если ASR является ядром проекта, более гибкий инструментарий с открытым исходным кодом становится лучшим вариантом.
Что такое ASR? Обзор автоматического распознавания речи
Автоматическое распознавание речи, или ASR, представляет собой использование технологии машинного обучения или искусственного интеллекта (ИИ) для преобразования человеческой речи в читаемый текст. За последнее десятилетие эта область значительно расширилась: системы ASR появились в популярных приложениях, которые мы используем каждый день, таких как TikTok и Instagram для субтитров в реальном времени, Spotify для транскрипций подкастов, Zoom для транскрипций совещаний и т. д.
По мере того, как ASR быстро приближается к уровню человеческой точности, произойдет взрыв приложений, использующих преимущества технологии ASR в своих продуктах, чтобы сделать аудио- и видеоданные более доступными. Уже сейчас API преобразования речи в текст, такие как AssemblyAI, делают технологию ASR более доступной, доступной и точной.
Эта статья призвана ответить на вопрос: Что такое ASR?, а также предоставить всесторонний обзор технологии автоматического распознавания речи, включая:
- История ASR
- Как работает ASR
- Ключевые термины и функции ASR
- Основные области применения ASR
- Проблемы ASR сегодня
- На горизонте ASR
История ASR
История ASR, как мы знаем2 печально известная лаборатория Белла создала «Одри», распознаватель цифр.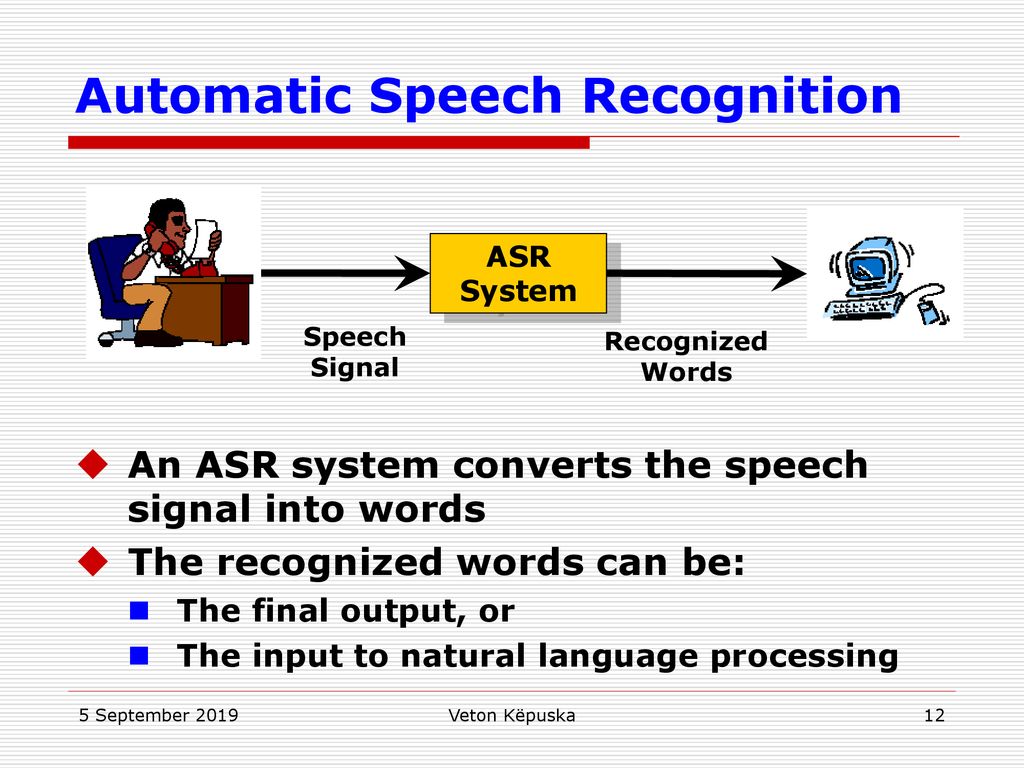 Одри могла расшифровывать только произносимые числа, но десять лет спустя исследователи улучшили Одри, чтобы она могла расшифровывать элементарные произнесенные слова, такие как «привет».
Одри могла расшифровывать только произносимые числа, но десять лет спустя исследователи улучшили Одри, чтобы она могла расшифровывать элементарные произнесенные слова, такие как «привет».На протяжении большей части последних пятнадцати лет ASR основывался на классических технологиях машинного обучения, таких как скрытые марковские модели. Хотя точность этих классических моделей когда-то была отраслевым стандартом, в последние годы она вышла на плато, что открыло двери для новых подходов, основанных на передовой технологии глубокого обучения, которая также способствовала прогрессу в других областях, таких как самоуправляемые автомобили.
В 2014 году Baidu опубликовала печально известную статью Deep Speech: масштабирование сквозного распознавания речи 9.0006 . В этой статье исследователи продемонстрировали силу применения исследований глубокого обучения для создания современных и точных систем распознавания речи. Статья положила начало возрождению в области ASR, популяризировав подход глубокого обучения и подняв точность модели за пределы плато и приблизив ее к человеческому уровню.
Не только резко возросла точность, но и значительно улучшился доступ к технологии ASR. Десять лет назад клиентам приходилось заключать длительные и дорогостоящие контракты на корпоративное программное обеспечение, чтобы лицензировать технологию ASR. Сегодня разработчики, начинающие компании и представители списка Fortune 500 имеют доступ к передовой технологии ASR через простые API, такие как Speech-to-Text API AssemblyAI.
Давайте более подробно рассмотрим эти два основных подхода к ASR.
Как работает ASR
На сегодняшний день существует два основных подхода к автоматическому распознаванию речи: традиционный гибридный подход и сквозной подход глубокого обучения.
Традиционный гибридный подход
Традиционный гибридный подход — это устаревший подход к распознаванию речи, который доминировал в этой области в течение последних пятнадцати лет. Многие компании до сих пор полагаются на этот традиционный гибридный подход просто потому, что так всегда делалось — существует больше знаний о том, как построить надежную модель, благодаря обширным доступным данным исследований и обучения, несмотря на плато в точности.
Вот как это работает:
Традиционные системы HMM и GMM
Традиционные HMM (скрытые марковские модели) и GMM (модели гауссовой смеси) требуют принудительного выравнивания данных. Принудительное выравнивание — это процесс получения текстовой транскрипции звукового речевого сегмента и определения того, где во времени встречаются определенные слова в речевом сегменте.
Как вы можете видеть на иллюстрации выше, этот подход сочетает в себе лексическую модель + акустическую модель + языковую модель для прогнозирования транскрипции.
Каждый шаг более подробно описан ниже:
Модель лексикона
Модель лексикона описывает фонетическое произношение слов. Обычно вам нужен собственный набор фонем для каждого языка, созданный опытными фонетиками вручную.
Акустическая модель
Акустическая модель (AM) моделирует акустические модели речи. Задача акустической модели состоит в том, чтобы предсказать, какой звук или фонема произносится в каждом сегменте речи, на основе принудительно выровненных данных.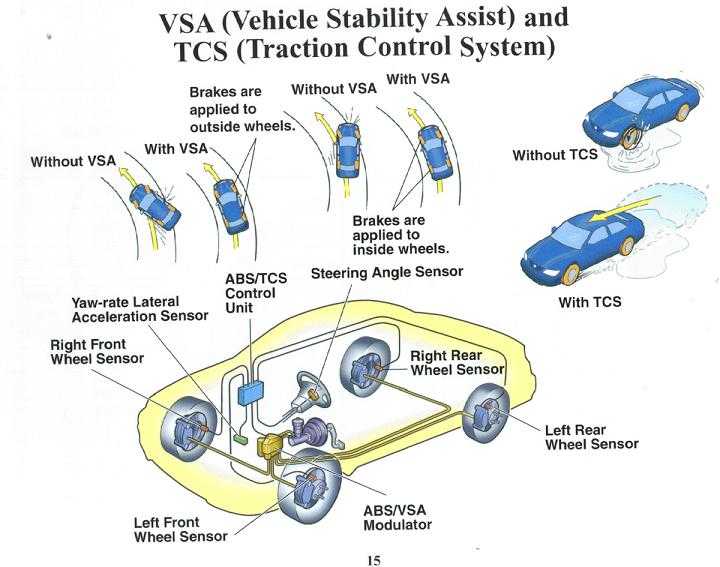 Акустическая модель обычно представляет собой вариант HMM или GMM.
Акустическая модель обычно представляет собой вариант HMM или GMM.
Модель языка
Модель языка (LM) моделирует статистику языка. Он узнает, какие последовательности слов, скорее всего, будут произнесены, и его задача — предсказать, какие слова последуют за текущими словами и с какой вероятностью.
Декодирование
Декодирование — это процесс использования лексики, акустической и языковой модели для создания стенограммы.
Недостатки традиционного гибридного подхода
Несмотря на широкое распространение, традиционный гибридный подход к распознаванию речи имеет несколько недостатков. Более низкая точность, как обсуждалось ранее, является самой большой. Кроме того, каждую модель необходимо обучать независимо, что отнимает много времени и сил. Принудительно выровненные данные также трудно получить, и требуется значительное количество человеческого труда, что делает их менее доступными. Наконец, необходимы эксперты для создания пользовательского фонетического набора, чтобы повысить точность модели.
Сквозной подход к глубокому обучению
Сквозной подход к глубокому обучению — это новый взгляд на ASR и то, как мы подходим к ASR здесь, в AssemblyAI.
Как работают сквозные модели глубокого обучения
С помощью сквозной системы вы можете напрямую преобразовать последовательность входных акустических характеристик в последовательность слов. Данные не нужно принудительно выравнивать. В зависимости от архитектуры систему глубокого обучения можно научить производить точные стенограммы без модели словаря и языковой модели, хотя языковые модели могут помочь получить более точные результаты.
См.: Обучение моделей глубокого обучения.CTC, LAS и RNNT
CTC, LAS и RNNT — популярные сквозные архитектуры глубокого обучения для распознавания речи. Эти системы могут быть обучены для получения сверхточных результатов без использования принудительно выровненных данных, моделей лексики и языковых моделей.
Узнать больше: Сравнение сквозных архитектур распознавания речиПреимущества сквозных моделей глубокого обучения
Сквозные модели глубокого обучения легче обучать и требуют меньше человеческого труда, чем традиционный подход. Они также более точны, чем традиционные модели, используемые сегодня.
Они также более точны, чем традиционные модели, используемые сегодня.
Сообщество исследователей глубокого обучения активно ищет способы постоянного улучшения этих моделей с использованием последних исследований, поэтому в ближайшее время не стоит беспокоиться о плато точности — на самом деле, мы увидим, как модели глубокого обучения достигнут точности человеческого уровня. в ближайшие несколько лет.
Ключевые термины и функции ASR
Акустическая модель: Акустическая модель принимает звуковые волны и предсказывает, какие слова присутствуют в волновой форме.
Модель языка: Языковая модель может использоваться, чтобы помочь направлять и корректировать предсказания акустических моделей.
Частота ошибок в словах : Стандартное в отрасли измерение точности транскрипции ASR по сравнению с транскрипцией человека.
Диаризация говорящего: Отвечает на вопрос, кто когда говорил? Также называется этикетками динамиков.
Пользовательский словарь : Пользовательский словарь, также называемый Word Boost, повышает точность списка определенных ключевых слов или фраз при расшифровке аудиофайла.
Анализ тональности: Тональность, обычно положительная, отрицательная или нейтральная, определенных сегментов речи в аудио- или видеофайле.
См. дополнительные функции, характерные для AssemblyAI.
Основные области применения ASR
Огромные достижения в области ASR привели к корреляции с ростом API преобразования речи в текст. Компании используют технологию ASR для приложений преобразования речи в текст в самых разных отраслях. Вот некоторые примеры:
Телефония: Отслеживание вызовов, решения для облачных телефонов и контакт-центры нуждаются в точных транскрипциях, а также в инновационных аналитических функциях, таких как Conversational Intelligence, аналитика вызовов, диаризация говорящих и многое другое.
Видеоплатформы: Асинхронные и асинхронные субтитры к видео в реальном времени являются отраслевым стандартом. Платформы (и видеоредакторы) также нуждаются в категоризации контента и модерации контента для улучшения доступности и поиска.
Медиа-мониторинг: API-интерфейсы преобразования речи в текст могут помочь транслировать телепередачи, подкасты, радио, а также быстрее и точнее обнаруживать упоминания брендов и других тем для повышения качества рекламы.
Виртуальные встречи: Платформы для проведения встреч, такие как Zoom, Google Meet, WebEx и другие, нуждаются в точных расшифровках и возможности анализировать этот контент, чтобы получать ключевые идеи и действовать.
Выбор API для преобразования речи в текст
Поскольку на рынке представлено больше API, как узнать, какой API для преобразования речи в текст лучше всего подходит для вашего приложения?
Ключевые моменты, о которых следует помнить, включают:
- Насколько точен API.

- Какие дополнительные функции предлагаются.
- На какую поддержку можно рассчитывать.
- Прозрачность ценообразования и документации.
- Безопасность данных.
- Инновации компании.
Проблемы ASR сегодня
Одной из основных проблем ASR сегодня является постоянное стремление к уровням точности человека. Хотя оба подхода ASR — традиционный гибрид и сквозное глубокое обучение — значительно более точны, чем когда-либо прежде, ни один из них не может претендовать на 100% человеческую точность. Это потому, что в том, как мы говорим, так много нюансов, от диалектов до сленга и подачи. Даже самые лучшие модели глубокого обучения не могут быть обучены охватывать весь этот длинный хвост пограничных случаев без значительных усилий.
Некоторые считают, что проблему точности можно решить с помощью пользовательских моделей преобразования речи в текст. Однако, если у вас нет очень конкретного варианта использования, такого как речь детей, пользовательские модели на самом деле менее точны, их сложнее обучать и на практике они дороже, чем хорошая сквозная модель глубокого обучения.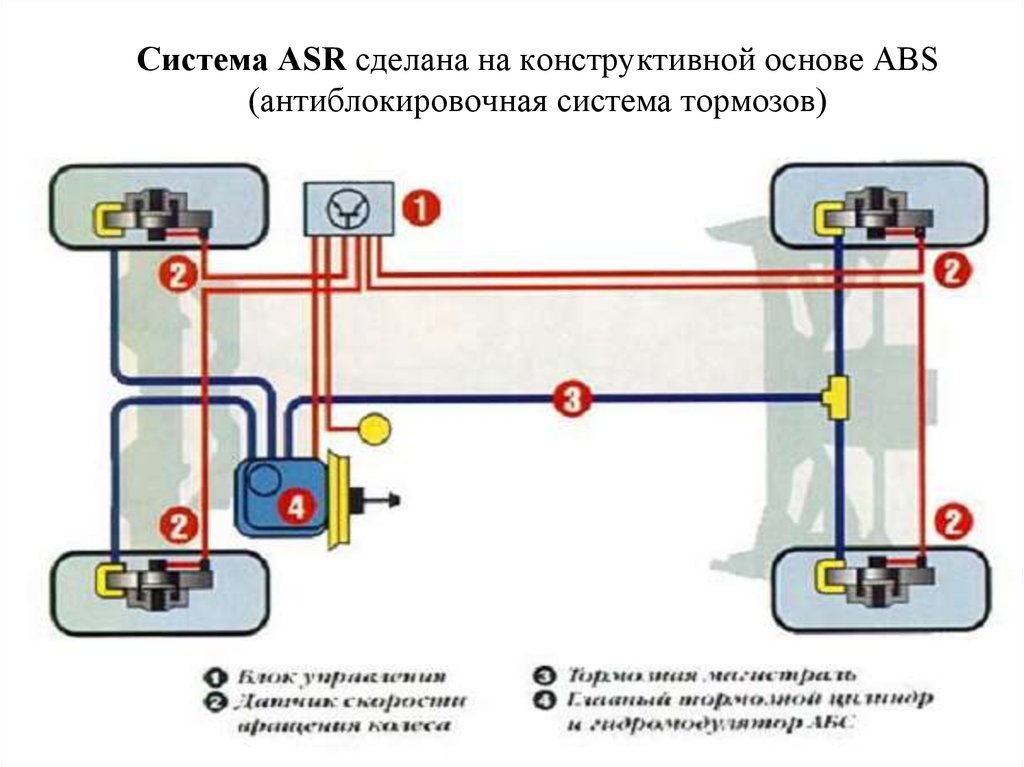
Еще одной серьезной проблемой является конфиденциальность преобразования речи в текст для API. Слишком много крупных компаний ASR используют данные клиентов для обучения моделей без явного разрешения, что вызывает серьезные опасения по поводу конфиденциальности данных. Непрерывное хранение данных в облаке также вызывает опасения по поводу потенциальных нарушений безопасности, особенно если необработанные аудио- или видеофайлы или текст транскрипции содержат личную информацию.
На горизонте для ASR
Поскольку область ASR продолжает расти, мы можем ожидать большей интеграции технологии преобразования речи в текст в нашу повседневную жизнь, а также более широкое применение в промышленности.
Что касается построения моделей, мы также ожидаем увидеть переход к самоконтролируемой системе обучения для решения некоторых проблем с точностью, описанной выше.
Сквозные модели глубокого обучения нуждаются в данных. Например, наша модель ASR в AssemblyAI обучается на 100 000 часов необработанных аудио- и видеоданных для обучения, что обеспечивает лучший в отрасли уровень точности.