Что такое искусственные нейронные сети? Виды, модели и задачи
Главная
Нейронные сети
Нейронные сети — вычислительные системы или машины, созданные для моделирования аналитических действий, совершаемых человеческим мозгом.
Нейронные сети относятся к направлению искусственного интеллекта (ИИ) и применяются для распознавания скрытых закономерностей в необработанных данных, группировки и классификации, а также решения задач в области ИИ, машинного и глубокого обучения.
Принцип работы нейронных сетей
Искусственные нейронные сети состоят из нескольких слоев:
- входных;
- скрытых;
- выходных.
В каждом из них есть несколько узлов, которые соединены со всеми узлами в сети с помощью разных связей и имеют свой «вес», влияющий на силу передаваемого сигнала.
Такая архитектура позволяет вести параллельную обработку данных и постоянно сравнивать их с результатами обработки на каждом из этапов.
Нейронные сети изначально обучаются на размеченных наборах данных с очевидными закономерностями, а после используют полученные навыки для самообучения и достижения результата.
При этом нейросеть может совершать миллионы попыток для достижения таких же результатов, как и предоставленном для обучения примере.
Примечание: Работа нейронной сети сравнима с действиями человека: сталкиваясь с незнакомым предметом, он узнает его свойства и делает выводы. Аналогичные процессы происходят в узлах нейросетей, когда решая определенную задачу, они используют полученный опыт для дальнейшего обучения.
Виды нейронных сетей
Есть десятки видов нейросетей, которые отличаются архитектурой, особенностями функционирования и сферами применения. При этом чаще других встречаются сети трех видов.
Нейронные сети прямого распространения (Feed forward neural networks, FFNN). Прямолинейный вид нейросетей, при котором соседние узлы слоя не связаны, а передача информации осуществляется напрямую от входного слоя к выходному. FFNN имеют малую функциональность, поэтому часто используются в комбинации с сетями других видов.
FFNN имеют малую функциональность, поэтому часто используются в комбинации с сетями других видов.
Сверточные нейронные сети (Convolutional neural network, CNN). Состоят из слоев пяти типов:
- входного;
- свертывающего;
- объединяющего;
- подключенного;
- выходного.
Каждый слой выполняет определенную задачу: например, обобщает или соединяет данные.
Сверточные нейросети применяются для классификации изображений, распознавания объектов, прогнозирования, обработки естественного языка и других задач.
Рекуррентные нейронные сети (Recurrent neural network, RNN). Используют направленную последовательность связи между узлами. В RNN результат вычислений на каждом этапе используется в качестве исходных данных для следующего. Благодаря этому, рекуррентные нейронные сети могут обрабатывать серии событий во времени или последовательности для получения результата вычислений.
RNN применяют для языкового моделирования и генерации текстов, машинного перевода, распознавания речи и других задач.
Типы задач, которые решают нейронные сети
Выделяют несколько базовых типов задач, для решения которых могут использоваться нейросети.
- Классификация. Для распознавания лиц, эмоций, типов объектов: например, квадратов, кругов, треугольников. Также для распознавания образов, то есть выбора конкретного объекта из предложенного множества: например, выбор квадрата среди треугольников.
- Регрессия. Для определения возраста по фотографии, составления прогноза биржевых курсов, оценки стоимости имущества и других задач, требующих получения в результате обработки конкретного числа.
- Прогнозирования временных рядов. Для составления долгосрочных прогнозов на основе динамического временного ряда значений. Например, нейросети применяются для предсказания цен, физических явлений, объема потребления и других показателей. По сути, даже работу автопилота Tesla можно отнести к процессу прогнозирования временных рядов.
- Кластеризация. Для изучения и сортировки большого объема неразмеченных данных в условиях, когда неизвестно количество классов на выходе, то есть для объединения данных по признакам.
 Например, кластеризация применяется для выявления классов картинок и сегментации клиентов.
Например, кластеризация применяется для выявления классов картинок и сегментации клиентов. - Генерация. Для автоматизированного создания контента или его трансформации. Генерация с помощью нейросетей применяется для создания уникальных текстов, аудиофайлов, видео, раскрашивания черно-белых фильмов и даже изменения окружающей среды на фото.
Примечание: Например, нейронная сеть ruDALL-E, может генерировать уникальные изображения на основе текстового описания.
Персональный менеджер
Преимущества
Поддержка для каждого клиента
Личный менеджер грамотно проконсультирует, окажет поддержку при запуске новых продуктов и сэкономит ваше рабочее время.
Круглосуточная техническая поддержка
Мы готовы решать ваши вопросы и оказывать поддержку 24/7.
Математическая модель нейрона и функции активации
Математическая модель нейрона Маккаллока — Питтса разработана по аналогии с биологическими нервными клетками и выглядит следующим образом:
Где:
X — входные данные — сигналы, поступающие к нейрону;
W — вес — эквивалент синаптической связи, представленный в виде действительного числа, на которое умножается значение входного сигнала для определения степени взаимосвязи отдельных нейронов;
H — тело нейрона — показатель накопленной взвешенной суммы, полученной в результате умножения значений входящих сигналов на вес;
Y — выход нейронной сети — функция, получаемая в результате обработки входных сигналов.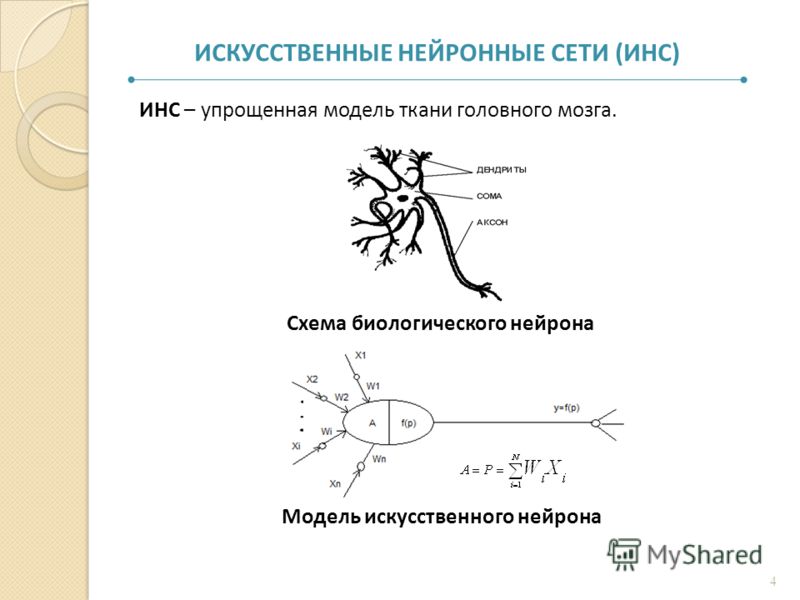
Примечание: При такой модели обучение нейронной сети сводится к изменению коэффициенту весов, то есть связи между отдельными нейронами. Если вес положительный — сигнал в нейроне усиливается, нулевой — нейроны не влияют друг на друга, отрицательный — сигнал в принимающем нейроне погашается.
Функции активации
Для определения выходных значений нейрона используются функции активации разного вида, каждая из которых влияет на работу нейронных сетей и отличается принципом оценки или преобразования данных.
Так:
- Функция Хевисайда преобразовывает значения при их накоплении выше установленного порога. Например, значение +100 преобразовывается в 1, а -100 — в 0.
- Пороговая функция. Применяется для отображения состояния нейрона: его возбудимости или спокойствия. Может отображать только два значения: 0% и 100%.
- Синоидальные функции применяются для сглаживания значений.
- Функция ReLU отсекает только отрицательные значения.
 Например, значение -100 преобразовывается в 0, а +50 остается неизменным.
Например, значение -100 преобразовывается в 0, а +50 остается неизменным.
Функция ReLu производит простые математические операции, поэтому помогает снизить нагрузку на вычислительные мощности при глубоком обучении.
Типы обучения
Нейросети, в отличие от других алгоритмов ИИ, не программируются на выполнение конкретных задач, а просто настраиваются на изучение информации.
Стратегия обучения нейронных сетей базируется на трех методах:
- Контролируемое обучение. Классическая модель обучения, в которой используется набор размеченных данных, показывающий алгоритму что и как должно быть. Обучение продолжается до полного перестраивания алгоритма под решение конкретных задач и получения нужного результата.
- Обучение без контроля. Стратегия обучения, применяемая в ситуациях, когда нет размеченных наборов данных. В этой модели нейронная сеть выполняет анализ, а после получает внутренний отчет о точности расчета.
 Если значение недостаточно, нейронная сеть усиливается и повторяет операцию.
Если значение недостаточно, нейронная сеть усиливается и повторяет операцию. - Усиленное обучение. Модель, при которой нейронная сеть усиливается при получении положительного результата и наказывается за неправильные расчеты.
Мы предлагаем готовые решения для работы с искусственным интеллектом, машинным обучением и нейронными сетями. Клиентам доступны платформа для совместной ML-разработки с ускорением до +1700 GPU Tesla v100 и A100 ML Space, инструменты для обработки языка ruGPT-3 & family и другие сервисы.
Связанные материалы
- Машинное обучение
- Искусственный интеллект
- Data Science
Что такое нейронная сеть? – Объяснение искусственной нейронной сети – AWS
Что такое нейронная сеть?
Нейронная сеть — это метод в искусственном интеллекте, который учит компьютеры обрабатывать данные таким же способом, как и человеческий мозг. Это тип процесса машинного обучения, называемый глубоким обучением, который использует взаимосвязанные узлы или нейроны в слоистой структуре, напоминающей человеческий мозг. Он создает адаптивную систему, с помощью которой компьютеры учатся на своих ошибках и постоянно совершенствуются. Таким образом, искусственные нейронные сети пытаются решать сложные задачи, такие как резюмирование документов или распознавание лиц, с более высокой точностью.
Он создает адаптивную систему, с помощью которой компьютеры учатся на своих ошибках и постоянно совершенствуются. Таким образом, искусственные нейронные сети пытаются решать сложные задачи, такие как резюмирование документов или распознавание лиц, с более высокой точностью.
В чем заключается важность нейронных сетей?
Нейронные сети помогают компьютерам принимать разумные решения с ограниченным участием человека. Они могут изучать и моделировать отношения между нелинейными и сложными входными и выходными данными. Например, нейронные сети могут выполнять следующие задачи.
Обобщать и делать выводы
Нейронные сети могут понимать неструктурированные данные и делать общие наблюдения без специального обучения. Например, они могут распознать, что два разных входных предложения имеют одинаковое значение:
- Не подскажете как произвести оплату?
- Как мне перевести деньги?
Нейронная сеть поймет, что оба предложения означают одно и то же. Также она может определить, что Бакстер-роуд — это место, а Бакстер Смит — это имя человека.
Также она может определить, что Бакстер-роуд — это место, а Бакстер Смит — это имя человека.
Для чего используются нейронные сети?
Нейронные сети распространены во множестве отраслей. В их числе:
- Диагностика с помощью классификации медицинских изображений
- Целевой маркетинг с помощью фильтрации социальных сетей и анализа поведенческих данных
- Финансовые прогнозы с помощью обработки исторических данных финансовых инструментов
- Прогнозирование электрической нагрузки и потребности в энергии
- Контроль соответствия требованиям и качества
- Определение химических соединений
Ниже представлены четыре важнейших задачи, которые помогают решить нейронные сети.
Машинное зрение
Машинное зрение — это способность компьютеров извлекать информацию и смысл из изображений и видео. С помощью нейронных сетей компьютеры могут различать и распознавать изображения так, как это делают люди.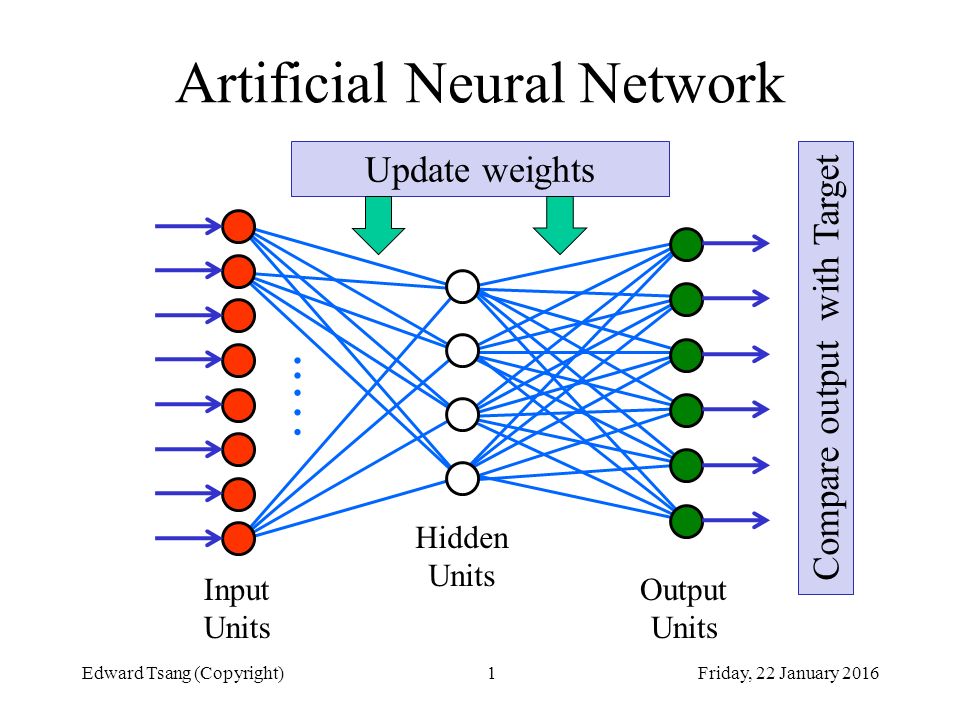 Машинное зрение применяется в нескольких областях, например:
Машинное зрение применяется в нескольких областях, например:
- Визуальное распознавание в беспилотных автомобилях, чтобы они могли реагировать на дорожные знаки и других участников движения
- Модерация контента для автоматического удаления небезопасного или неприемлемого контента из архивов изображений и видео
- Распознавание лиц для идентификации людей и распознавания таких атрибутов, как открытые глаза, очки и растительность на лице
- Маркировка изображения для идентификации логотипов бренда, одежды, защитного снаряжения и других деталей изображения
Распознавание речи
Нейронные сети могут анализировать человеческую речь независимо от ее речевых моделей, высоты, тона, языка и акцента. Виртуальные помощники, такие как Amazon Alexa и программное обеспечение для автоматической транскрипции, используют распознавание речи для выполнения следующих задач:
- Помощь операторам колл-центра и автоматическая классификация звонков
- Преобразование клинических рекомендаций в документацию в режиме реального времени
- Точные субтитры к видео и записям совещаний для более широкого охвата контента
Обработка естественного языка
Обработка естественного языка (NLP) — это способность обрабатывать естественный, созданный человеком текст.
- Автоматизированные виртуальные агенты и чат-боты
- Автоматическая организация и классификация записанных данных
- Бизнес-аналитика длинных документов: например, электронных писем и форм
- Индексация ключевых фраз, указывающих на настроение: например, положительных и отрицательных комментариев в социальных сетях
- Обобщение документов и генерация статей по заданной теме
Сервисы рекомендаций
Нейронные сети могут отслеживать действия пользователей для разработки персонализированных рекомендаций. Они также могут анализировать все действия пользователей и обнаруживать новые продукты или услуги, которые интересуют конкретного потребителя. Например, стартап из Филадельфии Curalate помогает брендам конвертировать сообщения в социальных сетях в продажи. Бренды используют службу интеллектуальной маркировки продуктов (IPT) Curalate для автоматизации сбора и обработки контента пользователей социальных сетей. IPT использует нейронные сети для автоматического поиска и рекомендации продуктов, соответствующих активности пользователя в социальных сетях. Потребителям не нужно рыться в онлайн-каталогах, чтобы найти конкретный продукт по изображению в социальных сетях. Вместо этого они могут использовать автоматическую маркировку Curalate, чтобы с легкостью приобрести продукт.
Бренды используют службу интеллектуальной маркировки продуктов (IPT) Curalate для автоматизации сбора и обработки контента пользователей социальных сетей. IPT использует нейронные сети для автоматического поиска и рекомендации продуктов, соответствующих активности пользователя в социальных сетях. Потребителям не нужно рыться в онлайн-каталогах, чтобы найти конкретный продукт по изображению в социальных сетях. Вместо этого они могут использовать автоматическую маркировку Curalate, чтобы с легкостью приобрести продукт.
Как работают нейронные сети?
Архитектура нейронных сетей повторяет структуру человеческого мозга. Клетки человеческого мозга, называемые нейронами, образуют сложную сеть с высокой степенью взаимосвязи и посылают друг другу электрические сигналы, помогая людям обрабатывать информацию. Точно так же искусственная нейронная сеть состоит из искусственных нейронов, которые взаимодействуют для решения проблем. Искусственные нейроны — это программные модули, называемые узлами, а искусственные нейронные сети — это программы или алгоритмы, которые используют вычислительные системы для выполнения математических вычислений.
Архитектура базовой нейронной сети
Базовая нейронная сеть содержит три слоя взаимосвязанных искусственных нейронов:
Входной слой
Информация из внешнего мира поступает в искусственную нейронную сеть из входного слоя. Входные узлы обрабатывают данные, анализируют или классифицируют их и передают на следующий слой.
Скрытый слой
Скрытые слои получают входные данные от входного слоя или других скрытых слоев. Искусственные нейронные сети могут иметь большое количество скрытых слоев. Каждый скрытый слой анализирует выходные данные предыдущего слоя, обрабатывает их и передает на следующий слой.
Выходной слой
Выходной слой дает окончательный результат обработки всех данных искусственной нейронной сетью. Он может иметь один или несколько узлов. Например, при решении задачи двоичной классификации (да/нет) выходной слой будет иметь один выходной узел, который даст результат «1» или «0». Однако в случае множественной классификации выходной слой может состоять из более чем одного выходного узла.
Архитектура глубокой нейронной сети
Глубокие нейронные сети или сети глубокого обучения имеют несколько скрытых слоев с миллионами связанных друг с другом искусственных нейронов. Число, называемое весом, указывает на связи одного узла с другими. Вес является положительным числом, если один узел возбуждает другой, или отрицательным, если один узел подавляет другой. Узлы с более высокими значениями веса имеют большее влияние на другие узлы.
Теоретически глубокие нейронные сети могут сопоставлять любой тип ввода с любым типом вывода. Однако стоит учитывать, что им требуется гораздо более сложное обучение, чем другим методам машинного обучения. Таким узлам нужны миллионы примеров обучающих данных, а не сотни или тысячи, как в случае с простыми сетями.
Какие типы нейронных сетей существуют?
Искусственные нейронные сети можно классифицировать по тому, как данные передаются от входного узла к выходному узлу. Ниже приведены несколько примеров.
Нейронные сети прямого распространения
Нейронные сети прямого распространения обрабатывают данные в одном направлении, от входного узла к выходному узлу. Каждый узел одного слоя связан с каждым узлом следующего слоя. Нейронные сети прямого распространения используют процесс обратной связи для улучшения прогнозов с течением времени.
Каждый узел одного слоя связан с каждым узлом следующего слоя. Нейронные сети прямого распространения используют процесс обратной связи для улучшения прогнозов с течением времени.
Алгоритм обратного распространения
Искусственные нейронные сети постоянно обучаются, используя корректирующие циклы обратной связи для улучшения своей прогностической аналитики. Проще говоря, речь идет о данных, протекающих от входного узла к выходному узлу по множеству различных путей в нейронной сети. Правильным является только один путь, который сопоставляет входной узел с правильным выходным узлом. Чтобы найти этот путь, нейронная сеть использует петлю обратной связи, которая работает следующим образом:
- Каждый узел делает предположение о следующем узле на пути.
- Он проверяет, является ли предположение правильным. Узлы присваивают более высокие значения веса путям, которые приводят к более правильным предположениям, и более низкие значения веса путям узлов, которые приводят к неправильным предположениям.
- Для следующей точки данных узлы делают новый прогноз, используя пути с более высоким весом, а затем повторяют шаг 1.
Сверточные нейронные сети
Скрытые слои в сверточных нейронных сетях выполняют определенные математические функции (например, суммирование или фильтрацию), называемые свертками. Они очень полезны для классификации изображений, поскольку могут извлекать из них соответствующие признаки, полезные для распознавания и классификации. Новую форму легче обрабатывать без потери функций, которые имеют решающее значение для правильного предположения. Каждый скрытый слой извлекает и обрабатывает различные характеристики изображения: границы, цвет и глубину.
Как обучать нейронные сети?
Обучение нейронной сети — это процесс обучения нейронной сети выполнению задачи. Нейронные сети обучаются путем первичной обработки нескольких больших наборов размеченных или неразмеченных данных. На основе этих примеров сети могут более точно обрабатывать неизвестные входные данные.
Контролируемое обучение
При контролируемом обучении специалисты по работе с данными предлагают искусственным нейронным сетям помеченные наборы данных, которые заранее дают правильный ответ. Например, сеть глубокого обучения, обучающаяся распознаванию лиц, обрабатывает сотни тысяч изображений человеческих лиц с различными терминами, связанными с этническим происхождением, страной или эмоциями, описывающими каждое изображение.
Нейронная сеть медленно накапливает знания из этих наборов данных, которые заранее дают правильный ответ. После обучения сеть начинает делать предположения об этническом происхождении или эмоциях нового изображения человеческого лица, которое она никогда раньше не обрабатывала.
Что такое глубокое обучение в контексте нейронных сетей?
Искусственный интеллект — это область компьютерных наук, которая исследует методы предоставления машинам возможности выполнять задачи, требующие человеческого интеллекта. Машинное обучение — это метод искусственного интеллекта, который дает компьютерам доступ к очень большим наборам данных для дальнейшего обучения. Программное обеспечение для машинного обучения находит шаблоны в существующих данных и применяет эти шаблоны к новым данным для принятия разумных решений. Глубокое обучение — это разновидность машинного обучения, в котором для обработки данных используются сети глубокого обучения.
Программное обеспечение для машинного обучения находит шаблоны в существующих данных и применяет эти шаблоны к новым данным для принятия разумных решений. Глубокое обучение — это разновидность машинного обучения, в котором для обработки данных используются сети глубокого обучения.
Машинное обучение и глубокое обучение
Традиционные методы машинного обучения требуют участия человека, чтобы программное обеспечение работало должным образом. Специалист по работе с данными вручную определяет набор соответствующих функций, которые должно анализировать программное обеспечение. Это ограничение делает создание и управление программным обеспечением утомительным и трудозатратным процессом.
С другой стороны, при глубоком обучении специалист по работе с данными предоставляет программному обеспечению только необработанные данные. Сеть глубокого обучения извлекает функции самостоятельно и обучается более независимо. Она может анализировать неструктурированные наборы данных (например, текстовые документы), определять приоритеты атрибутов данных и решать более сложные задачи.
Например, при обучении программного обеспечения с алгоритмами машинного обучения правильно идентифицировать изображение домашнего животного вам потребуется выполнить следующие шаги:
- Найти и вручную отметить тысячи изображений домашних животных: кошек, собак, лошадей, хомяков, попугаев и т. д.
- Сообщить программному обеспечению с алгоритмами машинного обучения, какие функции необходимо найти, чтобы оно могло идентифицировать изображение методом исключения. Например, оно может подсчитать количество ног, а затем проверить форму глаз, ушей, хвоста, цвет меха и так далее.
- Вручную оценить и изменить помеченные наборы данных, чтобы повысить точность программного обеспечения. Например, если в вашем тренировочном наборе слишком много изображений черных кошек, программное обеспечение правильно определит черную кошку, но не белую.
- При глубоком обучении нейронные сети будут обрабатывать все изображения и автоматически определять, что сначала им требуется проанализировать количество ног и форму морды, а уже после посмотреть на хвосты, чтобы правильно идентифицировать животное на изображении.

Что такое сервисы глубокого обучения в AWS?
Сервисы глубокого обучения AWS используют возможности облачных вычислений, чтобы вы могли масштабировать свои нейронные сети глубокого обучения с меньшими затратами и оптимизировать их для повышения скорости. Вы также можете использовать подобные сервисы AWS для полного управления конкретными приложениями глубокого обучения:
- Amazon Rekognition для добавления предварительно обученных или настраиваемых функций машинного зрения в ваше приложение.
- Amazon Transcribe для автоматического распознавания и точной расшифровки речи.
- Amazon Lex для создания интеллектуальных чат-ботов, которые понимают намерения, поддерживают диалоговый контекст и автоматизируют простые задачи на разных языках.
Начните работу с нейронными сетями глубокого обучения в AWS с помощью Amazon SageMaker, чтобы быстро и легко создавать, обучать и развертывать модели в любом масштабе.
Создайте бесплатный аккаунт AWS, чтобы начать работу уже сегодня.
Объяснение: Нейронные сети | MIT News
За последние 10 лет самые эффективные системы искусственного интеллекта, такие как распознаватели речи на смартфонах или новейший автоматический переводчик Google, стали результатом техники, называемой «глубокое обучение».
Глубокое обучение на самом деле является новым названием подхода к искусственному интеллекту, называемого нейронными сетями, который то входит в моду, то выходит из моды уже более 70 лет. Впервые нейронные сети были предложены в 1944 Уоррена Маккалоу и Уолтера Питтса, двух исследователей из Чикагского университета, переехавших в Массачусетский технологический институт в 1952 году в качестве основателей того, что иногда называют первым отделом когнитивных наук.
Нейронные сети были важной областью исследований как в нейронауке, так и в информатике до 1969 года, когда, согласно знаниям в области информатики, они были уничтожены математиками Массачусетского технологического института Марвином Мински и Сеймуром Пейпертом, которые год спустя станут содиректорами. новой Лаборатории искусственного интеллекта Массачусетского технологического института.
новой Лаборатории искусственного интеллекта Массачусетского технологического института.
Эта техника возродилась в 1980-х годах, снова погрузилась в затмение в первом десятилетии нового века и вернулась во втором веке, во многом благодаря возросшей вычислительной мощности графических чипов.
«Существует представление о том, что идеи в науке чем-то напоминают эпидемии вирусов», — говорит Томасо Поджио, профессор Юджина Макдермотта, профессор кафедры мозга и когнитивных наук в Массачусетском технологическом институте, исследователь Института исследований мозга Макговерна в Массачусетском технологическом институте и директор Центра Массачусетского технологического института. для мозгов, разума и машин. «Очевидно, существует пять или шесть основных штаммов вирусов гриппа, и, по-видимому, каждый из них возвращается с периодом около 25 лет. Люди заражаются, у них вырабатывается иммунный ответ, и поэтому они не заражаются следующие 25 лет. А потом появляется новое поколение, готовое к заражению тем же штаммом вируса. В науке люди влюбляются в идею, воодушевляются ею, забивают ее до смерти, а затем делают прививку — они устают от нее. Так что идеи должны иметь такую же периодичность!»
В науке люди влюбляются в идею, воодушевляются ею, забивают ее до смерти, а затем делают прививку — они устают от нее. Так что идеи должны иметь такую же периодичность!»
Важные вопросы
Нейронные сети — это средство машинного обучения, при котором компьютер учится выполнять какую-либо задачу, анализируя обучающие примеры. Обычно образцы заранее размечаются вручную. Система распознавания объектов, например, может получать тысячи помеченных изображений автомобилей, домов, кофейных чашек и т. д., и она будет находить визуальные закономерности в изображениях, которые постоянно коррелируют с определенными этикетками.
Вольно смоделированная на человеческий мозг, нейронная сеть состоит из тысяч или даже миллионов простых узлов обработки, тесно связанных между собой. Большинство современных нейронных сетей организованы в виде слоев узлов, и они имеют «упреждающую связь», что означает, что данные проходят через них только в одном направлении. Отдельный узел может быть подключен к нескольким узлам нижнего уровня, от которых он получает данные, и к нескольким узлам верхнего уровня, которым он отправляет данные.
Каждому входящему соединению узел присваивает номер, известный как «вес». Когда сеть активна, узел получает другой элемент данных — другое число — по каждому из своих соединений и умножает его на соответствующий вес. Затем он складывает полученные продукты вместе, получая одно число. Если это число ниже порогового значения, узел не передает данные на следующий уровень. Если число превышает пороговое значение, узел «срабатывает», что в современных нейронных сетях обычно означает отправку числа — суммы взвешенных входных данных — по всем его исходящим соединениям.
При обучении нейронной сети все ее веса и пороги изначально устанавливаются случайными. Обучающие данные подаются на нижний слой — входной слой — и проходят через последующие слои, умножаясь и складываясь сложным образом, пока, наконец, радикально не преобразовываясь, не достигают выходного слоя. Во время обучения веса и пороговые значения постоянно корректируются до тех пор, пока данные обучения с одинаковыми метками не будут постоянно давать одинаковые результаты.
Разум и машины
Нейронные сети, описанные Маккалоу и Питтсом в 1944 году, имели пороги и веса, но не были разделены на слои, и исследователи не указали какой-либо механизм обучения. Маккалоу и Питтс показали, что нейронная сеть, в принципе, может вычислить любую функцию, которую может выполнить цифровой компьютер. Результатом стала скорее нейронаука, чем компьютерная наука: цель состояла в том, чтобы предположить, что человеческий мозг можно рассматривать как вычислительное устройство.
Нейронные сети продолжают оставаться ценным инструментом нейробиологических исследований. Например, определенные сетевые макеты или правила для настройки весов и порогов воспроизводят наблюдаемые особенности человеческой нейроанатомии и познания, что указывает на то, что они что-то фиксируют в том, как мозг обрабатывает информацию.
Первая обучаемая нейронная сеть, персептрон, была продемонстрирована психологом Корнельского университета Фрэнком Розенблаттом в 1957 году.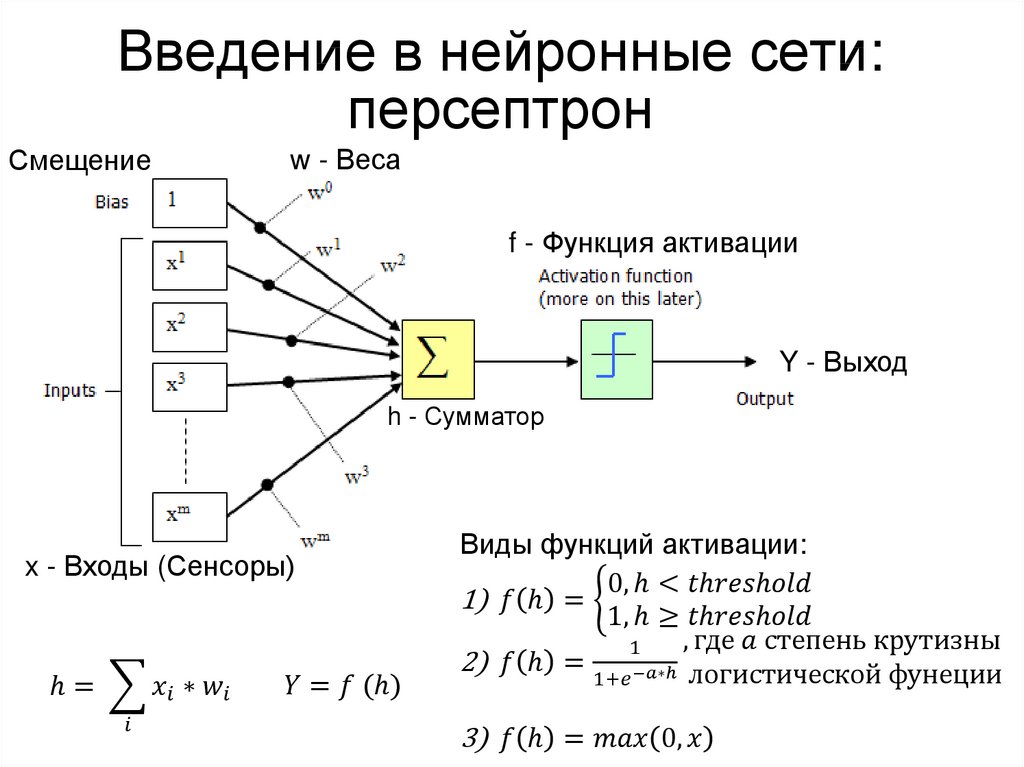 Конструкция персептрона была очень похожа на современную нейронную сеть, за исключением того, что он имел только один слой с регулируемыми весами и порогами, зажатыми между собой. между входным и выходным слоями.
Конструкция персептрона была очень похожа на современную нейронную сеть, за исключением того, что он имел только один слой с регулируемыми весами и порогами, зажатыми между собой. между входным и выходным слоями.
Персептроны были активной областью исследований как в психологии, так и в зарождающейся дисциплине компьютерных наук до 1959 года, когда Мински и Пейперт опубликовали книгу под названием «Персептроны», в которой продемонстрировано, что выполнение некоторых довольно распространенных вычислений на персептронах будет занимать непрактично много времени.
«Конечно, все эти ограничения как бы исчезают, если вы берете более сложное оборудование — например, двухслойное», — говорит Поджо. Но в то время книга оказала сдерживающее воздействие на исследования нейронных сетей.
«Вы должны поместить эти вещи в исторический контекст», — говорит Поджо. «Они выступали за программирование — за такие языки, как Лисп. Не так много лет назад люди все еще использовали аналоговые компьютеры. В то время было совсем не ясно, что программирование — это правильный путь. Я думаю, что они немного переборщили, но, как обычно, это не черное и белое. Если вы думаете об этом как о соревновании между аналоговыми и цифровыми вычислениями, они боролись за то, что в то время было правильным».
В то время было совсем не ясно, что программирование — это правильный путь. Я думаю, что они немного переборщили, но, как обычно, это не черное и белое. Если вы думаете об этом как о соревновании между аналоговыми и цифровыми вычислениями, они боролись за то, что в то время было правильным».
Периодичность
Однако к 1980-м годам исследователи разработали алгоритмы для модификации весов и пороговых значений нейронных сетей, которые были достаточно эффективны для сетей с более чем одним слоем, устраняя многие ограничения, выявленные Мински и Пейпертом. Область пережила ренессанс.
Но с интеллектуальной точки зрения в нейронных сетях есть что-то неудовлетворительное. Достаточное обучение может изменить настройки сети до такой степени, что она сможет с пользой классифицировать данные, но что означают эти настройки? На какие особенности изображения смотрит распознаватель объектов и как он собирает их вместе в отличительные визуальные сигнатуры автомобилей, домов и кофейных чашек? Взгляд на веса отдельных соединений не даст ответа на этот вопрос.
В последние годы ученые-компьютерщики начали изобретать оригинальные методы вывода аналитических стратегий, принятых нейронными сетями. Но в 1980-х стратегии сетей были не поддаются расшифровке. Итак, на рубеже веков нейронные сети были вытеснены машинами опорных векторов — альтернативным подходом к машинному обучению, основанным на очень чистой и элегантной математике.
Недавнее возрождение нейронных сетей — революция глубокого обучения — произошло благодаря индустрии компьютерных игр. Сложные изображения и быстрый темп современных видеоигр требуют аппаратного обеспечения, способного идти в ногу со временем, и результатом стал графический процессор (GPU), который объединяет тысячи относительно простых вычислительных ядер на одном чипе. Исследователям не потребовалось много времени, чтобы понять, что архитектура графического процессора очень похожа на архитектуру нейронной сети.
Современные графические процессоры позволили одноуровневым сетям 1960-х годов и двух- или трехуровневым сетям 1980-х превратиться в современные 10-, 15- и даже 50-уровневые сети.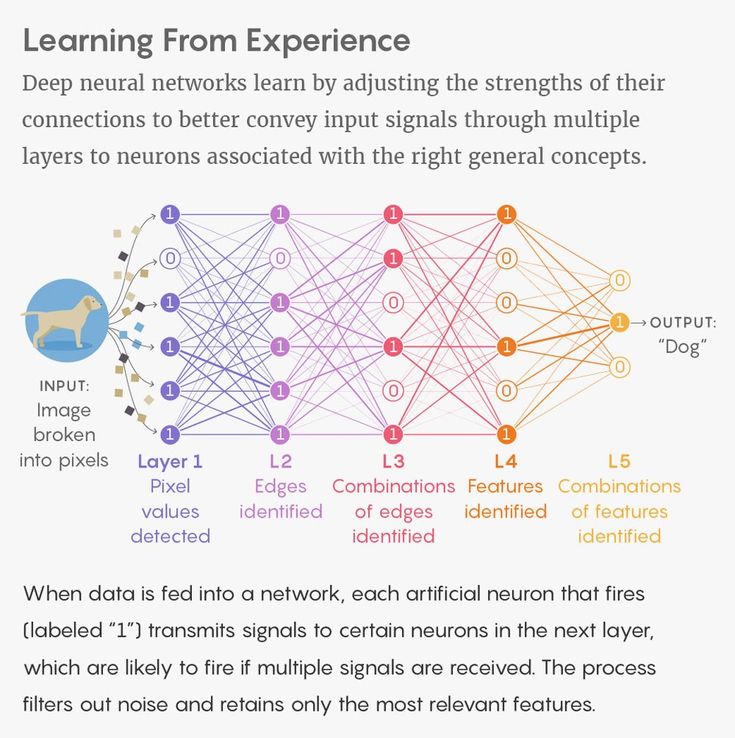 Вот что означает «глубокое» в «глубоком обучении» — глубина слоев сети. И в настоящее время глубокое обучение отвечает за самые эффективные системы почти во всех областях исследований искусственного интеллекта.
Вот что означает «глубокое» в «глубоком обучении» — глубина слоев сети. И в настоящее время глубокое обучение отвечает за самые эффективные системы почти во всех областях исследований искусственного интеллекта.
Под капотом
Непрозрачность сетей все еще беспокоит теоретиков, но и на этом фронте есть подвижки. Помимо руководства Центром мозга, разума и машин (CBMM), Поджо руководит исследовательской программой центра в области теоретических основ интеллекта. Недавно Поджо и его коллеги из CBMM выпустили теоретическое исследование нейронных сетей, состоящее из трех частей.
Первая часть, которая была опубликована в прошлом месяце в International Journal of Automation and Computing , посвящена ряду вычислений, которые могут выполнять сети с глубоким обучением, а также преимуществам глубоких сетей по сравнению с более мелкими. Вторая и третья части, которые были выпущены в качестве технических отчетов CBMM, посвящены проблемам глобальной оптимизации или гарантии того, что сеть нашла настройки, которые лучше всего соответствуют ее обучающим данным, и переобучения, или случаев, когда сеть становится такой настроенной. к особенностям своих обучающих данных, которые он не может обобщить на другие экземпляры тех же категорий.
к особенностям своих обучающих данных, которые он не может обобщить на другие экземпляры тех же категорий.
Есть еще много теоретических вопросов, на которые нужно ответить, но работа исследователей CBMM может помочь гарантировать, что нейронные сети, наконец, разорвут цикл поколений, который приводил к ним и терял популярность в течение семи десятилетий.
Что такое нейронные сети? | IBM
Думайте о каждом отдельном узле как о собственной модели линейной регрессии, состоящей из входных данных, весов, смещения (или порога) и выходных данных. Формула будет выглядеть примерно так:
∑wixi + смещение = w1x1 + w2x2 + w3x3 + смещение
вывод = f(x) = 1, если ∑w1x1 + b>= 0; 0, если ∑w1x1 + b < 0
После определения входного слоя ему присваиваются веса. Эти веса помогают определить важность той или иной переменной, при этом более крупные из них вносят более значительный вклад в результат по сравнению с другими входными данными. Затем все входные данные умножаются на их соответствующие веса, а затем суммируются.
Давайте разберем, как может выглядеть один единственный узел, используя двоичные значения. Мы можем применить эту концепцию к более осязаемому примеру, например, стоит ли вам заняться серфингом (Да: 1, Нет: 0). Решение идти или не идти — это наш прогнозируемый результат, или т-хэт. Предположим, что на ваше решение влияют три фактора:
- Волны хорошие? (Да: 1, Нет: 0)
- Состав пустой? (Да: 1, Нет: 0)
- Было ли в последнее время нападение акулы? (Да: 0, Нет: 1)
Тогда предположим следующее, дав нам следующие входные данные:
- X1 = 1, так как волны качают
- X2 = 0, так как толпы нет
- X3 = 1, так как в последнее время не было нападения акулы
Теперь нам нужно присвоить веса для определения важности. Большие веса означают, что конкретные переменные имеют большее значение для решения или результата.
Большие веса означают, что конкретные переменные имеют большее значение для решения или результата.
- W1 = 5, так как большие волны бывают не часто
- W2 = 2, так как вы привыкли к толпе
- W3 = 4, так как вы боитесь акул
Наконец, мы также примем пороговое значение равным 3, что соответствует значению смещения –3. Со всеми различными входными данными мы можем начать подставлять значения в формулу, чтобы получить желаемый результат.
Y-шляпа = (1*5) + (0*2) + (1*4) – 3 = 6
Если мы используем функцию активации из начала этого раздела, мы можем определить, что выход этого узел будет равен 1, так как 6 больше 0. В этом случае вы отправитесь в серфинг; но если мы скорректируем веса или порог, мы можем получить разные результаты от модели. Когда мы наблюдаем одно решение, как в приведенном выше примере, мы видим, как нейронная сеть может принимать все более сложные решения в зависимости от результатов предыдущих решений или слоев.
В приведенном выше примере мы использовали персептроны, чтобы проиллюстрировать некоторые математические операции, но нейронные сети используют сигмовидные нейроны, которые отличаются тем, что имеют значения от 0 до 1. Поскольку нейронные сети ведут себя аналогично деревьям решений, каскадирование данных из одного узла к другому, имея значения x от 0 до 1, уменьшит влияние любого заданного изменения одной переменной на вывод любого заданного узла, а затем и на вывод нейронной сети.
Когда мы начнем думать о более практических вариантах использования нейронных сетей, таких как распознавание изображений или классификация, мы будем использовать обучение с учителем или помеченные наборы данных для обучения алгоритма. По мере обучения модели мы хотим оценить ее точность с помощью функции затрат (или потерь). Это также обычно называют среднеквадратической ошибкой (MSE). В приведенном ниже уравнении 92
В конечном счете, цель состоит в том, чтобы минимизировать нашу функцию стоимости, чтобы гарантировать правильность подгонки для любого данного наблюдения. Поскольку модель корректирует свои веса и смещения, она использует функцию стоимости и обучение с подкреплением, чтобы достичь точки сходимости или локального минимума. Процесс, в котором алгоритм регулирует свои веса, представляет собой градиентный спуск, позволяющий модели определить направление, в котором нужно уменьшить ошибки (или минимизировать функцию стоимости). С каждым обучающим примером параметры модели корректируются, чтобы постепенно сходиться к минимуму.
Поскольку модель корректирует свои веса и смещения, она использует функцию стоимости и обучение с подкреплением, чтобы достичь точки сходимости или локального минимума. Процесс, в котором алгоритм регулирует свои веса, представляет собой градиентный спуск, позволяющий модели определить направление, в котором нужно уменьшить ошибки (или минимизировать функцию стоимости). С каждым обучающим примером параметры модели корректируются, чтобы постепенно сходиться к минимуму.
Подробное объяснение количественных понятий, связанных с нейронными сетями, см. в этой статье IBM Developer.
Большинство глубоких нейронных сетей имеют прямую связь, то есть они работают только в одном направлении, от входа к выходу. Однако вы также можете обучить свою модель с помощью обратного распространения; то есть двигаться в противоположном направлении от выхода к входу. Обратное распространение позволяет нам рассчитать и атрибутировать ошибку, связанную с каждым нейроном, что позволяет нам соответствующим образом настроить и подогнать параметры модели (моделей).